DiffTF++: 3D-aware Diffusion Transformer for Large-Vocabulary 3D Generation
2405.08055
0
0

Abstract
Generating diverse and high-quality 3D assets automatically poses a fundamental yet challenging task in 3D computer vision. Despite extensive efforts in 3D generation, existing optimization-based approaches struggle to produce large-scale 3D assets efficiently. Meanwhile, feed-forward methods often focus on generating only a single category or a few categories, limiting their generalizability. Therefore, we introduce a diffusion-based feed-forward framework to address these challenges with a single model. To handle the large diversity and complexity in geometry and texture across categories efficiently, we 1) adopt improved triplane to guarantee efficiency; 2) introduce the 3D-aware transformer to aggregate the generalized 3D knowledge with specialized 3D features; and 3) devise the 3D-aware encoder/decoder to enhance the generalized 3D knowledge. Building upon our 3D-aware Diffusion model with TransFormer, DiffTF, we propose a stronger version for 3D generation, i.e., DiffTF++. It boils down to two parts: multi-view reconstruction loss and triplane refinement. Specifically, we utilize multi-view reconstruction loss to fine-tune the diffusion model and triplane decoder, thereby avoiding the negative influence caused by reconstruction errors and improving texture synthesis. By eliminating the mismatch between the two stages, the generative performance is enhanced, especially in texture. Additionally, a 3D-aware refinement process is introduced to filter out artifacts and refine triplanes, resulting in the generation of more intricate and reasonable details. Extensive experiments on ShapeNet and OmniObject3D convincingly demonstrate the effectiveness of our proposed modules and the state-of-the-art 3D object generation performance with large diversity, rich semantics, and high quality.
Create account to get full access
Overview
- This paper presents DiffTF++, a 3D-aware diffusion transformer model for generating large-vocabulary 3D objects.
- The model aims to address the challenge of generating diverse and high-quality 3D content by leveraging the capabilities of diffusion models and transformers.
- The key innovations include incorporating 3D awareness into the model architecture and training process, as well as enabling generation of a wide range of 3D objects.
Plain English Explanation
The research paper introduces a new AI model called DiffTF++ that can create a wide variety of 3D objects. This is an important task because being able to generate diverse and high-quality 3D content has many applications, such as in video games, virtual reality, and product design.
The model works by combining two powerful AI techniques: diffusion models and transformers. Diffusion models are a type of generative AI that can create new images, 3D objects, or other content by gradually adding noise to an input and then reversing the process to generate something new. Transformers are a type of neural network that can process and understand language very well.
The key innovation in DiffTF++ is that it incorporates "3D awareness" into the model, meaning it has a deeper understanding of the 3D world and can leverage that to generate more realistic and varied 3D objects. The model is also trained on a large vocabulary of 3D shapes, allowing it to create a wide range of different objects, going beyond just simple geometric primitives.
Technical Explanation
The DiffTF++ model builds on previous work in DiffusionGAN3D, VolumeDiffusion, and MVDiff, which have explored the use of diffusion models for 3D generation. However, DiffTF++ goes further by incorporating transformer-based techniques to better capture the rich diversity of 3D shapes.
The model architecture includes a 3D encoder that learns a latent representation of the input 3D data, and a transformer-based diffusion model that generates new 3D content by iteratively denoising a latent representation. Crucially, the model is trained on a large dataset of 3D shapes, spanning a wide vocabulary of object categories, allowing it to generate a diverse range of 3D content.
The researchers evaluate DiffTF++ on several 3D generation benchmarks, demonstrating its ability to outperform previous state-of-the-art approaches in terms of both quality and diversity of the generated 3D objects. They also show how the model can be conditioned on text descriptions to generate 3D objects that match the given prompts, as explored in Grounded Compositional and DiffusionDollar2Dollar.
Critical Analysis
The DiffTF++ model represents an important advancement in the field of 3D generative AI, addressing the key challenge of generating diverse and high-quality 3D content at scale. By leveraging the complementary strengths of diffusion models and transformers, the researchers have created a powerful system that can generate a wide variety of 3D shapes.
One potential limitation of the approach is that it may still struggle with generating highly complex or unconventional 3D shapes, as the training data is necessarily limited. Additionally, the computational resources required to train and run the model may be significant, which could limit its accessibility and real-world deployment.
Further research could explore ways to make the model more efficient, potentially by incorporating techniques like model compression or knowledge distillation. Investigations into the model's ability to generalize to novel 3D object categories, or to generate 3D content conditioned on richer multimodal inputs, could also be fruitful avenues for future work.
Conclusion
The DiffTF++ model represents a significant advancement in the field of 3D generative AI, demonstrating the power of combining diffusion models and transformers to create diverse and high-quality 3D content. By incorporating 3D awareness and leveraging a large vocabulary of 3D shapes, the model opens up new possibilities for applications in areas like virtual reality, product design, and content creation. While there are still some limitations to be addressed, the research presented in this paper is an important step forward in the quest to enable more accessible and versatile 3D generation capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Direct3D: Scalable Image-to-3D Generation via 3D Latent Diffusion Transformer
Shuang Wu, Youtian Lin, Feihu Zhang, Yifei Zeng, Jingxi Xu, Philip Torr, Xun Cao, Yao Yao
0
0
Generating high-quality 3D assets from text and images has long been challenging, primarily due to the absence of scalable 3D representations capable of capturing intricate geometry distributions. In this work, we introduce Direct3D, a native 3D generative model scalable to in-the-wild input images, without requiring a multiview diffusion model or SDS optimization. Our approach comprises two primary components: a Direct 3D Variational Auto-Encoder (D3D-VAE) and a Direct 3D Diffusion Transformer (D3D-DiT). D3D-VAE efficiently encodes high-resolution 3D shapes into a compact and continuous latent triplane space. Notably, our method directly supervises the decoded geometry using a semi-continuous surface sampling strategy, diverging from previous methods relying on rendered images as supervision signals. D3D-DiT models the distribution of encoded 3D latents and is specifically designed to fuse positional information from the three feature maps of the triplane latent, enabling a native 3D generative model scalable to large-scale 3D datasets. Additionally, we introduce an innovative image-to-3D generation pipeline incorporating semantic and pixel-level image conditions, allowing the model to produce 3D shapes consistent with the provided conditional image input. Extensive experiments demonstrate the superiority of our large-scale pre-trained Direct3D over previous image-to-3D approaches, achieving significantly better generation quality and generalization ability, thus establishing a new state-of-the-art for 3D content creation. Project page: https://nju-3dv.github.io/projects/Direct3D/.
6/4/2024
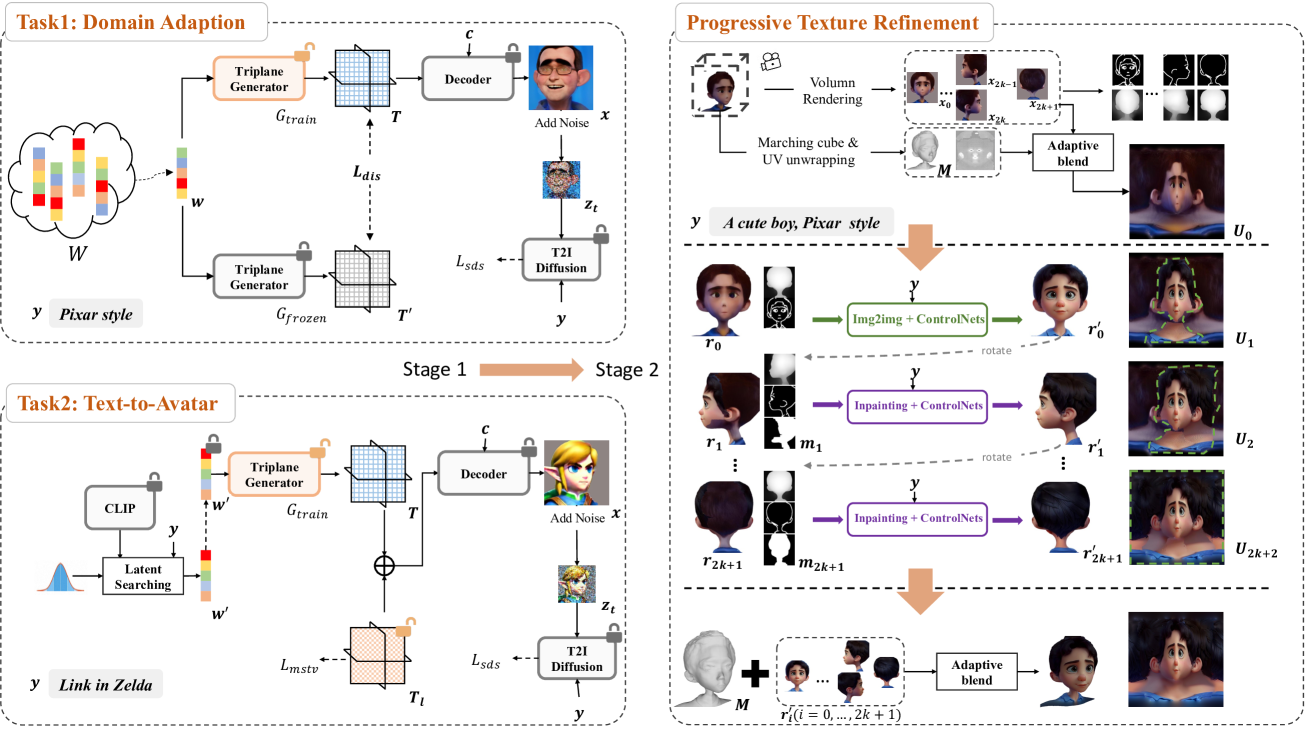
DiffusionGAN3D: Boosting Text-guided 3D Generation and Domain Adaptation by Combining 3D GANs and Diffusion Priors
Biwen Lei, Kai Yu, Mengyang Feng, Miaomiao Cui, Xuansong Xie
0
0
Text-guided domain adaptation and generation of 3D-aware portraits find many applications in various fields. However, due to the lack of training data and the challenges in handling the high variety of geometry and appearance, the existing methods for these tasks suffer from issues like inflexibility, instability, and low fidelity. In this paper, we propose a novel framework DiffusionGAN3D, which boosts text-guided 3D domain adaptation and generation by combining 3D GANs and diffusion priors. Specifically, we integrate the pre-trained 3D generative models (e.g., EG3D) and text-to-image diffusion models. The former provides a strong foundation for stable and high-quality avatar generation from text. And the diffusion models in turn offer powerful priors and guide the 3D generator finetuning with informative direction to achieve flexible and efficient text-guided domain adaptation. To enhance the diversity in domain adaptation and the generation capability in text-to-avatar, we introduce the relative distance loss and case-specific learnable triplane respectively. Besides, we design a progressive texture refinement module to improve the texture quality for both tasks above. Extensive experiments demonstrate that the proposed framework achieves excellent results in both domain adaptation and text-to-avatar tasks, outperforming existing methods in terms of generation quality and efficiency. The project homepage is at https://younglbw.github.io/DiffusionGAN3D-homepage/.
4/15/2024
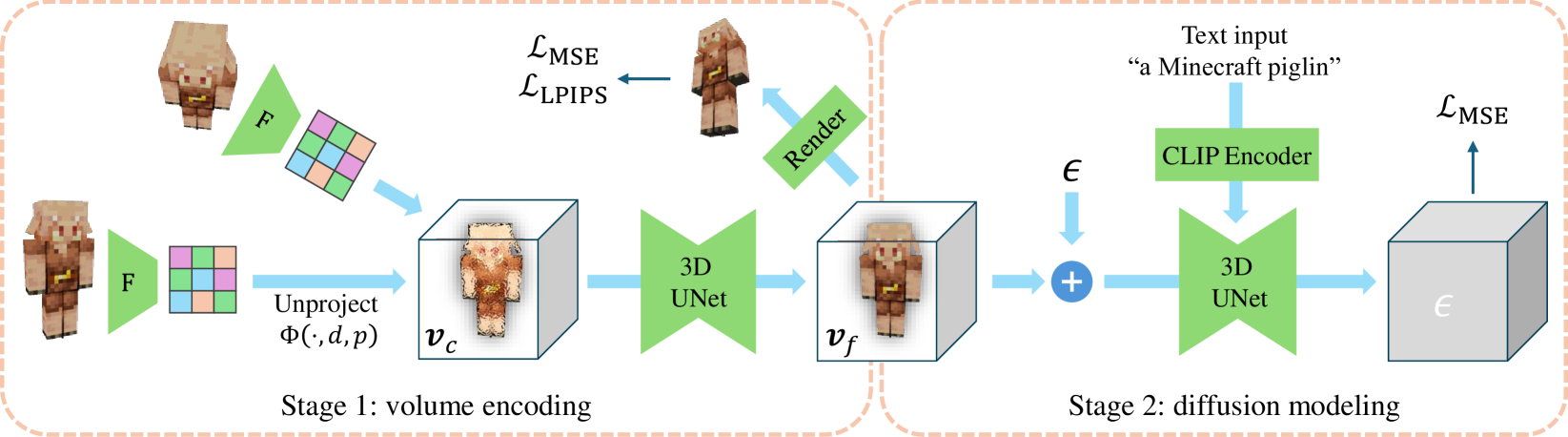
VolumeDiffusion: Flexible Text-to-3D Generation with Efficient Volumetric Encoder
Zhicong Tang, Shuyang Gu, Chunyu Wang, Ting Zhang, Jianmin Bao, Dong Chen, Baining Guo
0
0
This paper introduces a pioneering 3D volumetric encoder designed for text-to-3D generation. To scale up the training data for the diffusion model, a lightweight network is developed to efficiently acquire feature volumes from multi-view images. The 3D volumes are then trained on a diffusion model for text-to-3D generation using a 3D U-Net. This research further addresses the challenges of inaccurate object captions and high-dimensional feature volumes. The proposed model, trained on the public Objaverse dataset, demonstrates promising outcomes in producing diverse and recognizable samples from text prompts. Notably, it empowers finer control over object part characteristics through textual cues, fostering model creativity by seamlessly combining multiple concepts within a single object. This research significantly contributes to the progress of 3D generation by introducing an efficient, flexible, and scalable representation methodology. Code is available at https://github.com/checkcrab/VolumeDiffusion.
4/30/2024

MVDiff: Scalable and Flexible Multi-View Diffusion for 3D Object Reconstruction from Single-View
Emmanuelle Bourigault, Pauline Bourigault
0
0
Generating consistent multiple views for 3D reconstruction tasks is still a challenge to existing image-to-3D diffusion models. Generally, incorporating 3D representations into diffusion model decrease the model's speed as well as generalizability and quality. This paper proposes a general framework to generate consistent multi-view images from single image or leveraging scene representation transformer and view-conditioned diffusion model. In the model, we introduce epipolar geometry constraints and multi-view attention to enforce 3D consistency. From as few as one image input, our model is able to generate 3D meshes surpassing baselines methods in evaluation metrics, including PSNR, SSIM and LPIPS.
6/14/2024