Direct Preference Optimization of Video Large Multimodal Models from Language Model Reward
2404.01258
0
0
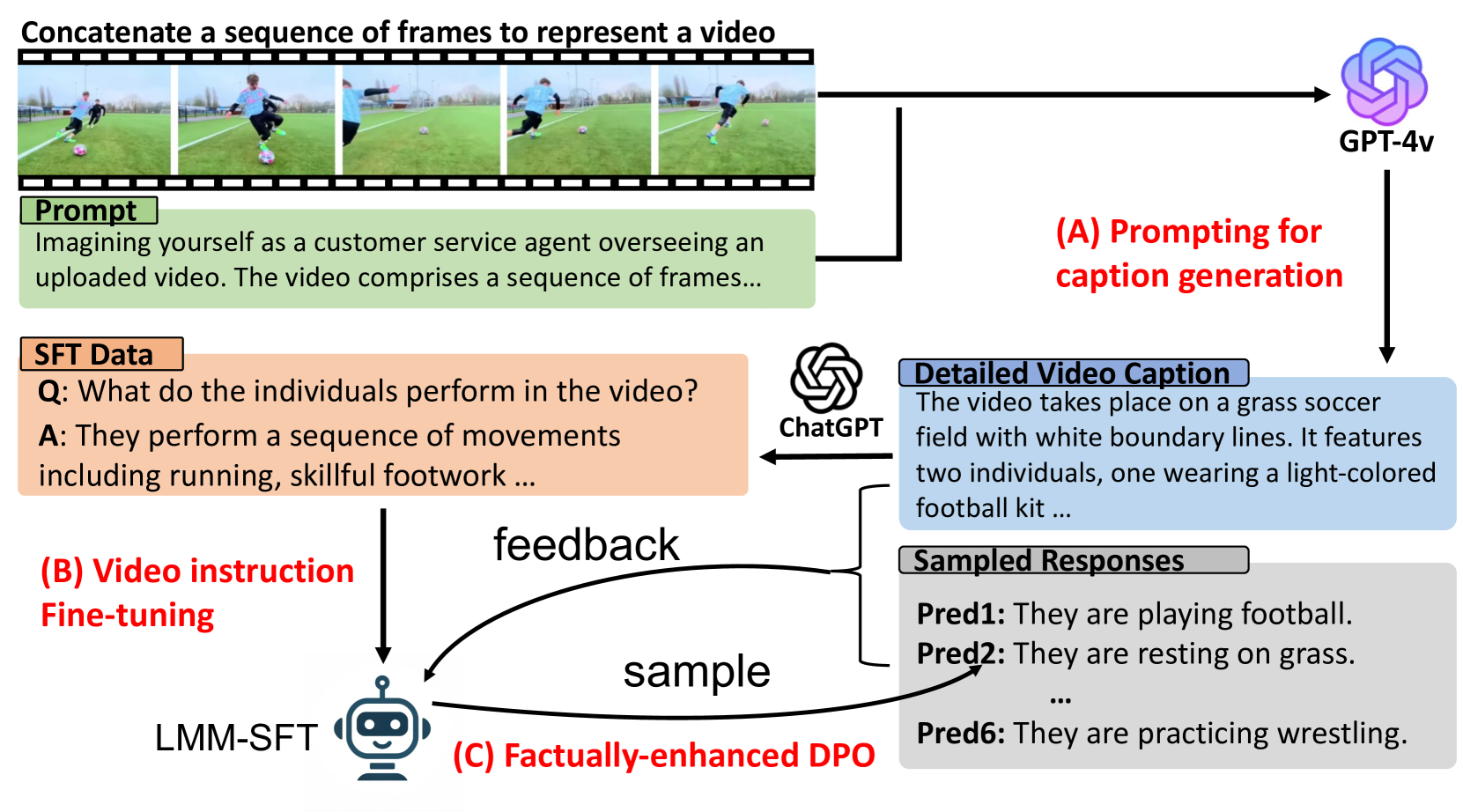
Abstract
Preference modeling techniques, such as direct preference optimization (DPO), has shown effective in enhancing the generalization abilities of large language model (LLM). However, in tasks involving video instruction-following, providing informative feedback, especially for detecting hallucinations in generated responses, remains a significant challenge. Previous studies have explored using large large multimodal models (LMMs) as reward models to guide preference modeling, but their ability to accurately assess the factuality of generated responses compared to corresponding videos has not been conclusively established. This paper introduces a novel framework that utilizes detailed video captions as a proxy of video content, enabling language models to incorporate this information as supporting evidence for scoring video Question Answering (QA) predictions. Our approach demonstrates robust alignment with OpenAI GPT-4V model's reward mechanism, which directly takes video frames as input. Furthermore, we show that applying this tailored reward through DPO significantly improves the performance of video LMMs on video QA tasks.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the optimization of large multimodal video models using language model rewards.
- The researchers propose a direct preference optimization approach to fine-tune these models, aiming to improve their performance on downstream tasks.
- The work highlights the potential benefits of leveraging language model rewards to enhance the capabilities of video understanding systems.
Plain English Explanation
The paper discusses a new way to train large AI models that can work with both images and text, known as "multimodal" models. These models are designed to understand and process video data, which includes both visual and textual information.
The researchers found that by using the feedback or "rewards" from language models (AI systems trained on a vast amount of text data), they could fine-tune the multimodal video models to perform better on various tasks. This approach, called "direct preference optimization," allows the models to learn from the language model's understanding of language and meaning, rather than just relying on the video data alone.
The key idea is that the language model's knowledge can help the video model make better sense of the content it's processing, leading to improved performance on real-world applications like video understanding, captioning, and analysis. This could have important implications for fields like video surveillance, content moderation, and multimedia search and retrieval.
Technical Explanation
The paper proposes a method for directly optimizing the preferences of large multimodal video models using language model rewards. The researchers start by pre-training a multimodal video model on a large dataset of video and text data. They then fine-tune this model using a direct preference optimization approach, where the model's parameters are updated to maximize the rewards from a separate language model.
The language model is used as a proxy for human preferences, providing a richer and more nuanced feedback signal than traditional supervised learning approaches. The authors demonstrate the effectiveness of this approach through experiments on various video understanding tasks, showing improved performance compared to baseline fine-tuning methods.
The paper also explores the role of the language model's architecture and training data in shaping the optimization process and the final model's capabilities. The findings suggest that the direct preference optimization technique can help leverage the rich semantic knowledge captured by language models to enhance the performance of large-scale video understanding systems.
Critical Analysis
The paper presents a compelling approach for improving the performance of large multimodal video models, but it also acknowledges several limitations and avenues for future research.
One key concern is the reliance on the language model's understanding of human preferences, which may not always align with the actual preferences of end-users or specific application domains. The authors suggest exploring alternative reward functions or multi-stakeholder preferences to address this issue.
Additionally, the paper does not delve into the potential biases or limitations of the language model itself, which could be transferred to the fine-tuned video model. Investigating the ethical and societal implications of this approach would be an important area for further study.
The paper also highlights the computational and memory-intensive nature of the direct preference optimization process, which may limit its scalability or applicability in resource-constrained settings. Exploring more efficient optimization techniques or model architectures could help address these challenges.
Overall, the paper makes a valuable contribution to the field of multimodal learning, demonstrating the potential benefits of leveraging language model rewards for enhancing video understanding capabilities. However, further research is needed to address the potential limitations and ensure the responsible development of these advanced AI systems.
Conclusion
This paper presents a novel approach for optimizing the performance of large multimodal video models by leveraging language model rewards. The direct preference optimization technique allows these models to learn from the rich semantic knowledge captured by language models, leading to improved performance on various video understanding tasks.
While the paper highlights the potential benefits of this approach, it also acknowledges several limitations and areas for future research, such as the need to address potential biases, explore alternative reward functions, and improve the computational efficiency of the optimization process.
Overall, the work contributes to the ongoing efforts to develop more capable and versatile AI systems for multimedia analysis and understanding, with implications for a wide range of applications in fields like video surveillance, content moderation, and multimedia search and retrieval.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
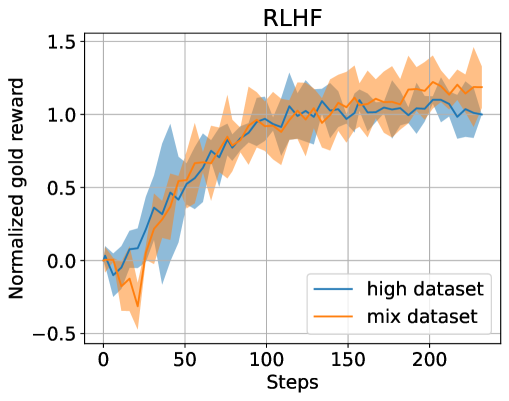
Filtered Direct Preference Optimization
Tetsuro Morimura, Mitsuki Sakamoto, Yuu Jinnai, Kenshi Abe, Kaito Ariu
0
0
Reinforcement learning from human feedback (RLHF) plays a crucial role in aligning language models with human preferences. While the significance of dataset quality is generally recognized, explicit investigations into its impact within the RLHF framework, to our knowledge, have been limited. This paper addresses the issue of text quality within the preference dataset by focusing on Direct Preference Optimization (DPO), an increasingly adopted reward-model-free RLHF method. We confirm that text quality significantly influences the performance of models optimized with DPO more than those optimized with reward-model-based RLHF. Building on this new insight, we propose an extension of DPO, termed filtered direct preference optimization (fDPO). fDPO uses a trained reward model to monitor the quality of texts within the preference dataset during DPO training. Samples of lower quality are discarded based on comparisons with texts generated by the model being optimized, resulting in a more accurate dataset. Experimental results demonstrate that fDPO enhances the final model performance. Our code is available at https://github.com/CyberAgentAILab/filtered-dpo.
4/24/2024
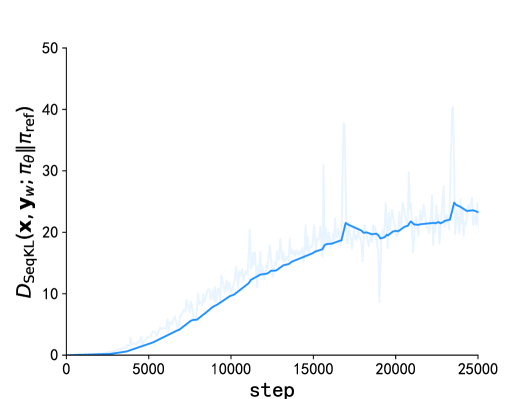
Token-level Direct Preference Optimization
Yongcheng Zeng, Guoqing Liu, Weiyu Ma, Ning Yang, Haifeng Zhang, Jun Wang
0
0
Fine-tuning pre-trained Large Language Models (LLMs) is essential to align them with human values and intentions. This process often utilizes methods like pairwise comparisons and KL divergence against a reference LLM, focusing on the evaluation of full answers generated by the models. However, the generation of these responses occurs in a token level, following a sequential, auto-regressive fashion. In this paper, we introduce Token-level Direct Preference Optimization (TDPO), a novel approach to align LLMs with human preferences by optimizing policy at the token level. Unlike previous methods, which face challenges in divergence efficiency, TDPO incorporates forward KL divergence constraints for each token, improving alignment and diversity. Utilizing the Bradley-Terry model for a token-based reward system, TDPO enhances the regulation of KL divergence, while preserving simplicity without the need for explicit reward modeling. Experimental results across various text tasks demonstrate TDPO's superior performance in balancing alignment with generation diversity. Notably, fine-tuning with TDPO strikes a better balance than DPO in the controlled sentiment generation and single-turn dialogue datasets, and significantly improves the quality of generated responses compared to both DPO and PPO-based RLHF methods. Our code is open-sourced at https://github.com/Vance0124/Token-level-Direct-Preference-Optimization.
4/19/2024

From $r$ to $Q^*$: Your Language Model is Secretly a Q-Function
Rafael Rafailov, Joey Hejna, Ryan Park, Chelsea Finn
0
0
Reinforcement Learning From Human Feedback (RLHF) has been a critical to the success of the latest generation of generative AI models. In response to the complex nature of the classical RLHF pipeline, direct alignment algorithms such as Direct Preference Optimization (DPO) have emerged as an alternative approach. Although DPO solves the same objective as the standard RLHF setup, there is a mismatch between the two approaches. Standard RLHF deploys reinforcement learning in a specific token-level MDP, while DPO is derived as a bandit problem in which the whole response of the model is treated as a single arm. In this work we rectify this difference, first we theoretically show that we can derive DPO in the token-level MDP as a general inverse Q-learning algorithm, which satisfies the Bellman equation. Using our theoretical results, we provide three concrete empirical insights. First, we show that because of its token level interpretation, DPO is able to perform some type of credit assignment. Next, we prove that under the token level formulation, classical search-based algorithms, such as MCTS, which have recently been applied to the language generation space, are equivalent to likelihood-based search on a DPO policy. Empirically we show that a simple beam search yields meaningful improvement over the base DPO policy. Finally, we show how the choice of reference policy causes implicit rewards to decline during training. We conclude by discussing applications of our work, including information elicitation in multi-tun dialogue, reasoning, agentic applications and end-to-end training of multi-model systems.
4/19/2024
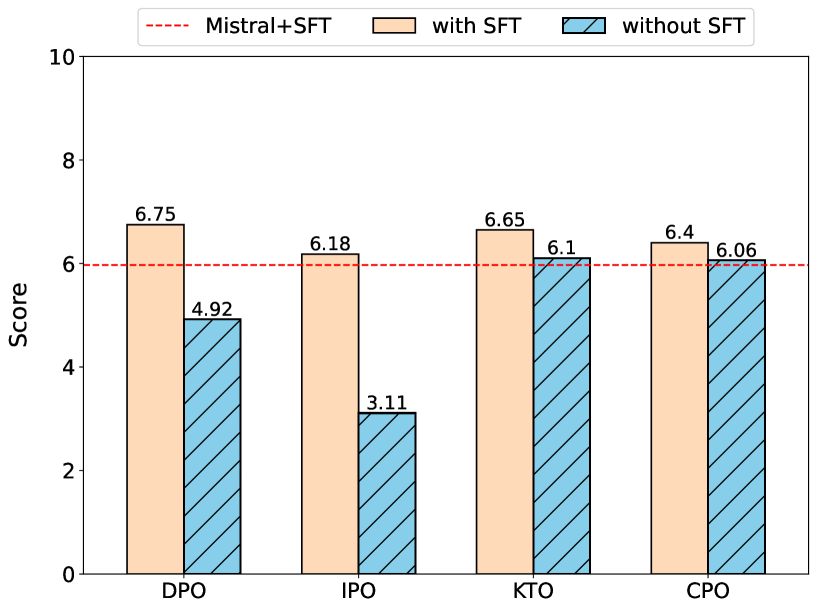
Insights into Alignment: Evaluating DPO and its Variants Across Multiple Tasks
Amir Saeidi, Shivanshu Verma, Chitta Baral
0
0
Large Language Models (LLMs) have demonstrated remarkable performance across a spectrum of tasks. Recently, Direct Preference Optimization (DPO) has emerged as an RL-free approach to optimize the policy model on human preferences. However, several limitations hinder the widespread adoption of this method. To address these shortcomings, various versions of DPO have been introduced. Yet, a comprehensive evaluation of these variants across diverse tasks is still lacking. In this study, we aim to bridge this gap by investigating the performance of alignment methods across three distinct scenarios: (1) keeping the Supervised Fine-Tuning (SFT) part, (2) skipping the SFT part, and (3) skipping the SFT part and utilizing an instruction-tuned model. Furthermore, we explore the impact of different training sizes on their performance. Our evaluation spans a range of tasks including dialogue systems, reasoning, mathematical problem-solving, question answering, truthfulness, and multi-task understanding, encompassing 13 benchmarks such as MT-Bench, Big Bench, and Open LLM Leaderboard. Key observations reveal that alignment methods achieve optimal performance with smaller training data subsets, exhibit limited effectiveness in reasoning tasks yet significantly impact mathematical problem-solving, and employing an instruction-tuned model notably influences truthfulness. We anticipate that our findings will catalyze further research aimed at developing more robust models to address alignment challenges.
4/24/2024