Do As I Do: Pose Guided Human Motion Copy
2406.16601
0
0

Abstract
Human motion copy is an intriguing yet challenging task in artificial intelligence and computer vision, which strives to generate a fake video of a target person performing the motion of a source person. The problem is inherently challenging due to the subtle human-body texture details to be generated and the temporal consistency to be considered. Existing approaches typically adopt a conventional GAN with an L1 or L2 loss to produce the target fake video, which intrinsically necessitates a large number of training samples that are challenging to acquire. Meanwhile, current methods still have difficulties in attaining realistic image details and temporal consistency, which unfortunately can be easily perceived by human observers. Motivated by this, we try to tackle the issues from three aspects: (1) We constrain pose-to-appearance generation with a perceptual loss and a theoretically motivated Gromov-Wasserstein loss to bridge the gap between pose and appearance. (2) We present an episodic memory module in the pose-to-appearance generation to propel continuous learning that helps the model learn from its past poor generations. We also utilize geometrical cues of the face to optimize facial details and refine each key body part with a dedicated local GAN. (3) We advocate generating the foreground in a sequence-to-sequence manner rather than a single-frame manner, explicitly enforcing temporal inconsistency. Empirical results on five datasets, iPER, ComplexMotion, SoloDance, Fish, and Mouse datasets, demonstrate that our method is capable of generating realistic target videos while precisely copying motion from a source video. Our method significantly outperforms state-of-the-art approaches and gains 7.2% and 12.4% improvements in PSNR and FID respectively.
Create account to get full access
Overview
- This paper presents a novel method for human motion copy, which involves capturing the movements of one person and transferring them to another person's avatar.
- The approach uses a deep learning model to map the source person's pose to the target person's pose, enabling the target to mimic the source's movements in a realistic and natural way.
- Key innovations include the use of Gromov-Wasserstein distance to align the pose representations and a novel network architecture that can handle multiple conditions (e.g., different source and target poses).
Plain English Explanation
The paper describes a system that can take the movements of one person and apply them to a different person's virtual character or "avatar." This could be useful for creating realistic-looking fake videos or for animating characters in video games or movies.
The key idea is to use a machine learning model to map the pose (position and orientation) of the source person's body to the pose of the target person's avatar. This allows the target avatar to mimic the source person's movements in a natural and lifelike way.
Some of the technical innovations include:
- Using a special distance metric called Gromov-Wasserstein distance to better align the pose representations between the source and target.
- Developing a network architecture that can handle multiple conditions, such as different source and target poses, which makes the system more flexible and powerful.
Overall, this work advances the state-of-the-art in pose-guided human motion transfer and zero-shot high-fidelity pose control, with potential applications in areas like video synthesis and character animation.
Technical Explanation
The paper presents a novel method for "Do as I Do: Pose Guided Human Motion Copy," which aims to capture the movements of one person and transfer them to another person's avatar.
The key technical innovations include:
-
Gromov-Wasserstein Alignment: The method uses Gromov-Wasserstein distance to align the pose representations between the source and target, which is more effective than traditional approaches.
-
Conditional Network Architecture: The network is designed to handle multiple conditions, such as different source and target poses, allowing for more flexibility and generalization.
The system works as follows:
- The source person's pose is captured using a pose estimation model.
- The target person's 3D body model is used to represent their pose.
- A deep learning model maps the source pose to the target pose, enabling the target avatar to mimic the source person's movements.
Experiments show that this approach can produce high-fidelity motion transfer results, outperforming previous state-of-the-art methods. The use of Gromov-Wasserstein distance and the conditional network architecture are key to the system's performance.
Critical Analysis
The paper presents a compelling solution for human motion transfer, with several notable strengths:
- The Gromov-Wasserstein alignment technique is a novel and effective way to match the source and target pose representations.
- The conditional network architecture allows the system to handle a wider range of scenarios, increasing its practical applicability.
- The results demonstrate impressive visual quality and realism in the transferred motions.
However, the paper also acknowledges several limitations and areas for further research:
- The system is currently limited to full-body motions and may not generalize well to more fine-grained or complex movements.
- The training process requires paired source-target data, which may be difficult to obtain in practice.
- The paper does not explore the potential for real-time or interactive applications of the technology.
Additionally, there are a few potential concerns that could be addressed:
- The ethical implications of using this technology for deep fake video generation should be carefully considered.
- The system's robustness to variations in body types, clothing, and other factors could be further investigated.
- The computational efficiency and deployment feasibility of the model could be explored in more depth.
Overall, this work represents a significant advancement in human motion transfer, with the potential for impactful applications in areas like animation, virtual reality, and video production. However, continued research and thoughtful consideration of the technology's implications will be crucial as it continues to evolve.
Conclusion
The "Do as I Do: Pose Guided Human Motion Copy" paper presents a novel deep learning-based approach for transferring human movements from one person to another person's virtual avatar. The key innovations include the use of Gromov-Wasserstein distance for pose alignment and a conditional network architecture that can handle multiple source-target configurations.
This work advances the state-of-the-art in pose-guided human motion transfer and has the potential for a wide range of applications, including video synthesis, character animation, and virtual reality. While the paper acknowledges some limitations, the overall quality and flexibility of the proposed system are impressive and suggest promising directions for future research in this area.
As with any powerful technology, it will be crucial to consider the ethical implications of motion transfer systems and ensure they are developed and deployed responsibly. Continued advancements in this field could lead to significant impacts, both positive and negative, on fields ranging from entertainment to personal privacy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MimicMotion: High-Quality Human Motion Video Generation with Confidence-aware Pose Guidance
Yuang Zhang, Jiaxi Gu, Li-Wen Wang, Han Wang, Junqi Cheng, Yuefeng Zhu, Fangyuan Zou
0
0
In recent years, generative artificial intelligence has achieved significant advancements in the field of image generation, spawning a variety of applications. However, video generation still faces considerable challenges in various aspects, such as controllability, video length, and richness of details, which hinder the application and popularization of this technology. In this work, we propose a controllable video generation framework, dubbed MimicMotion, which can generate high-quality videos of arbitrary length mimicking specific motion guidance. Compared with previous methods, our approach has several highlights. Firstly, we introduce confidence-aware pose guidance that ensures high frame quality and temporal smoothness. Secondly, we introduce regional loss amplification based on pose confidence, which significantly reduces image distortion. Lastly, for generating long and smooth videos, we propose a progressive latent fusion strategy. By this means, we can produce videos of arbitrary length with acceptable resource consumption. With extensive experiments and user studies, MimicMotion demonstrates significant improvements over previous approaches in various aspects. Detailed results and comparisons are available on our project page: https://tencent.github.io/MimicMotion .
7/1/2024

PoseAnimate: Zero-shot high fidelity pose controllable character animation
Bingwen Zhu, Fanyi Wang, Tianyi Lu, Peng Liu, Jingwen Su, Jinxiu Liu, Yanhao Zhang, Zuxuan Wu, Guo-Jun Qi, Yu-Gang Jiang
0
0
Image-to-video (I2V) generation aims to create a video sequence from a single image, which requires high temporal coherence and visual fidelity. However, existing approaches suffer from inconsistency of character appearances and poor preservation of fine details. Moreover, they require a large amount of video data for training, which can be computationally demanding. To address these limitations, we propose PoseAnimate, a novel zero-shot I2V framework for character animation. PoseAnimate contains three key components: 1) a Pose-Aware Control Module (PACM) that incorporates diverse pose signals into text embeddings, to preserve character-independent content and maintain precise alignment of actions. 2) a Dual Consistency Attention Module (DCAM) that enhances temporal consistency and retains character identity and intricate background details. 3) a Mask-Guided Decoupling Module (MGDM) that refines distinct feature perception abilities, improving animation fidelity by decoupling the character and background. We also propose a Pose Alignment Transition Algorithm (PATA) to ensure smooth action transition. Extensive experiment results demonstrate that our approach outperforms the state-of-the-art training-based methods in terms of character consistency and detail fidelity. Moreover, it maintains a high level of temporal coherence throughout the generated animations.
6/6/2024
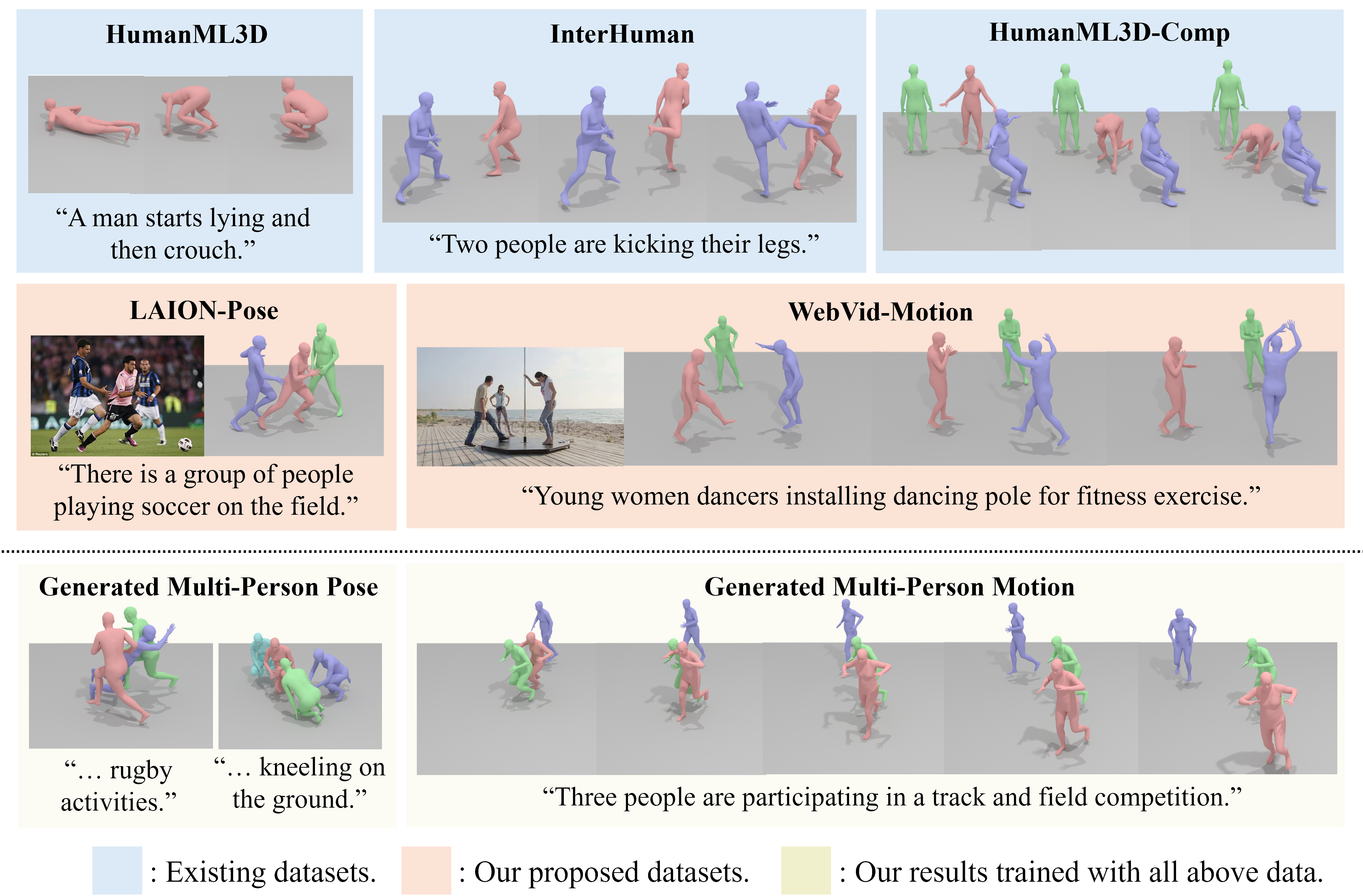
Towards Open Domain Text-Driven Synthesis of Multi-Person Motions
Mengyi Shan, Lu Dong, Yutao Han, Yuan Yao, Tao Liu, Ifeoma Nwogu, Guo-Jun Qi, Mitch Hill
0
0
This work aims to generate natural and diverse group motions of multiple humans from textual descriptions. While single-person text-to-motion generation is extensively studied, it remains challenging to synthesize motions for more than one or two subjects from in-the-wild prompts, mainly due to the lack of available datasets. In this work, we curate human pose and motion datasets by estimating pose information from large-scale image and video datasets. Our models use a transformer-based diffusion framework that accommodates multiple datasets with any number of subjects or frames. Experiments explore both generation of multi-person static poses and generation of multi-person motion sequences. To our knowledge, our method is the first to generate multi-subject motion sequences with high diversity and fidelity from a large variety of textual prompts.
5/30/2024
🤷
ImitationNet: Unsupervised Human-to-Robot Motion Retargeting via Shared Latent Space
Yashuai Yan, Esteve Valls Mascaro, Dongheui Lee
0
0
This paper introduces a novel deep-learning approach for human-to-robot motion retargeting, enabling robots to mimic human poses accurately. Contrary to prior deep-learning-based works, our method does not require paired human-to-robot data, which facilitates its translation to new robots. First, we construct a shared latent space between humans and robots via adaptive contrastive learning that takes advantage of a proposed cross-domain similarity metric between the human and robot poses. Additionally, we propose a consistency term to build a common latent space that captures the similarity of the poses with precision while allowing direct robot motion control from the latent space. For instance, we can generate in-between motion through simple linear interpolation between two projected human poses. We conduct a comprehensive evaluation of robot control from diverse modalities (i.e., texts, RGB videos, and key poses), which facilitates robot control for non-expert users. Our model outperforms existing works regarding human-to-robot retargeting in terms of efficiency and precision. Finally, we implemented our method in a real robot with self-collision avoidance through a whole-body controller to showcase the effectiveness of our approach. More information on our website https://evm7.github.io/UnsH2R/
4/9/2024