DispaRisk: Assessing and Interpreting Disparity Risks in Datasets
2405.12372
0
0
🔗
Abstract
Machine Learning algorithms (ML) impact virtually every aspect of human lives and have found use across diverse sectors, including healthcare, finance, and education. Often, ML algorithms have been found to exacerbate societal biases presented in datasets, leading to adversarial impacts on subsets/groups of individuals, in many cases minority groups. To effectively mitigate these untoward effects, it is crucial that disparities/biases are identified and assessed early in a ML pipeline. This proactive approach facilitates timely interventions to prevent bias amplification and reduce complexity at later stages of model development. In this paper, we introduce DispaRisk, a novel framework designed to proactively assess the potential risks of disparities in datasets during the initial stages of the ML pipeline. We evaluate DispaRisk's effectiveness by benchmarking it with commonly used datasets in fairness research. Our findings demonstrate the capabilities of DispaRisk to identify datasets with a high-risk of discrimination, model families prone to biases, and characteristics that heighten discrimination susceptibility in a ML pipeline. The code for our experiments is available in the following repository: https://github.com/jovasque156/disparisk
Create account to get full access
Overview
- Machine Learning (ML) algorithms are used in diverse sectors, including healthcare, finance, and education.
- These algorithms can sometimes amplify societal biases present in the data used to train them, leading to adverse impacts on certain groups, often minorities.
- Proactively identifying and assessing these disparities early in the ML pipeline is crucial to mitigate their effects and prevent bias amplification.
Plain English Explanation
Machine learning algorithms are computer programs that can learn from data and make predictions or decisions without being explicitly programmed. These algorithms are used in many different areas of our lives, like healthcare, finance, and education.
However, sometimes the data used to train these algorithms can contain biases that already exist in society. This means the algorithms may end up making decisions or predictions that are unfairly biased against certain groups of people, often minorities or other marginalized groups.
To prevent this from happening, it's important to identify and understand these biases early on in the process of developing the machine learning algorithms. This allows for steps to be taken to address the biases and make the algorithms fairer and more equitable. Doing this upfront is better than trying to fix the issues later on, which can be much more complex and difficult.
Technical Explanation
The paper introduces a new framework called DispaRisk, which is designed to proactively assess the potential risks of disparities in datasets during the initial stages of the machine learning pipeline. The researchers evaluated DispaRisk by testing it on commonly used datasets in fairness research.
Their findings show that DispaRisk is effective at identifying datasets with a high risk of discrimination, as well as machine learning model families that are prone to biases and characteristics that make algorithms more susceptible to discrimination. This allows for earlier intervention to address these issues and prevent the amplification of biases as the machine learning models are developed.
The code for the experiments conducted in this research is available in the provided GitHub repository.
Critical Analysis
The paper provides a valuable contribution by introducing a framework to proactively identify biases in machine learning datasets and models. This is an important step in addressing the complex challenge of ensuring fairness and equity in the deployment of these algorithms.
However, the paper does not delve into the potential limitations or caveats of the DispaRisk framework. For example, it would be helpful to understand how the framework performs on more diverse or heterogeneous datasets, or how it may need to be adapted for different application domains.
Additionally, the paper could have addressed potential concerns around the interpretability and explainability of the biases identified by DispaRisk. Understanding the root causes of biases is crucial for developing effective mitigation strategies.
Overall, the research presented in this paper represents a step forward in the field of fair and ethical AI, but there is still more work to be done to fully address the challenges of bias and discrimination in machine learning.
Conclusion
This paper introduces DispaRisk, a novel framework designed to proactively assess the potential risks of disparities in datasets during the initial stages of machine learning pipelines. The researchers' findings demonstrate the capabilities of DispaRisk in identifying high-risk datasets, biased model families, and characteristics that heighten discrimination susceptibility.
By addressing these issues early on, the framework aims to facilitate timely interventions and prevent the amplification of biases, ultimately contributing to the development of more fair and equitable machine learning systems. This research represents an important step forward in the ongoing effort to address the challenges of bias and unfairness in AI and to ensure that the benefits of machine learning are distributed equitably across all segments of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
Position: Cracking the Code of Cascading Disparity Towards Marginalized Communities
Golnoosh Farnadi, Mohammad Havaei, Negar Rostamzadeh
0
0
The rise of foundation models holds immense promise for advancing AI, but this progress may amplify existing risks and inequalities, leaving marginalized communities behind. In this position paper, we discuss that disparities towards marginalized communities - performance, representation, privacy, robustness, interpretability and safety - are not isolated concerns but rather interconnected elements of a cascading disparity phenomenon. We contrast foundation models with traditional models and highlight the potential for exacerbated disparity against marginalized communities. Moreover, we emphasize the unique threat of cascading impacts in foundation models, where interconnected disparities can trigger long-lasting negative consequences, specifically to the people on the margin. We define marginalized communities within the machine learning context and explore the multifaceted nature of disparities. We analyze the sources of these disparities, tracing them from data creation, training and deployment procedures to highlight the complex technical and socio-technical landscape. To mitigate the pressing crisis, we conclude with a set of calls to action to mitigate disparity at its source.
6/5/2024
🌐
When mitigating bias is unfair: multiplicity and arbitrariness in algorithmic group fairness
Natasa Krco, Thibault Laugel, Vincent Grari, Jean-Michel Loubes, Marcin Detyniecki
0
0
Most research on fair machine learning has prioritized optimizing criteria such as Demographic Parity and Equalized Odds. Despite these efforts, there remains a limited understanding of how different bias mitigation strategies affect individual predictions and whether they introduce arbitrariness into the debiasing process. This paper addresses these gaps by exploring whether models that achieve comparable fairness and accuracy metrics impact the same individuals and mitigate bias in a consistent manner. We introduce the FRAME (FaiRness Arbitrariness and Multiplicity Evaluation) framework, which evaluates bias mitigation through five dimensions: Impact Size (how many people were affected), Change Direction (positive versus negative changes), Decision Rates (impact on models' acceptance rates), Affected Subpopulations (who was affected), and Neglected Subpopulations (where unfairness persists). This framework is intended to help practitioners understand the impacts of debiasing processes and make better-informed decisions regarding model selection. Applying FRAME to various bias mitigation approaches across key datasets allows us to exhibit significant differences in the behaviors of debiasing methods. These findings highlight the limitations of current fairness criteria and the inherent arbitrariness in the debiasing process.
5/24/2024
🤷
A Systematic and Formal Study of the Impact of Local Differential Privacy on Fairness: Preliminary Results
Karima Makhlouf, Tamara Stefanovic, Heber H. Arcolezi, Catuscia Palamidessi
0
0
Machine learning (ML) algorithms rely primarily on the availability of training data, and, depending on the domain, these data may include sensitive information about the data providers, thus leading to significant privacy issues. Differential privacy (DP) is the predominant solution for privacy-preserving ML, and the local model of DP is the preferred choice when the server or the data collector are not trusted. Recent experimental studies have shown that local DP can impact ML prediction for different subgroups of individuals, thus affecting fair decision-making. However, the results are conflicting in the sense that some studies show a positive impact of privacy on fairness while others show a negative one. In this work, we conduct a systematic and formal study of the effect of local DP on fairness. Specifically, we perform a quantitative study of how the fairness of the decisions made by the ML model changes under local DP for different levels of privacy and data distributions. In particular, we provide bounds in terms of the joint distributions and the privacy level, delimiting the extent to which local DP can impact the fairness of the model. We characterize the cases in which privacy reduces discrimination and those with the opposite effect. We validate our theoretical findings on synthetic and real-world datasets. Our results are preliminary in the sense that, for now, we study only the case of one sensitive attribute, and only statistical disparity, conditional statistical disparity, and equal opportunity difference.
5/24/2024
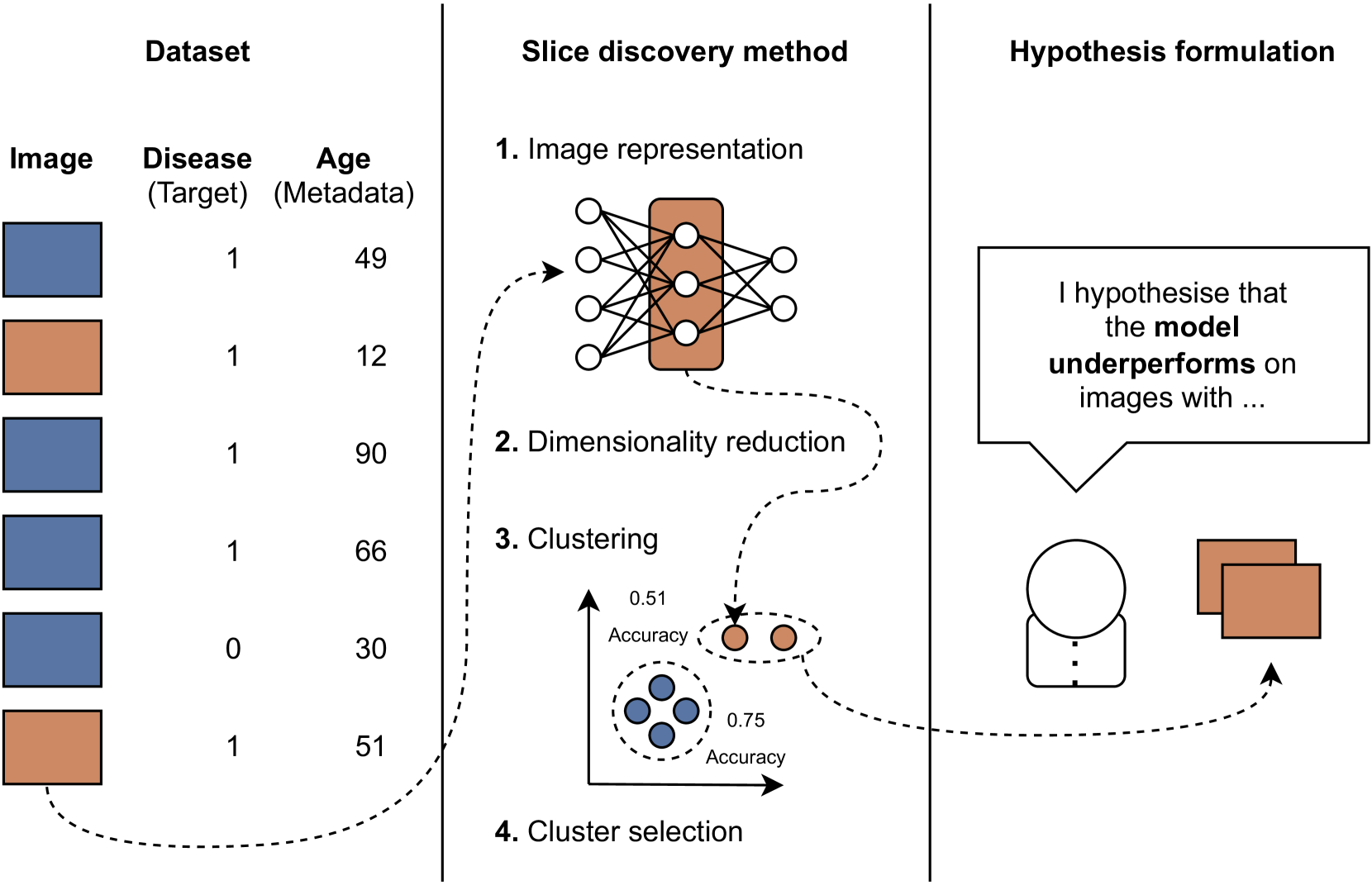
Slicing Through Bias: Explaining Performance Gaps in Medical Image Analysis using Slice Discovery Methods
Vincent Olesen, Nina Weng, Aasa Feragen, Eike Petersen
0
0
Machine learning models have achieved high overall accuracy in medical image analysis. However, performance disparities on specific patient groups pose challenges to their clinical utility, safety, and fairness. This can affect known patient groups - such as those based on sex, age, or disease subtype - as well as previously unknown and unlabeled groups. Furthermore, the root cause of such observed performance disparities is often challenging to uncover, hindering mitigation efforts. In this paper, to address these issues, we leverage Slice Discovery Methods (SDMs) to identify interpretable underperforming subsets of data and formulate hypotheses regarding the cause of observed performance disparities. We introduce a novel SDM and apply it in a case study on the classification of pneumothorax and atelectasis from chest x-rays. Our study demonstrates the effectiveness of SDMs in hypothesis formulation and yields an explanation of previously observed but unexplained performance disparities between male and female patients in widely used chest X-ray datasets and models. Our findings indicate shortcut learning in both classification tasks, through the presence of chest drains and ECG wires, respectively. Sex-based differences in the prevalence of these shortcut features appear to cause the observed classification performance gap, representing a previously underappreciated interaction between shortcut learning and model fairness analyses.
6/19/2024