Embedded Distributed Inference of Deep Neural Networks: A Systematic Review
2405.03360
0
0
🤯
Abstract
Embedded distributed inference of Neural Networks has emerged as a promising approach for deploying machine-learning models on resource-constrained devices in an efficient and scalable manner. The inference task is distributed across a network of embedded devices, with each device contributing to the overall computation by performing a portion of the workload. In some cases, more powerful devices such as edge or cloud servers can be part of the system to be responsible of the most demanding layers of the network. As the demand for intelligent systems and the complexity of the deployed neural network models increases, this approach is becoming more relevant in a variety of applications such as robotics, autonomous vehicles, smart cities, Industry 4.0 and smart health. We present a systematic review of papers published during the last six years which describe techniques and methods to distribute Neural Networks across these kind of systems. We provide an overview of the current state-of-the-art by analysing more than 100 papers, present a new taxonomy to characterize them, and discuss trends and challenges in the field.
Create account to get full access
Overview
- Explains a promising approach called "embedded distributed inference of Neural Networks" for deploying machine learning models on resource-constrained devices
- Distributes the inference task across a network of embedded devices, with more powerful devices like edge or cloud servers handling the most demanding layers
- Becoming more relevant for applications like robotics, autonomous vehicles, smart cities, Industry 4.0, and smart health as demand for intelligent systems and model complexity increases
Plain English Explanation
The paper discusses a way to run machine learning models on devices with limited computing power, like smartphones or sensors. Instead of running the entire model on a single device, the work is split up and shared across a network of devices. This allows even simple devices to contribute to the overall computation. More powerful devices, like servers at the edge of the network or in the cloud, can handle the most complex parts of the model.
As demand grows for intelligent systems and the neural network models become more sophisticated, this distributed approach is becoming increasingly important for a variety of applications. These include robotics, autonomous vehicles, smart cities, Industry 4.0, and smart health systems. The paper provides a comprehensive review of the techniques and methods used to distribute neural networks across these types of systems.
Technical Explanation
The paper presents a systematic review of over 100 publications from the last six years on techniques and methods for distributing neural network inference across embedded and resource-constrained devices. It provides an overview of the state-of-the-art in this field and proposes a new taxonomy to categorize the different approaches.
The key idea is to split up the computationally intensive task of running a neural network inference across a network of embedded devices, rather than running the entire model on a single device. This allows even resource-limited devices to contribute to the overall computation. In some cases, more powerful edge or cloud servers can be integrated into the system to handle the most demanding layers of the network.
The paper analyzes the various strategies used to partition and distribute the neural network model, the communication protocols employed, and the techniques for optimizing performance and resource utilization. It also covers methods for dynamically managing the deployment of the neural network across the heterogeneous devices based on factors like workload, energy consumption, and latency requirements.
Critical Analysis
The paper provides a comprehensive survey of the current techniques for distributed neural network inference on embedded systems, which is an important and rapidly evolving area of research. However, it does not delve deeply into the specific limitations or tradeoffs of the different approaches.
For example, the paper could have discussed in more detail the challenges around maintaining model accuracy and consistency when partitioning the network across multiple devices. It could have also explored the communication overhead and latency issues that can arise in these distributed setups, and how researchers are addressing them.
Additionally, the paper does not critically assess the broader societal implications of this technology. As intelligent systems become more pervasive in areas like autonomous vehicles and smart health, it will be important to consider the ethical and privacy concerns that may arise from distributing sensitive data and computation across a network of devices.
Conclusion
This paper provides a comprehensive overview of the current state-of-the-art in embedded distributed inference of neural networks. By partitioning the computationally intensive task of running a neural network across a network of devices, this approach allows even resource-constrained systems to benefit from advanced machine learning capabilities.
As the demand for intelligent systems continues to grow, this distributed inference paradigm is becoming increasingly relevant for a wide range of applications, from robotics to smart cities. The paper's comprehensive review and proposed taxonomy provide a useful foundation for further research and development in this important area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
New!Automated Deep Neural Network Inference Partitioning for Distributed Embedded Systems
Fabian Kress, El Mahdi El Annabi, Tim Hotfilter, Julian Hoefer, Tanja Harbaum, Juergen Becker
0
0
Distributed systems can be found in various applications, e.g., in robotics or autonomous driving, to achieve higher flexibility and robustness. Thereby, data flow centric applications such as Deep Neural Network (DNN) inference benefit from partitioning the workload over multiple compute nodes in terms of performance and energy-efficiency. However, mapping large models on distributed embedded systems is a complex task, due to low latency and high throughput requirements combined with strict energy and memory constraints. In this paper, we present a novel approach for hardware-aware layer scheduling of DNN inference in distributed embedded systems. Therefore, our proposed framework uses a graph-based algorithm to automatically find beneficial partitioning points in a given DNN. Each of these is evaluated based on several essential system metrics such as accuracy and memory utilization, while considering the respective system constraints. We demonstrate our approach in terms of the impact of inference partitioning on various performance metrics of six different DNNs. As an example, we can achieve a 47.5 % throughput increase for EfficientNet-B0 inference partitioned onto two platforms while observing high energy-efficiency.
7/1/2024
🧠
Resource-Efficient Neural Networks for Embedded Systems
Wolfgang Roth, Gunther Schindler, Bernhard Klein, Robert Peharz, Sebastian Tschiatschek, Holger Froning, Franz Pernkopf, Zoubin Ghahramani
0
0
While machine learning is traditionally a resource intensive task, embedded systems, autonomous navigation, and the vision of the Internet of Things fuel the interest in resource-efficient approaches. These approaches aim for a carefully chosen trade-off between performance and resource consumption in terms of computation and energy. The development of such approaches is among the major challenges in current machine learning research and key to ensure a smooth transition of machine learning technology from a scientific environment with virtually unlimited computing resources into everyday's applications. In this article, we provide an overview of the current state of the art of machine learning techniques facilitating these real-world requirements. In particular, we focus on resource-efficient inference based on deep neural networks (DNNs), the predominant machine learning models of the past decade. We give a comprehensive overview of the vast literature that can be mainly split into three non-mutually exclusive categories: (i) quantized neural networks, (ii) network pruning, and (iii) structural efficiency. These techniques can be applied during training or as post-processing, and they are widely used to reduce the computational demands in terms of memory footprint, inference speed, and energy efficiency. We also briefly discuss different concepts of embedded hardware for DNNs and their compatibility with machine learning techniques as well as potential for energy and latency reduction. We substantiate our discussion with experiments on well-known benchmark data sets using compression techniques (quantization, pruning) for a set of resource-constrained embedded systems, such as CPUs, GPUs and FPGAs. The obtained results highlight the difficulty of finding good trade-offs between resource efficiency and prediction quality.
4/9/2024
A Survey of Distributed Learning in Cloud, Mobile, and Edge Settings
Madison Threadgill, Andreas Gerstlauer
0
0
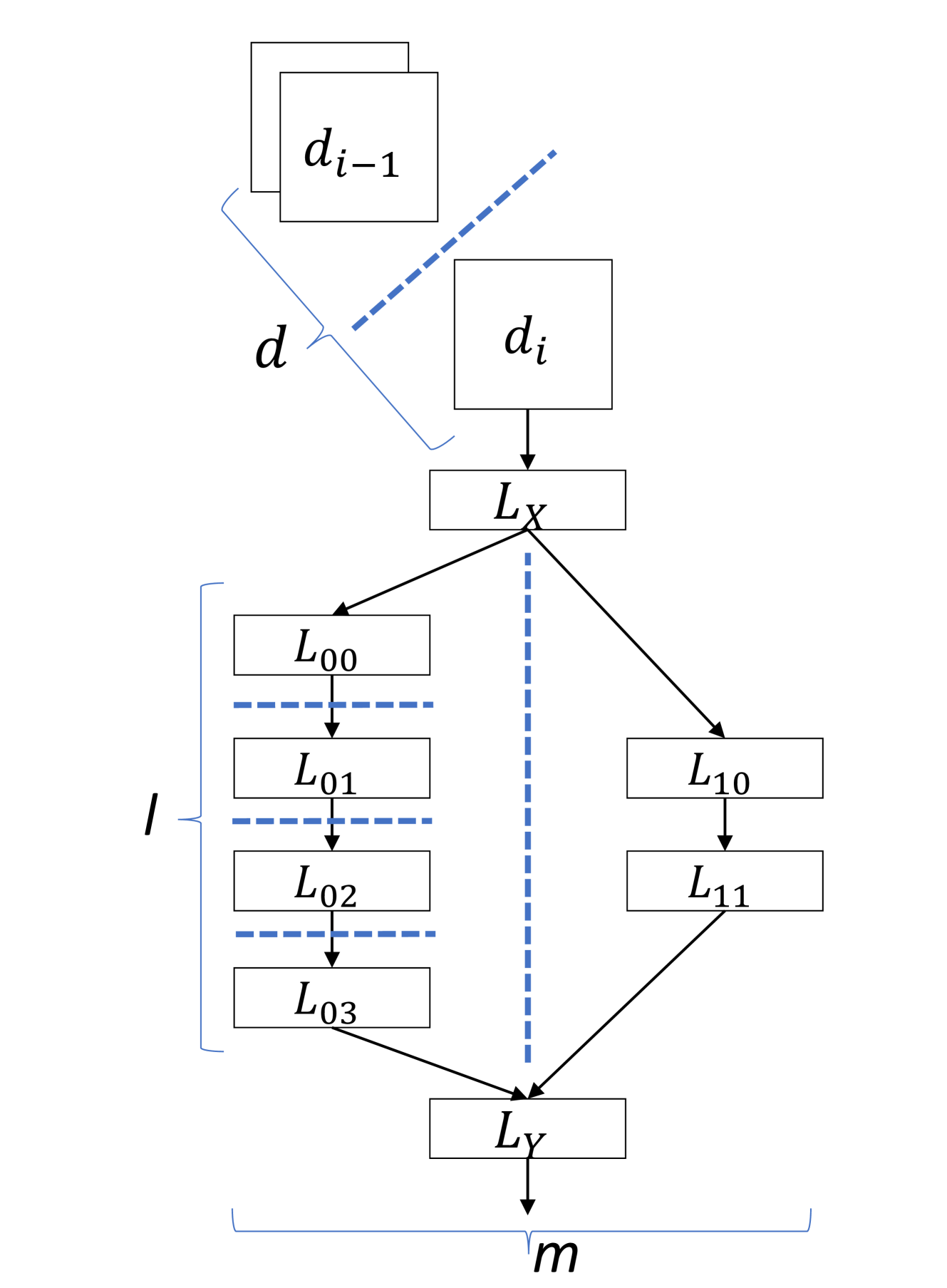
In the era of deep learning (DL), convolutional neural networks (CNNs), and large language models (LLMs), machine learning (ML) models are becoming increasingly complex, demanding significant computational resources for both inference and training stages. To address this challenge, distributed learning has emerged as a crucial approach, employing parallelization across various devices and environments. This survey explores the landscape of distributed learning, encompassing cloud and edge settings. We delve into the core concepts of data and model parallelism, examining how models are partitioned across different dimensions and layers to optimize resource utilization and performance. We analyze various partitioning schemes for different layer types, including fully connected, convolutional, and recurrent layers, highlighting the trade-offs between computational efficiency, communication overhead, and memory constraints. This survey provides valuable insights for future research and development in this rapidly evolving field by comparing and contrasting distributed learning approaches across diverse contexts.
5/27/2024
Resource-aware Deployment of Dynamic DNNs over Multi-tiered Interconnected Systems
Chetna Singhal, Yashuo Wu, Francesco Malandrino, Marco Levorato, Carla Fabiana Chiasserini
0
0
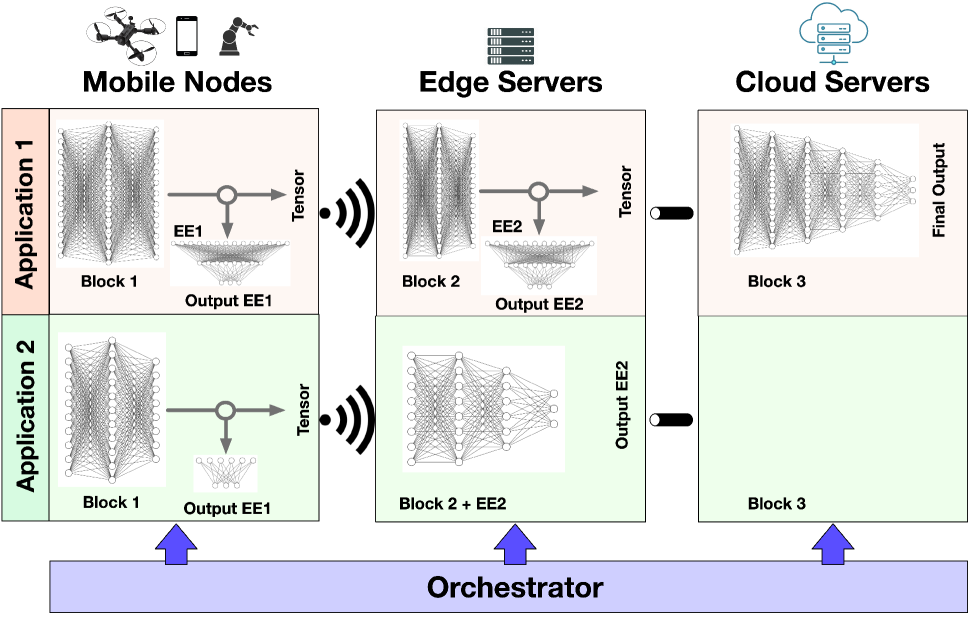
The increasing pervasiveness of intelligent mobile applications requires to exploit the full range of resources offered by the mobile-edge-cloud network for the execution of inference tasks. However, due to the heterogeneity of such multi-tiered networks, it is essential to make the applications' demand amenable to the available resources while minimizing energy consumption. Modern dynamic deep neural networks (DNN) achieve this goal by designing multi-branched architectures where early exits enable sample-based adaptation of the model depth. In this paper, we tackle the problem of allocating sections of DNNs with early exits to the nodes of the mobile-edge-cloud system. By envisioning a 3-stage graph-modeling approach, we represent the possible options for splitting the DNN and deploying the DNN blocks on the multi-tiered network, embedding both the system constraints and the application requirements in a convenient and efficient way. Our framework -- named Feasible Inference Graph (FIN) -- can identify the solution that minimizes the overall inference energy consumption while enabling distributed inference over the multi-tiered network with the target quality and latency. Our results, obtained for DNNs with different levels of complexity, show that FIN matches the optimum and yields over 65% energy savings relative to a state-of-the-art technique for cost minimization.
4/15/2024