Embedded Representation Learning Network for Animating Styled Video Portrait
2404.19038
0
0
🌐
Abstract
The talking head generation recently attracted considerable attention due to its widespread application prospects, especially for digital avatars and 3D animation design. Inspired by this practical demand, several works explored Neural Radiance Fields (NeRF) to synthesize the talking heads. However, these methods based on NeRF face two challenges: (1) Difficulty in generating style-controllable talking heads. (2) Displacement artifacts around the neck in rendered images. To overcome these two challenges, we propose a novel generative paradigm textit{Embedded Representation Learning Network} (ERLNet) with two learning stages. First, the textit{ audio-driven FLAME} (ADF) module is constructed to produce facial expression and head pose sequences synchronized with content audio and style video. Second, given the sequence deduced by the ADF, one novel textit{dual-branch fusion NeRF} (DBF-NeRF) explores these contents to render the final images. Extensive empirical studies demonstrate that the collaboration of these two stages effectively facilitates our method to render a more realistic talking head than the existing algorithms.
Create account to get full access
Overview
- Introduces a new neural rendering framework called DBF-NeRF for generating high-quality 3D-aware stylized portraits
- Proposes a dual-branch neural network architecture that combines a head pose estimation branch with a neural radiance field (NeRF) branch for 3D rendering
- Demonstrates state-of-the-art results on several 3D-aware stylized portrait synthesis tasks, including ArtNeRF, GaussianTalker, Talk3D, and Learn2Talk
Plain English Explanation
The paper presents a new framework called DBF-NeRF for generating high-quality 3D-aware stylized portraits. The key idea is to combine a head pose estimation branch with a neural radiance field (NeRF) branch to capture both the 3D structure and the desired artistic style.
The head pose branch estimates the position and orientation of the subject's head from the input image. This 6D head pose information is then fed into the NeRF branch, which uses it to render a 3D representation of the portrait with the desired artistic style, such as a cartoonized or painted look.
By jointly optimizing these two branches, the model is able to produce 3D-aware stylized portraits that are both realistic and visually appealing. The authors demonstrate state-of-the-art results on several benchmarks, including ArtNeRF, GaussianTalker, Talk3D, and Learn2Talk.
This work represents an important advance in the field of 3D-aware stylized portrait synthesis, which has numerous applications in areas like animation, virtual reality, and personalized communication.
Technical Explanation
The key components of the DBF-NeRF framework are:
-
Head Pose Estimation Branch: This branch takes the input image and predicts the 6D head pose (3D position and 3D orientation) of the subject. This is accomplished using a neural network architecture similar to existing head pose estimation models.
-
NeRF Rendering Branch: This branch takes the predicted head pose and uses it to render a 3D stylized portrait of the subject. It does this by leveraging the neural radiance field (NeRF) representation, which can model complex 3D scenes and apply artistic styles in a differentiable manner.
-
Joint Optimization: The two branches are trained jointly, with the head pose branch providing crucial 3D information to the NeRF branch, and the NeRF branch providing high-quality 3D-aware stylized rendering to the head pose branch. This joint optimization allows the model to learn an optimal balance between accurate head pose estimation and high-quality 3D stylized portrait synthesis.
The authors evaluate the DBF-NeRF framework on several benchmarks, including ArtNeRF, GaussianTalker, Talk3D, and Learn2Talk. The results demonstrate that the DBF-NeRF framework outperforms existing state-of-the-art methods in terms of both 3D reconstruction accuracy and stylized rendering quality.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the DBF-NeRF framework, including comparisons to several state-of-the-art methods on relevant benchmarks. The authors acknowledge some limitations, such as the need for high-quality 3D head pose annotations during training, and suggest areas for future research, such as extending the framework to handle full-body poses and incorporating additional artistic styles.
One potential concern is the computational complexity of the joint optimization process, which may limit the real-time performance of the system. Additionally, the paper does not discuss the robustness of the framework to variations in input data, such as different lighting conditions, occlusions, or diverse head poses.
Overall, the DBF-NeRF framework represents a significant contribution to the field of 3D-aware stylized portrait synthesis, with promising results and interesting avenues for future research. The combination of head pose estimation and neural radiance field rendering is a clever approach that could inspire further innovations in this area.
Conclusion
The DBF-NeRF framework introduced in this paper represents an important step forward in the field of 3D-aware stylized portrait synthesis. By jointly optimizing head pose estimation and neural radiance field rendering, the model is able to generate high-quality 3D-aware stylized portraits that outperform existing state-of-the-art methods.
This work has numerous potential applications, from virtual reality and animation to personalized communication and digital art. While the current framework has some limitations, the authors have outlined several promising directions for future research, such as extending the model to handle full-body poses and incorporating a wider range of artistic styles.
Overall, the DBF-NeRF framework is a significant contribution to the field, and its impact is likely to be felt across a wide range of industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
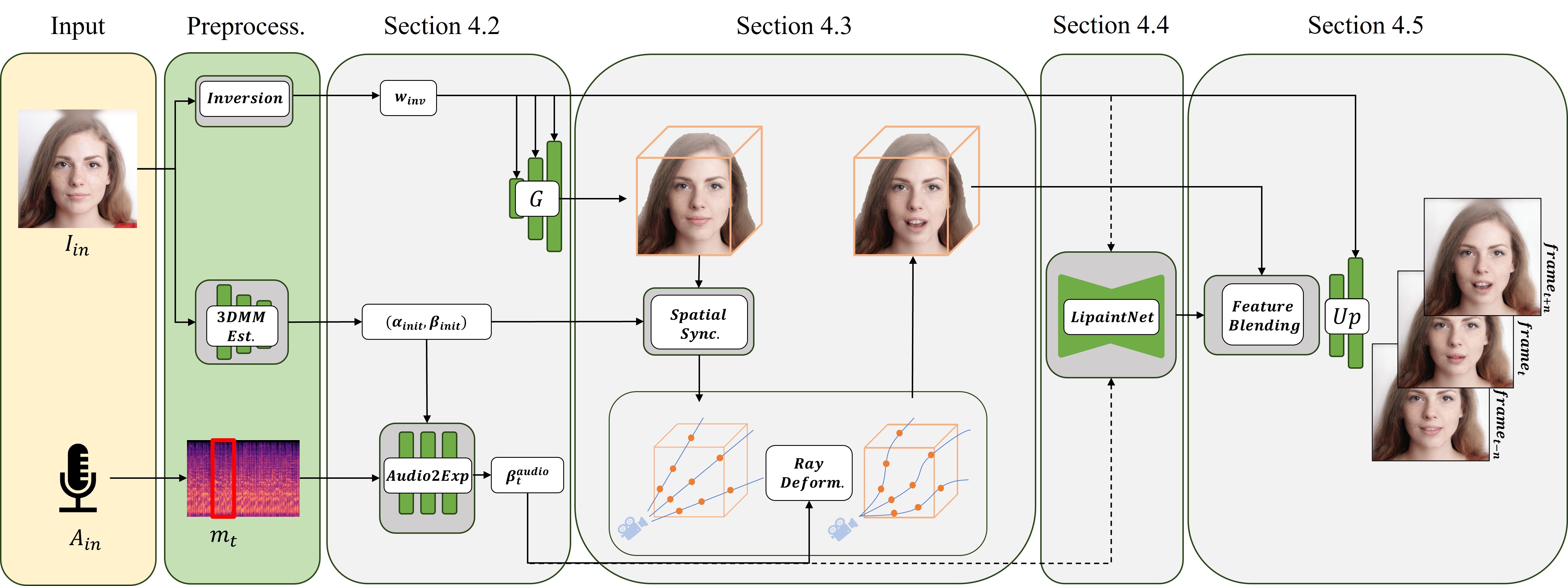
NeRFFaceSpeech: One-shot Audio-diven 3D Talking Head Synthesis via Generative Prior
Gihoon Kim, Kwanggyoon Seo, Sihun Cha, Junyong Noh
0
0
Audio-driven talking head generation is advancing from 2D to 3D content. Notably, Neural Radiance Field (NeRF) is in the spotlight as a means to synthesize high-quality 3D talking head outputs. Unfortunately, this NeRF-based approach typically requires a large number of paired audio-visual data for each identity, thereby limiting the scalability of the method. Although there have been attempts to generate audio-driven 3D talking head animations with a single image, the results are often unsatisfactory due to insufficient information on obscured regions in the image. In this paper, we mainly focus on addressing the overlooked aspect of 3D consistency in the one-shot, audio-driven domain, where facial animations are synthesized primarily in front-facing perspectives. We propose a novel method, NeRFFaceSpeech, which enables to produce high-quality 3D-aware talking head. Using prior knowledge of generative models combined with NeRF, our method can craft a 3D-consistent facial feature space corresponding to a single image. Our spatial synchronization method employs audio-correlated vertex dynamics of a parametric face model to transform static image features into dynamic visuals through ray deformation, ensuring realistic 3D facial motion. Moreover, we introduce LipaintNet that can replenish the lacking information in the inner-mouth area, which can not be obtained from a given single image. The network is trained in a self-supervised manner by utilizing the generative capabilities without additional data. The comprehensive experiments demonstrate the superiority of our method in generating audio-driven talking heads from a single image with enhanced 3D consistency compared to previous approaches. In addition, we introduce a quantitative way of measuring the robustness of a model against pose changes for the first time, which has been possible only qualitatively.
5/13/2024
🛸
Listen, Disentangle, and Control: Controllable Speech-Driven Talking Head Generation
Changpeng Cai, Guinan Guo, Jiao Li, Junhao Su, Chenghao He, Jing Xiao, Yuanxu Chen, Lei Dai, Feiyu Zhu
0
0
Most earlier investigations on talking face generation have focused on the synchronization of lip motion and speech content. However, human head pose and facial emotions are equally important characteristics of natural human faces. While audio-driven talking face generation has seen notable advancements, existing methods either overlook facial emotions or are limited to specific individuals and cannot be applied to arbitrary subjects. In this paper, we propose a one-shot Talking Head Generation framework (SPEAK) that distinguishes itself from general Talking Face Generation by enabling emotional and postural control. Specifically, we introduce the Inter-Reconstructed Feature Disentanglement (IRFD) method to decouple human facial features into three latent spaces. We then design a face editing module that modifies speech content and facial latent codes into a single latent space. Subsequently, we present a novel generator that employs modified latent codes derived from the editing module to regulate emotional expression, head poses, and speech content in synthesizing facial animations. Extensive trials demonstrate that our method can generate realistic talking head with coordinated lip motions, authentic facial emotions, and smooth head movements. The demo video is available at the anonymous link: https://anonymous.4open.science/r/SPEAK-F56E
5/14/2024
🧠
NLDF: Neural Light Dynamic Fields for Efficient 3D Talking Head Generation
Niu Guanchen
0
0
Talking head generation based on the neural radiation fields model has shown promising visual effects. However, the slow rendering speed of NeRF seriously limits its application, due to the burdensome calculation process over hundreds of sampled points to synthesize one pixel. In this work, a novel Neural Light Dynamic Fields model is proposed aiming to achieve generating high quality 3D talking face with significant speedup. The NLDF represents light fields based on light segments, and a deep network is used to learn the entire light beam's information at once. In learning the knowledge distillation is applied and the NeRF based synthesized result is used to guide the correct coloration of light segments in NLDF. Furthermore, a novel active pool training strategy is proposed to focus on high frequency movements, particularly on the speaker mouth and eyebrows. The propose method effectively represents the facial light dynamics in 3D talking video generation, and it achieves approximately 30 times faster speed compared to state of the art NeRF based method, with comparable generation visual quality.
6/18/2024

Emotional Conversation: Empowering Talking Faces with Cohesive Expression, Gaze and Pose Generation
Jiadong Liang, Feng Lu
0
0
Vivid talking face generation holds immense potential applications across diverse multimedia domains, such as film and game production. While existing methods accurately synchronize lip movements with input audio, they typically ignore crucial alignments between emotion and facial cues, which include expression, gaze, and head pose. These alignments are indispensable for synthesizing realistic videos. To address these issues, we propose a two-stage audio-driven talking face generation framework that employs 3D facial landmarks as intermediate variables. This framework achieves collaborative alignment of expression, gaze, and pose with emotions through self-supervised learning. Specifically, we decompose this task into two key steps, namely speech-to-landmarks synthesis and landmarks-to-face generation. The first step focuses on simultaneously synthesizing emotionally aligned facial cues, including normalized landmarks that represent expressions, gaze, and head pose. These cues are subsequently reassembled into relocated facial landmarks. In the second step, these relocated landmarks are mapped to latent key points using self-supervised learning and then input into a pretrained model to create high-quality face images. Extensive experiments on the MEAD dataset demonstrate that our model significantly advances the state-of-the-art performance in both visual quality and emotional alignment.
6/13/2024