Draw-and-Understand: Leveraging Visual Prompts to Enable MLLMs to Comprehend What You Want
2403.20271
0
0

Abstract
The interaction between humans and artificial intelligence (AI) is a crucial factor that reflects the effectiveness of multimodal large language models (MLLMs). However, current MLLMs primarily focus on image-level comprehension and limit interaction to textual instructions, thereby constraining their flexibility in usage and depth of response. In this paper, we introduce the Draw-and-Understand project: a new model, a multi-domain dataset, and a challenging benchmark for visual prompting. Specifically, we propose SPHINX-V, a new end-to-end trained Multimodal Large Language Model (MLLM) that connects a vision encoder, a visual prompt encoder and an LLM for various visual prompts (points, bounding boxes, and free-form shape) and language understanding. To advance visual prompting research for MLLMs, we introduce MDVP-Data and MDVP-Bench. MDVP-Data features a multi-domain dataset containing 1.6M unique image-visual prompt-text instruction-following samples, including natural images, document images, OCR images, mobile screenshots, web screenshots, and multi-panel images. Furthermore, we present MDVP-Bench, a comprehensive and challenging benchmark to assess a model's capability in understanding visual prompting instructions. Our experiments demonstrate SPHINX-V's impressive multimodal interaction capabilities through visual prompting, revealing significant improvements in detailed pixel-level description and question-answering abilities.
Create account to get full access
Introduction
The paper discusses enhancing multimodal large language models (MLLMs) for pixel-level image understanding using visual prompting. Current MLLMs focus on comprehending entire images, limiting users from highlighting specific areas for detailed inquiries. Recent advancements have explored using textual representations, positional embeddings, and regions of interest (ROIs) to enhance spatial recognition and focus on specific image areas. However, these methods have limitations, such as relying on pre-existing segmentation models or fixed formats like bounding boxes.
To address these shortcomings, the paper introduces SPHINX-V, an end-to-end multimodal large language model designed for pixel-level image understanding. SPHINX-V comprises a vision encoder, visual prompt encoder, and a large language model (LLM). It leverages pre-trained MLLMs like SPHINX for robust vision-language understanding.
The paper proposes a two-stage training strategy: (1) pre-training for image-visual prompt-text alignment and (2) supervised fine-tuning following instructions. It integrates continuous visual prompts (strokes, scribbles) with bounding boxes during inference, avoiding separate modeling. A noise-based training augmentation strategy is introduced to simulate region areas for free-form shaped inputs.
With SPHINX-V, users can interact using natural language and referring actions (clicking, drawing) to obtain answers about the region of interest.
The paper introduces MDVP-Data, a large dataset containing approximately 0.9 million images and 1.6 million query-answer pairs focusing on image-point-text and image-region-text pairings. This dataset covers a wide range of image types and interactions, providing a comprehensive solution for fine-grained pixel-level understanding. The dataset includes detailed attributes, relationships, and context for objects identified by visual prompts.
To evaluate the effectiveness of visual prompting models, the paper proposes MDVP-Bench, a benchmark tailored for assessing models' pixel-level comprehension. It encompasses tasks like point-level and region-level captioning, inter-relationship analysis, and complex reasoning.
The paper also introduces SPHINX-V, a new multimodal large language model designed for visual prompting. It features a novel visual prompt encoder and a two-stage training strategy, supporting multiple visual prompts across various types. This model aims to enhance user flexibility and achieve fine-grained, open-world understanding of visual prompts.
The experimental results demonstrate that SPHINX-V consistently outperforms other visual prompting models in a broad range of pixel-level understanding tasks across established benchmarks.
Related Works
The provided text discusses the recent development of multimodal large language models (MLLMs) and visual and multimodal prompting techniques in deep learning. It highlights the significant milestones achieved by Large Language Models (LLMs) in Natural Language Processing (NLP) and their extension to multimodal learning, leading to the emergence of MLLMs such as BLIP-2, Flamingo, and PaLM-E.
The text also explores the focus on fine-grained visual understanding, with works like VisionLLM employing language-guided tokenizers to extract relevant visual features at specific granularities. It discusses the emerging area of visual and multimodal prompting, including techniques using visual prompts (e.g., boxes, masks) to enhance model performance on specific visual tasks.
The text mentions key developments like SAM and its enhanced versions, which support a broad range of prompts but initially struggled with semantic labeling. This led to innovations like SEEM, HIPIE, and Semantic SAM to improve semantic prediction. However, the text emphasizes the need for multidimensional semantic analysis for real-world applications.
Recent studies like GPT4RoI, Kosmos-2, Shikra, Ferret, and GLaMM have enabled MLLMs to achieve region-based image understanding. Techniques like Colorful Prompting Tuning (CPT) and RedCircle pioneer the use of color overlays and visual cues to enhance interpretative abilities. ViP-LLaVA allows users to mark images and interact with the model using natural prompts, while Osprey incorporates fine-grained mask regions into language instruction for precise pixel-wise visual understanding.
The text also mentions the limitations of existing methods, such as relying on pre-attached segmentation models or externally provided ground truth masks, and the inability to refer to multiple targets simultaneously, which limits the model's ability to perform complex understanding and reasoning tasks.
MDVP: Multi-domain Visual-Prompt Instruction Data Generation
The paper introduces MDVP-Data, a large dataset of 1.6 million multimodal dialogues designed to foster fine-grained pixel-level and open-world image understanding in multimodal language models (MLLMs). The dataset integrates point-level and region-level instruction data derived from public datasets.
MDVP-Data consists of two types of data: 1) A restructured public grounding dataset formatted for visual prompt-based instruction following, and 2) High-quality training pairs developed using meticulously crafted prompt templates, produced through the GPT-4V model.
The first part of the dataset is created by inverting existing datasets for Referring Expression Comprehension, Phrase Grounding, and Grounding QA. Ground truth boxes are treated as input visual prompts, and natural language descriptions as answers.
The second part involves collecting multi-domain images and annotations, and tasking GPT-4V with brief captioning, detailed captioning, inter-relationship analysis, and complex reasoning. Set-of-Marks prompting is employed to help GPT-4V recognize referred objects.
The paper also presents MDVP-Bench, a challenging benchmark suite to evaluate pixel-level understanding capabilities under various visual prompts. It employs GPT-4V for evaluation, directly annotating images with prompts to circumvent potential misinterpretations.
Model Architecture

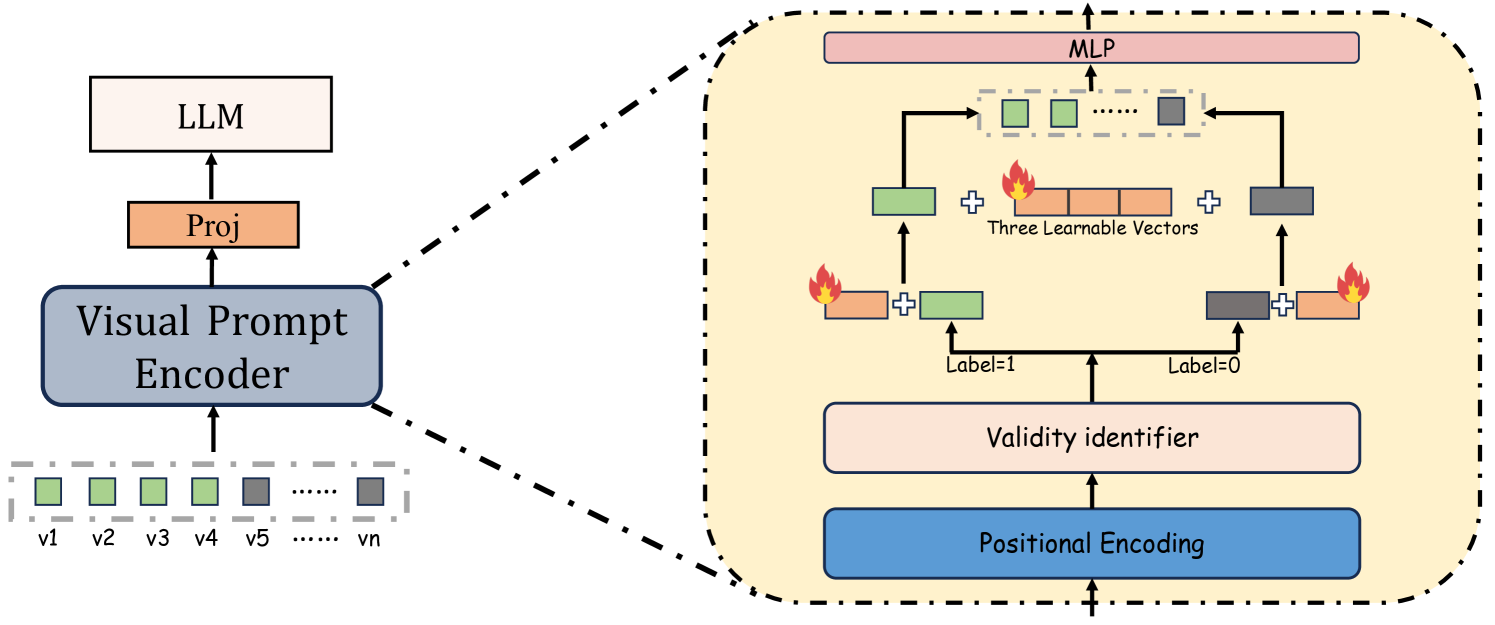
The section describes SPHINX-V, a model designed for pixel-level referring understanding. It consists of a mixed vision encoder, a visual prompt encoder, and a large language model (LLM). The vision encoder generates image embeddings, while the visual prompt encoder handles point and bounding box inputs, converting them into embeddings aligned with the LLM's word embedding space. The LLM used is LLaMA 2-13B.
Training occurs in two stages: 1) Image-Visual Prompt-Text Alignment Pre-training, where the visual prompt encoder is trained to align visual prompts with image and text features, using datasets for object detection, segmentation, layout detection, etc. Noise-based augmentation simulates free-form shape visual prompts. 2) Multi-Task Supervised Finetuning, where the LLM and visual prompt projector are fine-tuned on datasets like MDVP, Visual Genome, VCR, Visual7w, and Osprey-724k to enhance understanding of user instructions and complex reasoning tasks.
During inference, free-form visual prompts are preprocessed to obtain their bounding boxes, which are then fed to SPHINX-V along with the image and text instruction.
Experiments
The paper presents implementation details and evaluation results for SPHINX-V, a multimodal model for visual understanding tasks. Key points:
AdamW optimizer and flash attention were used for training efficiency. Two training stages with different learning rates were employed on 8 NVIDIA A100 GPUs.
SPHINX-V achieved state-of-the-art performance on referring object classification tasks on LVIS and PACO datasets, outperforming previous methods by a large margin using both point and box visual prompts.
For optical character recognition on COCO-Text, SPHINX-V surpassed ChatSpot by 13.64%.
On region-level captioning tasks, SPHINX-V demonstrated promising results compared to other methods for both brief and detailed region descriptions.
SPHINX-V showed strong performance on comprehensive benchmarks like LLaVA-Bench, Ferret-Bench, and the proposed MDVP-Bench, indicating robust pixel-level understanding and reasoning capabilities.
Visual examples illustrate SPHINX-V's spatial understanding across various domains. An ablation study validated the effectiveness of the visual prompt encoder and two-stage training strategy.
Conclusion
This paper introduces SPHINX-V, a new multimodal large language model capable of visual prompting for pixel-level image understanding. SPHINX-V utilizes a visual prompt encoder and two-stage training strategy, allowing it to support various visual prompts like points, boxes, and free-form shapes, enhancing user flexibility. The authors curated the MDVP dataset, containing 1.6M image-point-text and image-region-text pairs for model training, and the MDVP benchmark for evaluation.
SPHINX-V demonstrated superior performance in visual prompting tasks such as referring object classification, region-level captioning, regional OCR, and referring reasoning, highlighting its efficacy and robustness. The authors anticipate their contributions will lay the foundation for further advancements in intelligent visual interaction systems.
Appendix
Appendix 0.A More Details of Architecture
The image encoder utilizes a Mixture of Visual Experts (MoV) with mixed scales and high-resolution sub-images to process high-resolution inputs. It employs two complementary vision encoders: DINOv2 and CLIP-ConvNeXt, to capture diverse visual representations. Images are scaled and zero-padded to 448x448 resolution, then divided into four 224x224 sub-images. For images with large aspect ratios, a learnable skip token replaces fully-padded sub-images, providing relative positional information.
The visual prompt encoder represents point-type visual prompts (VPs) as the sum of positional encodings of the point's coordinates. For box-type inputs, VPs are the aggregate of positional encodings for the top-left and bottom-right corner coordinates. Learned embeddings indicate the VP's validity and delineate positions of the center point, top-left corner, and bottom-right corner. An MLP generates the final 512-dimensional embeddings of the visual prompts.
Appendix 0.B More Experiments
The provided text evaluates the captioning and reasoning capabilities of the proposed SPHINX-V model on two datasets: Visual Genome and Visual Commonsense Reasoning (VCR).
On Visual Genome, SPHINX-V achieves a METEOR score of 24.3 and a CIDEr score of 197.3, outperforming state-of-the-art methods like TAP(ViT-L) by a significant margin. This demonstrates the model's superior ability to generate semantically relevant descriptions for object regions.
For the VCR dataset, which assesses high-level cognitive and commonsense reasoning abilities, SPHINX-V achieves the highest accuracy scores of 89.65% for Question → Answer, 90.23% for Question+Answer → Rationale, and 89.63% for Question → Answer+Rationale. These results showcase the model's proficiency in interpreting and justifying visual elements within specific contexts.
Appendix 0.C More Details of Dataset
The paper outlines the methodology for reconstructing public grounding datasets and generating instruction-based data across various domains using GPT-4V, leading to the development of the MDVP Dataset. It provides an example of inverse grounding from the Flickr30k dataset, where the model generates ground truth sentences from bounding boxes instead of identifying bounding boxes from sentences.
The paper then presents the prompts used to facilitate data generation by GPT-4V across different domains like natural images, screenshots, documents, OCR-spotting, and multi-panel images. Tables 12-17 showcase the universal and domain-specific prompt templates with different roles assigned to GPT-4V, such as providing short descriptions, detailed descriptions, inter-relationship analysis, and Q&A conversations. Table 18 illustrates an example response from GPT-4V during data generation.
Finally, Figure 9 provides additional visual examples of the SPHINX-V system utilizing arbitrary-shaped visual prompts across multiple domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ViP-LLaVA: Making Large Multimodal Models Understand Arbitrary Visual Prompts
Mu Cai, Haotian Liu, Dennis Park, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Yong Jae Lee
0
0
While existing large vision-language multimodal models focus on whole image understanding, there is a prominent gap in achieving region-specific comprehension. Current approaches that use textual coordinates or spatial encodings often fail to provide a user-friendly interface for visual prompting. To address this challenge, we introduce a novel multimodal model capable of decoding arbitrary visual prompts. This allows users to intuitively mark images and interact with the model using natural cues like a red bounding box or pointed arrow. Our simple design directly overlays visual markers onto the RGB image, eliminating the need for complex region encodings, yet achieves state-of-the-art performance on region-understanding tasks like Visual7W, PointQA, and Visual Commonsense Reasoning benchmark. Furthermore, we present ViP-Bench, a comprehensive benchmark to assess the capability of models in understanding visual prompts across multiple dimensions, enabling future research in this domain. Code, data, and model are publicly available.
4/30/2024

Enhancing Multimodal Large Language Models with Multi-instance Visual Prompt Generator for Visual Representation Enrichment
Wenliang Zhong, Wenyi Wu, Qi Li, Rob Barton, Boxin Du, Shioulin Sam, Karim Bouyarmane, Ismail Tutar, Junzhou Huang
0
0
Multimodal Large Language Models (MLLMs) have achieved SOTA performance in various visual language tasks by fusing the visual representations with LLMs leveraging some visual adapters. In this paper, we first establish that adapters using query-based Transformers such as Q-former is a simplified Multi-instance Learning method without considering instance heterogeneity/correlation. We then propose a general component termed Multi-instance Visual Prompt Generator (MIVPG) to incorporate enriched visual representations into LLMs by taking advantage of instance correlation between images or patches for the same sample. Quantatitive evaluation on three public vision-language (VL) datasets from different scenarios shows that the proposed MIVPG improves Q-former in main VL tasks.
6/6/2024

Joint Visual and Text Prompting for Improved Object-Centric Perception with Multimodal Large Language Models
Songtao Jiang, Yan Zhang, Chenyi Zhou, Yeying Jin, Yang Feng, Jian Wu, Zuozhu Liu
0
0
Multimodal Large Language Models (MLLMs) such as GPT-4V and Gemini Pro face challenges in achieving human-level perception in Visual Question Answering (VQA), particularly in object-oriented perception tasks which demand fine-grained understanding of object identities, locations or attributes, as indicated by empirical findings. This is mainly due to their limited capability to effectively integrate complex visual cues with textual information and potential object hallucinations. In this paper, we present a novel approach, Joint Visual and Text Prompting (VTPrompt), that employs fine-grained visual information to enhance the capability of MLLMs in VQA, especially for object-oriented perception. VTPrompt merges visual and text prompts to extract key concepts from textual questions and employs a detection model to highlight relevant objects as visual prompts in images. The processed images alongside text prompts are subsequently fed into MLLMs to produce more accurate answers. Our experiments with GPT-4V and Gemini Pro, on three benchmarks, i.e., MME , MMB and POPE, demonstrate significant improvements. Particularly, our method led to a score improvement of up to 183.5 for GPT-4V on MME and enhanced MMB performance by 8.17% for GPT-4V and 15.69% for Gemini Pro.
4/9/2024
🏅
Fine-tuning Multimodal LLMs to Follow Zero-shot Demonstrative Instructions
Juncheng Li, Kaihang Pan, Zhiqi Ge, Minghe Gao, Wei Ji, Wenqiao Zhang, Tat-Seng Chua, Siliang Tang, Hanwang Zhang, Yueting Zhuang
0
0
Recent advancements in Multimodal Large Language Models (MLLMs) have been utilizing Visual Prompt Generators (VPGs) to convert visual features into tokens that LLMs can recognize. This is achieved by training the VPGs on millions of image-caption pairs, where the VPG-generated tokens of images are fed into a frozen LLM to generate the corresponding captions. However, this image-captioning based training objective inherently biases the VPG to concentrate solely on the primary visual contents sufficient for caption generation, often neglecting other visual details. This shortcoming results in MLLMs' underperformance in comprehending demonstrative instructions consisting of multiple, interleaved, and multimodal instructions that demonstrate the required context to complete a task. To address this issue, we introduce a generic and lightweight Visual Prompt Generator Complete module (VPG-C), which can infer and complete the missing details essential for comprehending demonstrative instructions. Further, we propose a synthetic discriminative training strategy to fine-tune VPG-C, eliminating the need for supervised demonstrative instructions. As for evaluation, we build DEMON, a comprehensive benchmark for demonstrative instruction understanding. Synthetically trained with the proposed strategy, VPG-C achieves significantly stronger zero-shot performance across all tasks of DEMON. Further evaluation on the MME and OwlEval benchmarks also demonstrate the superiority of VPG-C. Our benchmark, code, and pre-trained models are available at https://github.com/DCDmllm/Cheetah.
5/28/2024