Diffusion Time-step Curriculum for One Image to 3D Generation
2404.04562
0
0
Abstract
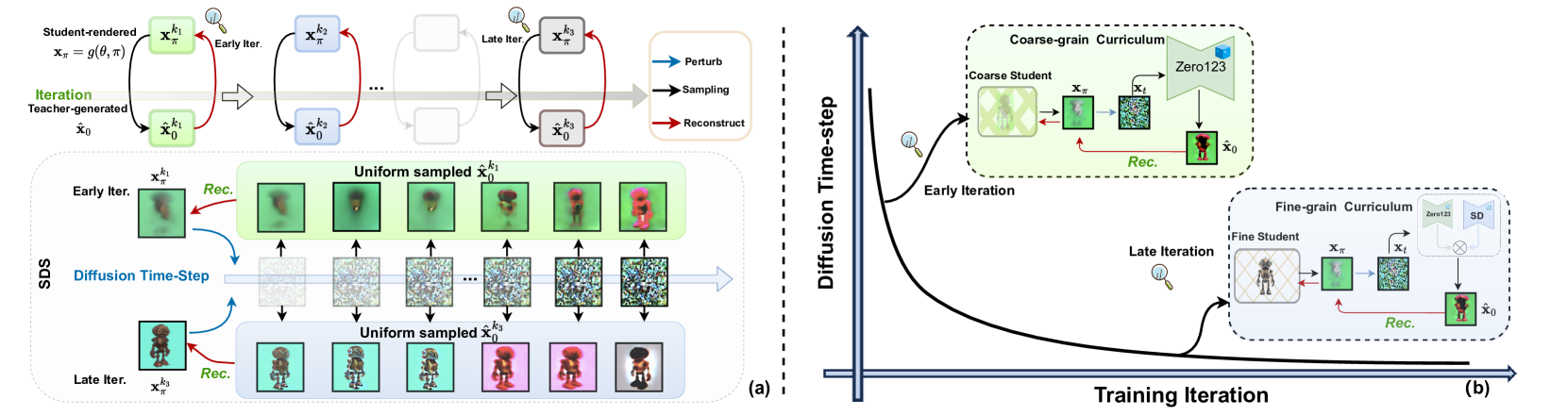
Score distillation sampling~(SDS) has been widely adopted to overcome the absence of unseen views in reconstructing 3D objects from a textbf{single} image. It leverages pre-trained 2D diffusion models as teacher to guide the reconstruction of student 3D models. Despite their remarkable success, SDS-based methods often encounter geometric artifacts and texture saturation. We find out the crux is the overlooked indiscriminate treatment of diffusion time-steps during optimization: it unreasonably treats the student-teacher knowledge distillation to be equal at all time-steps and thus entangles coarse-grained and fine-grained modeling. Therefore, we propose the Diffusion Time-step Curriculum one-image-to-3D pipeline (DTC123), which involves both the teacher and student models collaborating with the time-step curriculum in a coarse-to-fine manner. Extensive experiments on NeRF4, RealFusion15, GSO and Level50 benchmark demonstrate that DTC123 can produce multi-view consistent, high-quality, and diverse 3D assets. Codes and more generation demos will be released in https://github.com/yxymessi/DTC123.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a novel approach to generate 3D content from a single input image using diffusion models.
- The key innovation is a "diffusion time-step curriculum" that progressively increases the number of diffusion steps during training, allowing the model to first focus on coarse details and gradually refine the 3D output.
- The authors demonstrate that this curriculum-based training leads to higher-quality 3D reconstructions compared to prior diffusion-based methods.
Plain English Explanation
The researchers have developed a new way to create 3D models from 2D images using a type of AI called a diffusion model. Diffusion models work by gradually adding "noise" to an image, then learning how to "denoise" it to reconstruct the original.
The key insight in this paper is to train the diffusion model using a curriculum - starting with a small number of denoising steps, then gradually increasing the number of steps as training progresses. This allows the model to first focus on the broad, coarse shapes, then refine the details over time.
This curriculum-based approach leads to more accurate and realistic 3D models compared to prior diffusion-based methods that didn't use this gradual training strategy. It's like teaching a child to draw - you start with simple shapes, then gradually add more complexity as they improve.
The authors demonstrate their technique on a variety of 2D images, showing that it can generate high-quality 3D content that faithfully captures the structure of the original scene. This could be useful for applications like 3D content creation, virtual reality, and even robotics.
Technical Explanation
The paper introduces a "diffusion time-step curriculum" for training diffusion models to generate 3D content from a single 2D input image. Diffusion models work by gradually adding noise to an image, then learning to reverse this process to reconstruct the original.
The key innovation is to progressively increase the number of diffusion steps during training. Initially, the model is trained with a small number of denoising steps, allowing it to focus on capturing the coarse, global structure of the 3D shape. Over subsequent training iterations, the number of steps is increased, enabling the model to gradually refine the details.
The authors demonstrate that this curriculum-based approach outperforms prior diffusion-based methods for 3D generation [<a href="https://aimodels.fyi/papers/arxiv/diffusiondollar2dollar-dynamic-3d-content-generation-via-score">1</a>, <a href="https://aimodels.fyi/papers/arxiv/generating-images-3d-annotations-using-diffusion-models">2</a>, <a href="https://aimodels.fyi/papers/arxiv/diffusion-3d-features-diff3f-decorating-untextured-shapes">3</a>] on a variety of benchmarks. They attribute this improvement to the model's ability to first focus on the overall structure before refining the details.
The paper also includes experiments exploring the impact of the curriculum schedule, as well as a novel "score identity distillation" technique [<a href="https://aimodels.fyi/papers/arxiv/score-identity-distillation-exponentially-fast-distillation-pretrained">4</a>] to further enhance the model's performance.
Critical Analysis
The proposed diffusion time-step curriculum is a clever and well-designed technique that addresses a key limitation of prior diffusion-based 3D generation methods. By gradually increasing the complexity of the denoising task, the model is able to learn more effective representations for capturing the 3D structure of the input image.
However, the paper does not explore the broader applicability of this curriculum-based approach. It would be interesting to see if similar techniques could be applied to other generative tasks, such as 2D image synthesis or text generation. Additionally, the authors could have delved deeper into the underlying reasons why the curriculum-based training leads to better 3D reconstructions, potentially providing insights that could inform the design of future diffusion models.
Another potential area for further research is the interaction between the curriculum schedule and the 3D reconstruction quality. The authors explore a few different schedules, but a more systematic exploration of this design choice could yield additional performance improvements.
Overall, this paper represents an important advancement in diffusion-based 3D generation and serves as a valuable contribution to the field of generative modeling. The authors' insights and techniques could inspire further innovations in this area.
Conclusion
This paper introduces a novel diffusion time-step curriculum for training diffusion models to generate 3D content from a single 2D input image. By gradually increasing the complexity of the denoising task during training, the model is able to focus first on the coarse, global structure of the 3D shape before refining the details.
The authors demonstrate that this curriculum-based approach outperforms prior diffusion-based methods for 3D generation, leading to higher-quality 3D reconstructions. This work represents an important advancement in the field of generative modeling and could have significant implications for applications such as 3D content creation, virtual reality, and robotics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
DreamTime: An Improved Optimization Strategy for Diffusion-Guided 3D Generation
Yukun Huang, Jianan Wang, Yukai Shi, Boshi Tang, Xianbiao Qi, Lei Zhang
0
0
Text-to-image diffusion models pre-trained on billions of image-text pairs have recently enabled 3D content creation by optimizing a randomly initialized differentiable 3D representation with score distillation. However, the optimization process suffers slow convergence and the resultant 3D models often exhibit two limitations: (a) quality concerns such as missing attributes and distorted shape and texture; (b) extremely low diversity comparing to text-guided image synthesis. In this paper, we show that the conflict between the 3D optimization process and uniform timestep sampling in score distillation is the main reason for these limitations. To resolve this conflict, we propose to prioritize timestep sampling with monotonically non-increasing functions, which aligns the 3D optimization process with the sampling process of diffusion model. Extensive experiments show that our simple redesign significantly improves 3D content creation with faster convergence, better quality and diversity.
5/7/2024

Diffusion$^2$: Dynamic 3D Content Generation via Score Composition of Orthogonal Diffusion Models
Zeyu Yang, Zijie Pan, Chun Gu, Li Zhang
0
0
Recent advancements in 3D generation are predominantly propelled by improvements in 3D-aware image diffusion models which are pretrained on Internet-scale image data and fine-tuned on massive 3D data, offering the capability of producing highly consistent multi-view images. However, due to the scarcity of synchronized multi-view video data, it is impractical to adapt this paradigm to 4D generation directly. Despite that, the available video and 3D data are adequate for training video and multi-view diffusion models that can provide satisfactory dynamic and geometric priors respectively. In this paper, we present Diffusion$^2$, a novel framework for dynamic 3D content creation that leverages the knowledge about geometric consistency and temporal smoothness from these models to directly sample dense multi-view and multi-frame images which can be employed to optimize continuous 4D representation. Specifically, we design a simple yet effective denoising strategy via score composition of video and multi-view diffusion models based on the probability structure of the images to be generated. Owing to the high parallelism of the image generation and the efficiency of the modern 4D reconstruction pipeline, our framework can generate 4D content within few minutes. Furthermore, our method circumvents the reliance on 4D data, thereby having the potential to benefit from the scalability of the foundation video and multi-view diffusion models. Extensive experiments demonstrate the efficacy of our proposed framework and its capability to flexibly adapt to various types of prompts.
4/23/2024
📈
Grounded Compositional and Diverse Text-to-3D with Pretrained Multi-View Diffusion Model
Xiaolong Li, Jiawei Mo, Ying Wang, Chethan Parameshwara, Xiaohan Fei, Ashwin Swaminathan, CJ Taylor, Zhuowen Tu, Paolo Favaro, Stefano Soatto
0
0
In this paper, we propose an effective two-stage approach named Grounded-Dreamer to generate 3D assets that can accurately follow complex, compositional text prompts while achieving high fidelity by using a pre-trained multi-view diffusion model. Multi-view diffusion models, such as MVDream, have shown to generate high-fidelity 3D assets using score distillation sampling (SDS). However, applied naively, these methods often fail to comprehend compositional text prompts, and may often entirely omit certain subjects or parts. To address this issue, we first advocate leveraging text-guided 4-view images as the bottleneck in the text-to-3D pipeline. We then introduce an attention refocusing mechanism to encourage text-aligned 4-view image generation, without the necessity to re-train the multi-view diffusion model or craft a high-quality compositional 3D dataset. We further propose a hybrid optimization strategy to encourage synergy between the SDS loss and the sparse RGB reference images. Our method consistently outperforms previous state-of-the-art (SOTA) methods in generating compositional 3D assets, excelling in both quality and accuracy, and enabling diverse 3D from the same text prompt.
4/30/2024

MVDiff: Scalable and Flexible Multi-View Diffusion for 3D Object Reconstruction from Single-View
Emmanuelle Bourigault, Pauline Bourigault
0
0
Generating consistent multiple views for 3D reconstruction tasks is still a challenge to existing image-to-3D diffusion models. Generally, incorporating 3D representations into diffusion model decrease the model's speed as well as generalizability and quality. This paper proposes a general framework to generate consistent multi-view images from single image or leveraging scene representation transformer and view-conditioned diffusion model. In the model, we introduce epipolar geometry constraints and multi-view attention to enforce 3D consistency. From as few as one image input, our model is able to generate 3D meshes surpassing baselines methods in evaluation metrics, including PSNR, SSIM and LPIPS.
5/8/2024