Elastic Interaction Energy-Informed Real-Time Traffic Scene Perception
2310.01449
0
0

Abstract
Urban segmentation and lane detection are two important tasks for traffic scene perception. Accuracy and fast inference speed of visual perception are crucial for autonomous driving safety. Fine and complex geometric objects are the most challenging but important recognition targets in traffic scene, such as pedestrians, traffic signs and lanes. In this paper, a simple and efficient topology-aware energy loss function-based network training strategy named EIEGSeg is proposed. EIEGSeg is designed for multi-class segmentation on real-time traffic scene perception. To be specific, the convolutional neural network (CNN) extracts image features and produces multiple outputs, and the elastic interaction energy loss function (EIEL) drives the predictions moving toward the ground truth until they are completely overlapped. Our strategy performs well especially on fine-scale structure, textit{i.e.} small or irregularly shaped objects can be identified more accurately, and discontinuity issues on slender objects can be improved. We quantitatively and qualitatively analyze our method on three traffic datasets, including urban scene segmentation data Cityscapes and lane detection data TuSimple and CULane. Our results demonstrate that EIEGSeg consistently improves the performance, especially on real-time, lightweight networks that are better suited for autonomous driving.
Create account to get full access
Overview
- This paper proposes a new method called "Elastic Interaction Energy Loss" for improving the performance of semantic image segmentation, which is the task of accurately identifying and labeling different objects and regions within an image.
- The authors focus on applying this method to traffic scenes, where accurate segmentation is crucial for applications like self-driving cars and traffic monitoring.
- The key idea is to incorporate a new loss function that encourages the neural network model to learn semantic boundaries that are smooth and coherent, rather than jagged or fragmented.
Plain English Explanation
The researchers are working on a problem called semantic image segmentation. This means taking an image and automatically identifying and labeling all the different objects and regions in it, like cars, pedestrians, roads, buildings, etc. This is an important task for applications like self-driving cars, where the car needs to understand its surroundings in detail.
The main challenge is that the boundaries between different objects in an image are often blurry or irregular, which can confuse the machine learning models and lead to inaccurate segmentation. The researchers propose a new approach to address this. They add a special "energy loss" term to the training process that encourages the model to learn smooth, coherent boundaries between different semantic regions.
Imagine you're trying to draw a map of a city by looking at an aerial photo. If you just draw the outlines of each building, road, and park as you see them, the resulting map will have a lot of jagged edges and irregular shapes. But if you try to "smooth out" those boundaries a bit, the map will look cleaner and more natural. That's the key idea behind the Elastic Interaction Energy Loss approach - it helps the model learn to draw those semantic boundaries in a more natural, coherent way.
The researchers show that this approach leads to better performance on standard traffic scene segmentation benchmarks, compared to other state-of-the-art methods. The resulting segmentation maps have cleaner, more realistic-looking boundaries that are better aligned with the actual structures in the image.
Technical Explanation
The paper introduces a new loss function called "Elastic Interaction Energy Loss" (EIEL) that can be integrated into existing semantic segmentation architectures to improve their performance.
The core idea is to incorporate a term that encourages the model to learn smooth, coherent semantic boundaries, rather than jagged or fragmented ones. This is achieved by modeling the interaction between neighboring pixels in the segmentation output as an "elastic" system, where pixels exert attractive and repulsive forces on each other based on their semantic labels.
The EIEL loss term is designed to minimize the "energy" of this elastic system, which corresponds to having clean, well-defined boundaries between different semantic regions. This is in contrast to other common segmentation loss functions, which focus more on accurately classifying each individual pixel without explicitly modeling the relationships between neighboring pixels.
The authors evaluate their approach on several standard traffic scene segmentation benchmarks, including Cityscapes and BDD100K. They show that incorporating EIEL into popular segmentation architectures like DeepLabV3+ and Semantic FPN leads to consistent improvements in segmentation accuracy, as measured by standard metrics like mean Intersection-over-Union (mIoU).
The segmentation maps produced by the EIEL-enhanced models exhibit smoother, more realistic-looking boundaries between different semantic regions, better capturing the underlying structure of the traffic scenes. This suggests that the EIEL loss function is effective at encouraging the model to learn more coherent and meaningful semantic representations.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed EIEL loss function, with experiments on multiple standard benchmarks and comparisons to state-of-the-art segmentation methods. The results demonstrate clear performance improvements, validating the core idea behind the approach.
However, the paper does not delve deeply into the limitations or potential issues with the EIEL method. For example, it would be valuable to understand how the approach might scale to more complex scenes beyond traffic scenarios, or how it might handle challenging cases like occlusions or ambiguous boundaries.
Additionally, the paper could have provided more insight into the internal workings of the EIEL loss function, such as how the specific formulation of the "elastic interaction" term affects the learned segmentation boundaries. A more detailed analysis of the failure cases or edge cases where the method struggles could also help readers better understand its strengths and weaknesses.
Overall, the research presented in this paper represents a solid contribution to the field of semantic image segmentation, with the EIEL loss function offering a promising new approach for improving the coherence and realism of segmentation outputs. Further exploration of the method's broader applicability and robustness would be valuable for the community.
Conclusion
This paper introduces a novel loss function called Elastic Interaction Energy Loss (EIEL) that can be used to enhance the performance of semantic image segmentation models, particularly in the context of traffic scenes. The key idea is to incorporate a term that encourages the model to learn smooth, coherent boundaries between different semantic regions, rather than jagged or fragmented ones.
The authors demonstrate that integrating EIEL into popular segmentation architectures leads to consistent improvements in segmentation accuracy, as measured by standard metrics. The resulting segmentation maps exhibit cleaner, more realistic-looking boundaries that better capture the underlying structure of the traffic scenes.
This work represents an important contribution to the field of semantic image segmentation, offering a new approach to improving the coherence and realism of segmentation outputs. While the paper focuses on traffic scenes, the EIEL loss function could potentially be applicable to a wider range of segmentation tasks, and further research is needed to explore its broader capabilities and limitations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ElasticLaneNet: An Efficient Geometry-Flexible Approach for Lane Detection
Yaxin Feng, Yuan Lan, Luchan Zhang, Yang Xiang
0
0
The task of lane detection involves identifying the boundaries of driving areas in real-time. Recognizing lanes with variable and complex geometric structures remains a challenge. In this paper, we explore a novel and flexible way of implicit lanes representation named textit{Elastic Lane map (ELM)}, and introduce an efficient physics-informed end-to-end lane detection framework, namely, ElasticLaneNet (Elastic interaction energy-informed Lane detection Network). The approach considers predicted lanes as moving zero-contours on the flexibly shaped textit{ELM} that are attracted to the ground truth guided by an elastic interaction energy-loss function (EIE loss). Our framework well integrates the global information and low-level features. The method performs well in complex lane scenarios, including those with large curvature, weak geometry features at intersections, complicated cross lanes, Y-shapes lanes, dense lanes, etc. We apply our approach on three datasets: SDLane, CULane, and TuSimple. The results demonstrate exceptional performance of our method, with the state-of-the-art results on the structurally diverse SDLane, achieving F1-score of 89.51, Recall rate of 87.50, and Precision of 91.61 with fast inference speed.
4/4/2024
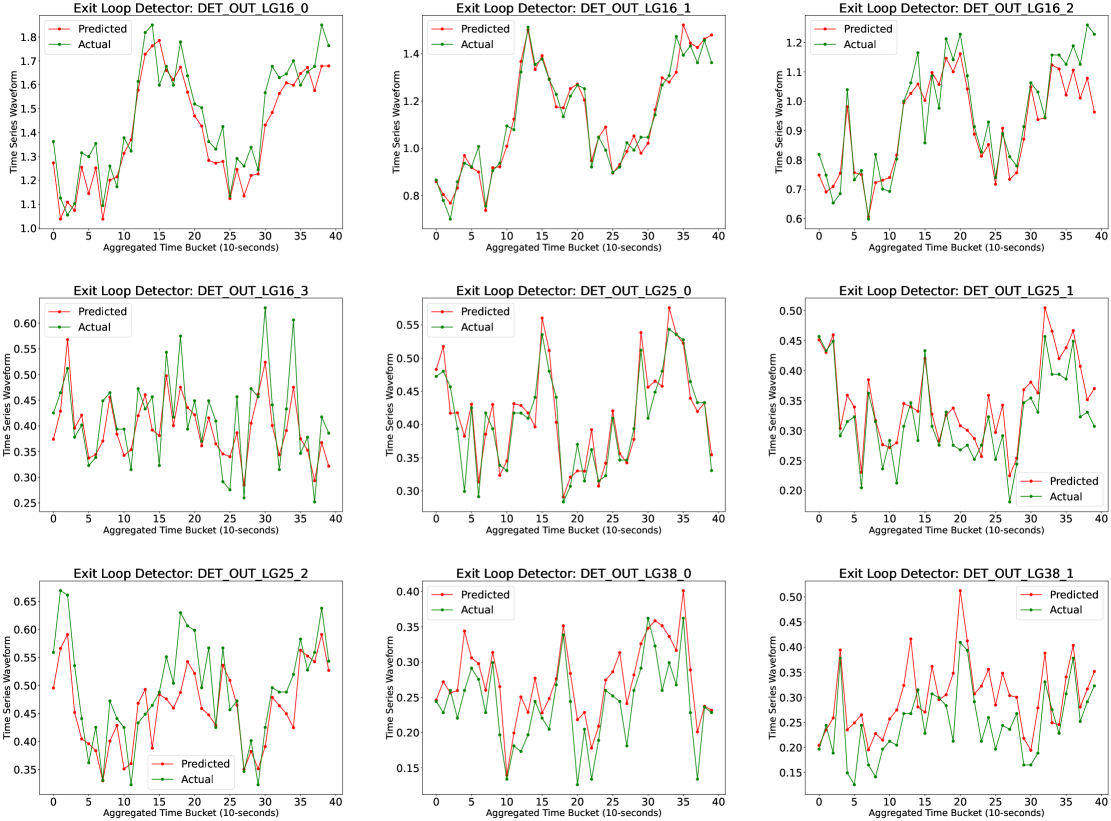
Graph Attention Network for Lane-Wise and Topology-Invariant Intersection Traffic Simulation
Nooshin Yousefzadeh, Rahul Sengupta, Yashaswi Karnati, Anand Rangarajan, Sanjay Ranka
0
0
Traffic congestion has significant economic, environmental, and social ramifications. Intersection traffic flow dynamics are influenced by numerous factors. While microscopic traffic simulators are valuable tools, they are computationally intensive and challenging to calibrate. Moreover, existing machine-learning approaches struggle to provide lane-specific waveforms or adapt to intersection topology and traffic patterns. In this study, we propose two efficient and accurate Digital Twin models for intersections, leveraging Graph Attention Neural Networks (GAT). These attentional graph auto-encoder digital twins capture temporal, spatial, and contextual aspects of traffic within intersections, incorporating various influential factors such as high-resolution loop detector waveforms, signal state records, driving behaviors, and turning-movement counts. Trained on diverse counterfactual scenarios across multiple intersections, our models generalize well, enabling the estimation of detailed traffic waveforms for any intersection approach and exit lanes. Multi-scale error metrics demonstrate that our models perform comparably to microsimulations. The primary application of our study lies in traffic signal optimization, a pivotal area in transportation systems research. These lightweight digital twins can seamlessly integrate into corridor and network signal timing optimization frameworks. Furthermore, our study's applications extend to lane reconfiguration, driving behavior analysis, and facilitating informed decisions regarding intersection safety and efficiency enhancements. A promising avenue for future research involves extending this approach to urban freeway corridors and integrating it with measures of effectiveness metrics.
5/3/2024

GraphAD: Interaction Scene Graph for End-to-end Autonomous Driving
Yunpeng Zhang, Deheng Qian, Ding Li, Yifeng Pan, Yong Chen, Zhenbao Liang, Zhiyao Zhang, Shurui Zhang, Hongxu Li, Maolei Fu, Yun Ye, Zhujin Liang, Yi Shan, Dalong Du
0
0
Modeling complicated interactions among the ego-vehicle, road agents, and map elements has been a crucial part for safety-critical autonomous driving. Previous works on end-to-end autonomous driving rely on the attention mechanism for handling heterogeneous interactions, which fails to capture the geometric priors and is also computationally intensive. In this paper, we propose the Interaction Scene Graph (ISG) as a unified method to model the interactions among the ego-vehicle, road agents, and map elements. With the representation of the ISG, the driving agents aggregate essential information from the most influential elements, including the road agents with potential collisions and the map elements to follow. Since a mass of unnecessary interactions are omitted, the more efficient scene-graph-based framework is able to focus on indispensable connections and leads to better performance. We evaluate the proposed method for end-to-end autonomous driving on the nuScenes dataset. Compared with strong baselines, our method significantly outperforms in the full-stack driving tasks, including perception, prediction, and planning. Code will be released at https://github.com/zhangyp15/GraphAD.
4/9/2024
🤔
PreGSU-A Generalized Traffic Scene Understanding Model for Autonomous Driving based on Pre-trained Graph Attention Network
Yuning Wang, Zhiyuan Liu, Haotian Lin, Junkai Jiang, Shaobing Xu, Jianqiang Wang
0
0
Scene understanding, defined as learning, extraction, and representation of interactions among traffic elements, is one of the critical challenges toward high-level autonomous driving (AD). Current scene understanding methods mainly focus on one concrete single task, such as trajectory prediction and risk level evaluation. Although they perform well on specific metrics, the generalization ability is insufficient to adapt to the real traffic complexity and downstream demand diversity. In this study, we propose PreGSU, a generalized pre-trained scene understanding model based on graph attention network to learn the universal interaction and reasoning of traffic scenes to support various downstream tasks. After the feature engineering and sub-graph module, all elements are embedded as nodes to form a dynamic weighted graph. Then, four graph attention layers are applied to learn the relationships among agents and lanes. In the pre-train phase, the understanding model is trained on two self-supervised tasks: Virtual Interaction Force (VIF) modeling and Masked Road Modeling (MRM). Based on the artificial potential field theory, VIF modeling enables PreGSU to capture the agent-to-agent interactions while MRM extracts agent-to-road connections. In the fine-tuning process, the pre-trained parameters are loaded to derive detailed understanding outputs. We conduct validation experiments on two downstream tasks, i.e., trajectory prediction in urban scenario, and intention recognition in highway scenario, to verify the generalized ability and understanding ability. Results show that compared with the baselines, PreGSU achieves better accuracy on both tasks, indicating the potential to be generalized to various scenes and targets. Ablation study shows the effectiveness of pre-train task design.
4/17/2024