Efficiently Adversarial Examples Generation for Visual-Language Models under Targeted Transfer Scenarios using Diffusion Models
2404.10335
0
0

Abstract
Targeted transfer-based attacks involving adversarial examples pose a significant threat to large visual-language models (VLMs). However, the state-of-the-art (SOTA) transfer-based attacks incur high costs due to excessive iteration counts. Furthermore, the generated adversarial examples exhibit pronounced adversarial noise and demonstrate limited efficacy in evading defense methods such as DiffPure. To address these issues, inspired by score matching, we introduce AdvDiffVLM, which utilizes diffusion models to generate natural, unrestricted adversarial examples. Specifically, AdvDiffVLM employs Adaptive Ensemble Gradient Estimation to modify the score during the diffusion model's reverse generation process, ensuring the adversarial examples produced contain natural adversarial semantics and thus possess enhanced transferability. Simultaneously, to enhance the quality of adversarial examples further, we employ the GradCAM-guided Mask method to disperse adversarial semantics throughout the image, rather than concentrating them in a specific area. Experimental results demonstrate that our method achieves a speedup ranging from 10X to 30X compared to existing transfer-based attack methods, while maintaining superior quality of adversarial examples. Additionally, the generated adversarial examples possess strong transferability and exhibit increased robustness against adversarial defense methods. Notably, AdvDiffVLM can successfully attack commercial VLMs, including GPT-4V, in a black-box manner.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the efficient generation of adversarial examples for visual-language models using diffusion models.
- The researchers propose a method to generate targeted adversarial examples that can fool visual-language models, even when the target model is different from the model used to generate the examples.
- The approach leverages the flexibility and power of diffusion models, which have shown promise for generative adversarial network (GAN) defenses and creating high-quality synthetic media.
Plain English Explanation
Adversarial examples are small, carefully crafted changes to images that can fool AI models into making incorrect predictions. In this paper, the researchers developed a way to efficiently generate these types of adversarial examples specifically for visual-language models, which are AI systems that can understand and process both images and text.
The key idea is to use a type of AI model called a diffusion model. Diffusion models are a powerful new tool for generating high-quality synthetic images and have also shown promise for defending against adversarial attacks.
The researchers' approach allows them to generate adversarial examples that can fool a target visual-language model, even if that model is different from the one used to generate the examples. This is an important capability, as it means the adversarial examples can be transferred to different models, making them more widely applicable.
The paper demonstrates the effectiveness of this approach through various experiments, showing that the generated adversarial examples can significantly degrade the performance of several state-of-the-art visual-language models.
Technical Explanation
The researchers propose a method called "Diffusion-based Targeted Adversarial Example Generation" (DTAEG) that leverages diffusion models to efficiently generate adversarial examples for visual-language models.
The key steps are:
- Train a diffusion model on a dataset of images and their corresponding captions.
- Use this diffusion model to generate adversarial examples that target a specific output (e.g., a particular caption) for a given input image.
- Evaluate the transferability of the generated adversarial examples by testing them on different target visual-language models.
The researchers demonstrate the effectiveness of their approach through extensive experiments on several benchmark datasets and state-of-the-art visual-language models, including CLIP, GLIP, and BLIP.
The results show that the adversarial examples generated by DTAEG can significantly degrade the performance of these models, even when the target model is different from the one used to generate the examples. This demonstrates the transferability and effectiveness of the proposed approach.
Critical Analysis
The paper provides a compelling approach for efficiently generating targeted adversarial examples for visual-language models using diffusion models. The key strengths of the research include:
- Leveraging the flexibility and power of diffusion models to generate high-quality adversarial examples.
- Demonstrating the transferability of the generated adversarial examples across different target models.
- Extensive experimentation and evaluation on state-of-the-art visual-language models.
However, the paper also acknowledges some limitations and areas for further research:
- The impact of the generated adversarial examples on real-world applications of visual-language models is not fully explored.
- The paper does not address potential defenses or mitigation strategies against the proposed attack.
- Further research is needed to understand the broader implications and societal impacts of such adversarial example generation techniques.
Conclusion
This paper presents a novel approach for efficiently generating targeted adversarial examples for visual-language models using diffusion models. The researchers demonstrate the effectiveness and transferability of their method, which can significantly degrade the performance of state-of-the-art models.
While the research advances our understanding of adversarial attacks on visual-language models, it also highlights the need for continued efforts in developing robust and secure AI systems that can withstand such attacks. As the use of these models becomes more widespread, addressing the security and reliability challenges will be crucial for their safe and responsible deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
Probing Unlearned Diffusion Models: A Transferable Adversarial Attack Perspective
Xiaoxuan Han, Songlin Yang, Wei Wang, Yang Li, Jing Dong
0
0
Advanced text-to-image diffusion models raise safety concerns regarding identity privacy violation, copyright infringement, and Not Safe For Work content generation. Towards this, unlearning methods have been developed to erase these involved concepts from diffusion models. However, these unlearning methods only shift the text-to-image mapping and preserve the visual content within the generative space of diffusion models, leaving a fatal flaw for restoring these erased concepts. This erasure trustworthiness problem needs probe, but previous methods are sub-optimal from two perspectives: (1) Lack of transferability: Some methods operate within a white-box setting, requiring access to the unlearned model. And the learned adversarial input often fails to transfer to other unlearned models for concept restoration; (2) Limited attack: The prompt-level methods struggle to restore narrow concepts from unlearned models, such as celebrity identity. Therefore, this paper aims to leverage the transferability of the adversarial attack to probe the unlearning robustness under a black-box setting. This challenging scenario assumes that the unlearning method is unknown and the unlearned model is inaccessible for optimization, requiring the attack to be capable of transferring across different unlearned models. Specifically, we employ an adversarial search strategy to search for the adversarial embedding which can transfer across different unlearned models. This strategy adopts the original Stable Diffusion model as a surrogate model to iteratively erase and search for embeddings, enabling it to find the embedding that can restore the target concept for different unlearning methods. Extensive experiments demonstrate the transferability of the searched adversarial embedding across several state-of-the-art unlearning methods and its effectiveness for different levels of concepts.
5/1/2024
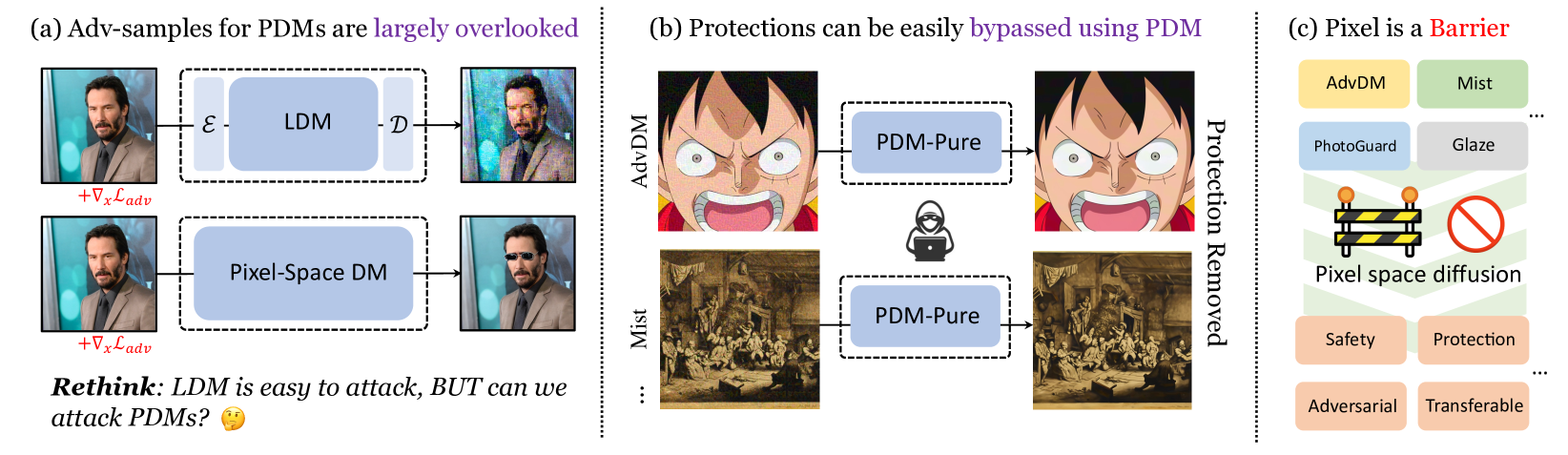
Pixel is a Barrier: Diffusion Models Are More Adversarially Robust Than We Think
Haotian Xue, Yongxin Chen
0
0
Adversarial examples for diffusion models are widely used as solutions for safety concerns. By adding adversarial perturbations to personal images, attackers can not edit or imitate them easily. However, it is essential to note that all these protections target the latent diffusion model (LDMs), the adversarial examples for diffusion models in the pixel space (PDMs) are largely overlooked. This may mislead us to think that the diffusion models are vulnerable to adversarial attacks like most deep models. In this paper, we show novel findings that: even though gradient-based white-box attacks can be used to attack the LDMs, they fail to attack PDMs. This finding is supported by extensive experiments of almost a wide range of attacking methods on various PDMs and LDMs with different model structures, which means diffusion models are indeed much more robust against adversarial attacks. We also find that PDMs can be used as an off-the-shelf purifier to effectively remove the adversarial patterns that were generated on LDMs to protect the images, which means that most protection methods nowadays, to some extent, cannot protect our images from malicious attacks. We hope that our insights will inspire the community to rethink the adversarial samples for diffusion models as protection methods and move forward to more effective protection. Codes are available in https://github.com/xavihart/PDM-Pure.
5/3/2024
🌿
Intriguing Properties of Diffusion Models: An Empirical Study of the Natural Attack Capability in Text-to-Image Generative Models
Takami Sato, Justin Yue, Nanze Chen, Ningfei Wang, Qi Alfred Chen
0
0
Denoising probabilistic diffusion models have shown breakthrough performance to generate more photo-realistic images or human-level illustrations than the prior models such as GANs. This high image-generation capability has stimulated the creation of many downstream applications in various areas. However, we find that this technology is actually a double-edged sword: We identify a new type of attack, called the Natural Denoising Diffusion (NDD) attack based on the finding that state-of-the-art deep neural network (DNN) models still hold their prediction even if we intentionally remove their robust features, which are essential to the human visual system (HVS), through text prompts. The NDD attack shows a significantly high capability to generate low-cost, model-agnostic, and transferable adversarial attacks by exploiting the natural attack capability in diffusion models. To systematically evaluate the risk of the NDD attack, we perform a large-scale empirical study with our newly created dataset, the Natural Denoising Diffusion Attack (NDDA) dataset. We evaluate the natural attack capability by answering 6 research questions. Through a user study, we find that it can achieve an 88% detection rate while being stealthy to 93% of human subjects; we also find that the non-robust features embedded by diffusion models contribute to the natural attack capability. To confirm the model-agnostic and transferable attack capability, we perform the NDD attack against the Tesla Model 3 and find that 73% of the physically printed attacks can be detected as stop signs. Our hope is that the study and dataset can help our community be aware of the risks in diffusion models and facilitate further research toward robust DNN models.
5/3/2024
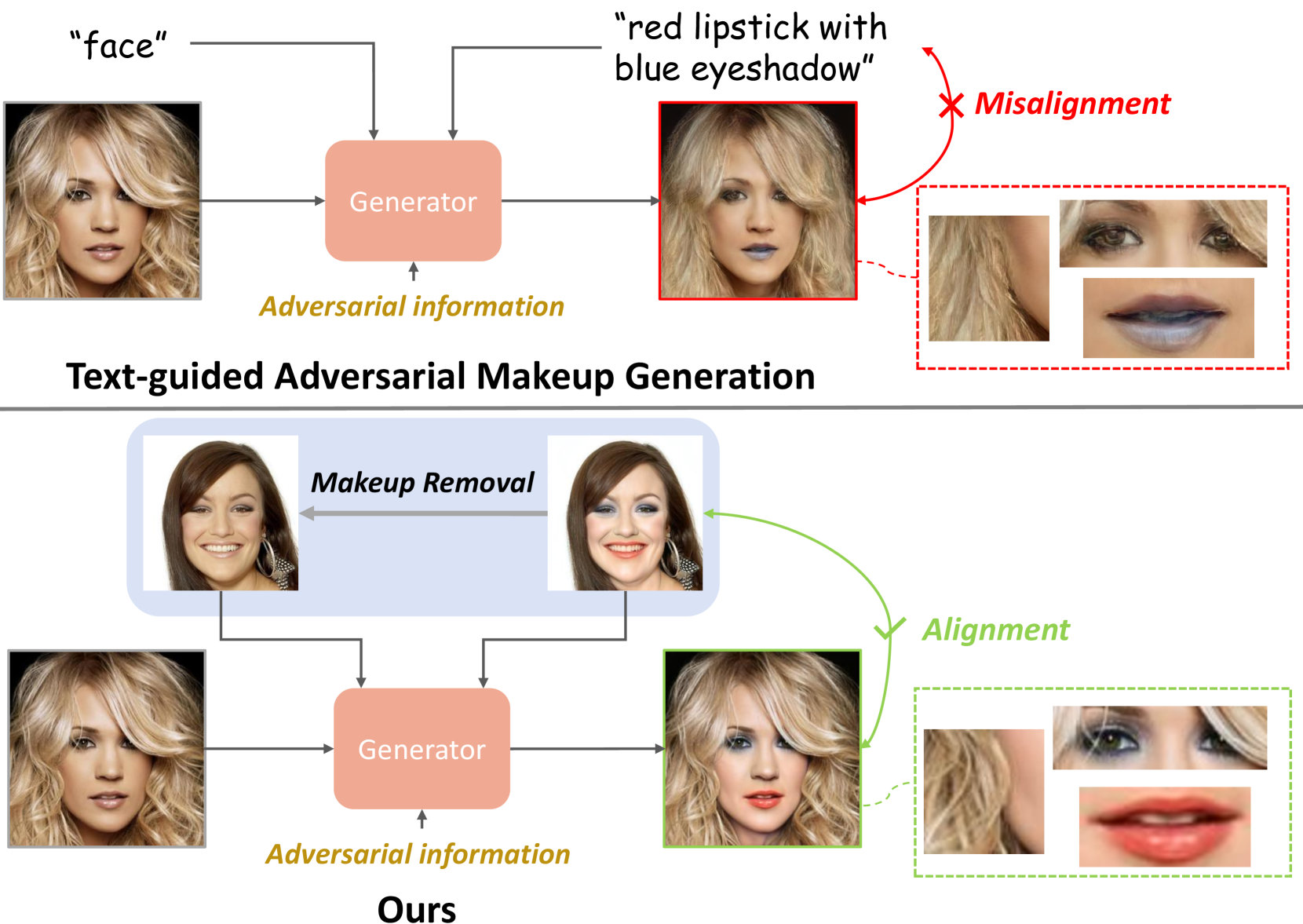
New!DiffAM: Diffusion-based Adversarial Makeup Transfer for Facial Privacy Protection
Yuhao Sun, Lingyun Yu, Hongtao Xie, Jiaming Li, Yongdong Zhang
0
0
With the rapid development of face recognition (FR) systems, the privacy of face images on social media is facing severe challenges due to the abuse of unauthorized FR systems. Some studies utilize adversarial attack techniques to defend against malicious FR systems by generating adversarial examples. However, the generated adversarial examples, i.e., the protected face images, tend to suffer from subpar visual quality and low transferability. In this paper, we propose a novel face protection approach, dubbed DiffAM, which leverages the powerful generative ability of diffusion models to generate high-quality protected face images with adversarial makeup transferred from reference images. To be specific, we first introduce a makeup removal module to generate non-makeup images utilizing a fine-tuned diffusion model with guidance of textual prompts in CLIP space. As the inverse process of makeup transfer, makeup removal can make it easier to establish the deterministic relationship between makeup domain and non-makeup domain regardless of elaborate text prompts. Then, with this relationship, a CLIP-based makeup loss along with an ensemble attack strategy is introduced to jointly guide the direction of adversarial makeup domain, achieving the generation of protected face images with natural-looking makeup and high black-box transferability. Extensive experiments demonstrate that DiffAM achieves higher visual quality and attack success rates with a gain of 12.98% under black-box setting compared with the state of the arts. The code will be available at https://github.com/HansSunY/DiffAM.
5/17/2024