Encoder-Quantization-Motion-based Video Quality Metrics
2404.06620
0
0
Abstract
In an adaptive bitrate streaming application, the efficiency of video compression and the encoded video quality depend on both the video codec and the quality metric used to perform encoding optimization. The development of such a quality metric need large scale subjective datasets. In this work we merge several datasets into one to support the creation of a metric tailored for video compression and scaling. We proposed a set of HEVC lightweight features to boost performance of the metrics. Our metrics can be computed from tightly coupled encoding process with 4% compute overhead or from the decoding process in real-time. The proposed method can achieve better correlation than VMAF and P.1204.3. It can extrapolate to different dynamic ranges, and is suitable for real-time video quality metrics delivery in the bitstream. The performance is verified by in-distribution and cross-dataset tests. This work paves the way for adaptive client-side heuristics, real-time segment optimization, dynamic bitrate capping, and quality-dependent post-processing neural network switching, etc.
Create account to get full access
Overview
- This paper proposes new video quality metrics that take into account encoder parameters, quantization, and motion vectors.
- The authors evaluate these metrics on various video datasets and compare them to existing video quality assessment methods.
- The goal is to develop metrics that can better predict video quality, particularly for modern video coding standards like HEVC.
Plain English Explanation
The paper is focused on improving ways to measure the quality of video. Traditionally, video quality has been assessed using metrics that look at factors like pixel differences between the original and compressed video. However, the authors argue that these existing metrics don't fully capture the complex factors that influence video quality, especially for newer video compression technologies.
To address this, the researchers propose some new video quality metrics that also take into account the settings used by the video encoder, the level of quantization applied, and the motion vectors in the video. The idea is that these additional factors can provide a more comprehensive picture of what's happening to the video and how that impacts the perceived quality.
The paper then evaluates these new metrics on several different video datasets and compares their performance to existing quality assessment methods. The goal is to show that the new metrics can better predict the actual video quality as experienced by viewers, especially for the latest video compression standards like HEVC.
Technical Explanation
The authors start by reviewing related work on video quality metrics, noting the limitations of existing approaches that focus solely on pixel-level differences [1,2,3]. They propose three new metrics that incorporate additional information from the video encoding process:
-
Encoder-based metric: This looks at settings used by the video encoder, such as the quantization parameter, to estimate the level of compression and quality degradation.
-
Quantization-based metric: This metric directly measures the impact of the quantization process on video quality.
-
Motion-based metric: This considers the motion vectors generated during video compression to assess the fidelity of motion portrayal.
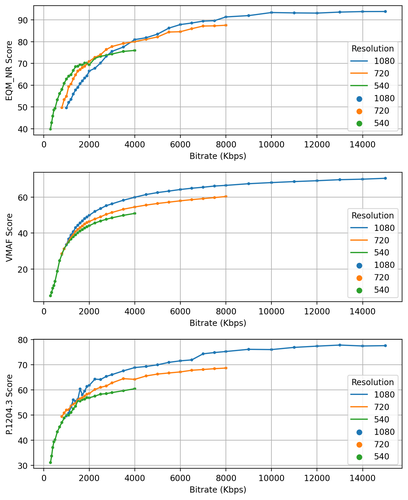
The authors evaluate these new metrics on several video quality datasets, including LIVE-VQC, CVD2014, and SJTU-4K. They compare the performance to existing metrics like PSNR, SSIM, and MS-SSIM. The results show that the proposed metrics, particularly when combined, can outperform the traditional approaches in predicting subjective video quality scores.
Critical Analysis
The key strength of this work is the recognition that modern video coding techniques require more sophisticated quality assessment methods beyond simple pixel-level comparisons. By incorporating encoder parameters, quantization, and motion information, the proposed metrics offer a more holistic view of video quality.
However, the paper does not deeply explore the limitations of the new metrics. For example, it's unclear how they would perform for different types of content (e.g. fast-paced sports vs. static scenes) or variations in network conditions. There's also no discussion of the computational complexity of the new metrics and whether they could be efficiently implemented in real-world video applications.
Additionally, the paper could have benefited from a more thorough exploration of the relationships between the individual metrics and how they interact. For instance, it's not clear how the encoder-based, quantization-based, and motion-based metrics complement or potentially overlap with each other.
Overall, this work represents a valuable step forward in video quality assessment, but there remains room for further research to fully understand the strengths, weaknesses, and practical implications of the proposed metrics.
Conclusion
This paper presents a novel approach to video quality assessment that goes beyond traditional pixel-based metrics. By incorporating information about the video encoder, quantization, and motion, the authors develop new metrics that can better predict subjective video quality, especially for modern compression standards like HEVC.
While the results are promising, the work also highlights the need for continued research to fully understand the capabilities and limitations of these new metrics. Exploring their performance in a wider range of scenarios and studying the interplay between the different components could lead to further advancements in this important area of video technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
Parameter-Efficient Instance-Adaptive Neural Video Compression
Hyunmo Yang, Seungjun Oh, Eunbyung Park
0
0
Learning-based Neural Video Codecs (NVCs) have emerged as a compelling alternative to the standard video codecs, demonstrating promising performance, and simple and easily maintainable pipelines. However, NVCs often fall short of compression performance and occasionally exhibit poor generalization capability due to inference-only compression scheme and their dependence on training data. The instance-adaptive video compression techniques have recently been suggested as a viable solution, fine-tuning the encoder or decoder networks for a particular test instance video. However, fine-tuning all the model parameters incurs high computational costs, increases the bitrates, and often leads to unstable training. In this work, we propose a parameter-efficient instance-adaptive video compression framework. Inspired by the remarkable success of parameter-efficient fine-tuning on large-scale neural network models, we propose to use a lightweight adapter module that can be easily attached to the pretrained NVCs and fine-tuned for test video sequences. The resulting algorithm significantly improves compression performance and reduces the encoding time compared to the existing instant-adaptive video compression algorithms. Furthermore, the suggested fine-tuning method enhances the robustness of the training process, allowing for the proposed method to be widely used in many practical settings. We conducted extensive experiments on various standard benchmark datasets, including UVG, MCL-JVC, and HEVC sequences, and the experimental results have shown a significant improvement in rate-distortion (RD) curves (up to 5 dB PSNR improvements) and BD rates compared to the baselines NVC. Our code is available on https://github.com/ohsngjun/PEVC}{https://github.com/ohsngjun/PEVC.
6/12/2024
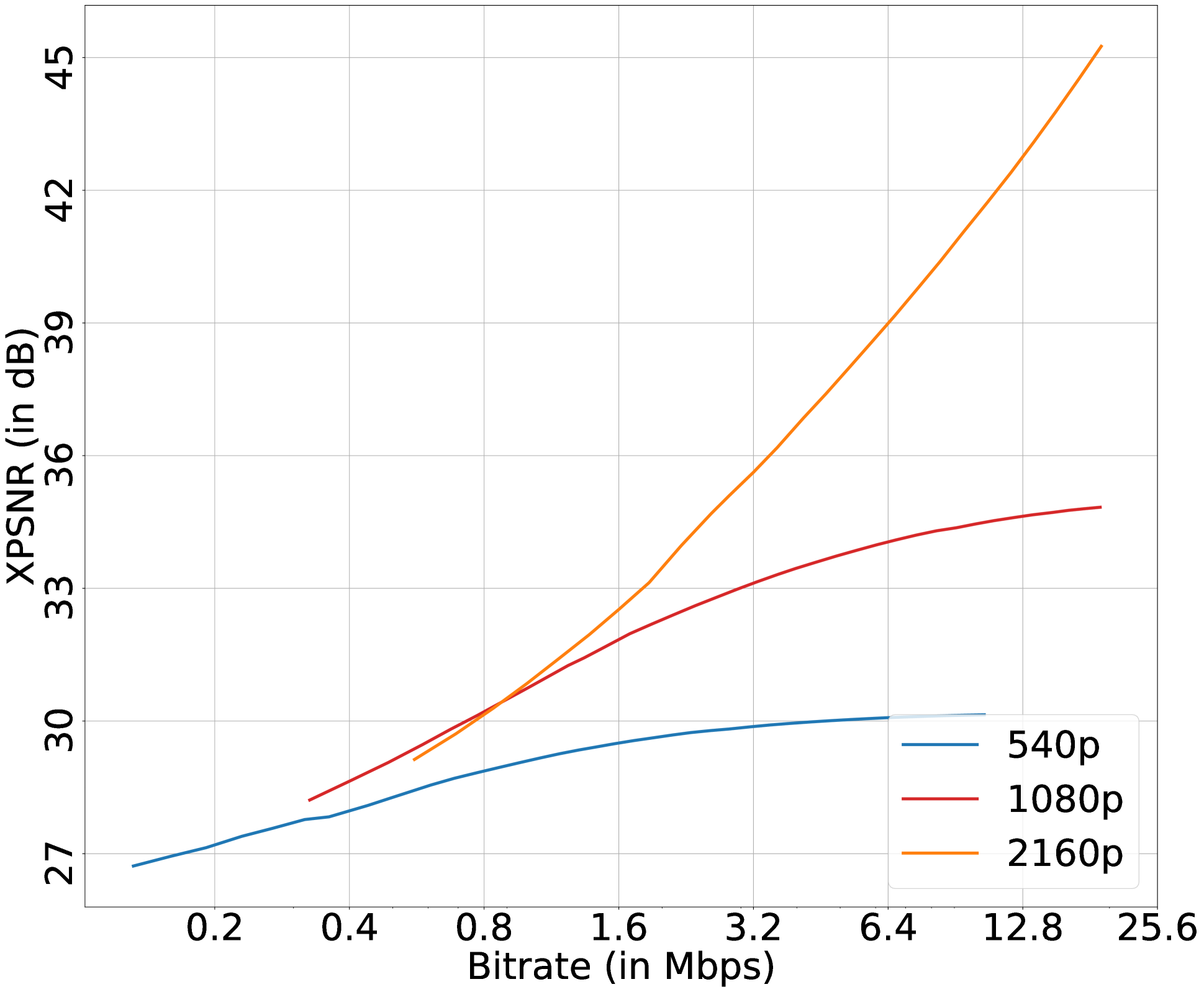
Convex-hull Estimation using XPSNR for Versatile Video Coding
Vignesh V Menon, Christian R. Helmrich, Adam Wieckowski, Benjamin Bross, Detlev Marpe
0
0
As adaptive streaming becomes crucial for delivering high-quality video content across diverse network conditions, accurate metrics to assess perceptual quality are essential. This paper explores using the eXtended Peak Signal-to-Noise Ratio (XPSNR) metric as an alternative to the popular Video Multimethod Assessment Fusion (VMAF) metric for determining optimized bitrate-resolution pairs in the context of Versatile Video Coding (VVC). Our study is rooted in the observation that XPSNR shows a superior correlation with subjective quality scores for VVC-coded Ultra-High Definition (UHD) content compared to VMAF. We predict the average XPSNR of VVC-coded bitstreams using spatiotemporal complexity features of the video and the target encoding configuration and then determine the convex-hull online. On average, the proposed convex-hull using XPSNR (VEXUS) achieves an overall quality improvement of 5.84 dB PSNR and 0.62 dB XPSNR while maintaining the same bitrate, compared to the default UHD encoding using the VVenC encoder, accompanied by an encoding time reduction of 44.43% and a decoding time reduction of 65.46%. This shift towards XPSNR as a guiding metric shall enhance the effectiveness of adaptive streaming algorithms, ensuring an optimal balance between bitrate efficiency and perceptual fidelity with advanced video coding standards.
6/21/2024

Video Compression Beyond VVC: Quantitative Analysis of Intra Coding Tools in Enhanced Compression Model (ECM)
Mohsen Abdoli, Ramin G. Youvalari, Karam Naser, Kevin Reuz'e, Fabrice Le L'eannec
0
0
A quantitative analysis of post-VVC luma and chroma intra tools is presented, focusing on their statistical behaviors, in terms of block selection rate under different conditions. The aim is to provide insights to the standardization community, offering a clearer understanding of interactions between tools and assisting in the design of an optimal combination of these novel tools when the JVET enters the standardization phase. Specifically, this paper examines the selection rate of intra tools as function of 1) the version of the ECM, 2) video resolution, and 3) video bitrate. Additionally, tests have been conducted on sequences beyond the JVET CTC database. The statistics show several trends and interactions, with various strength, between coding tools of both luma and chroma.
4/12/2024
I$^2$VC: A Unified Framework for Intra- & Inter-frame Video Compression
Meiqin Liu, Chenming Xu, Yukai Gu, Chao Yao, Yao Zhao
0
0
Video compression aims to reconstruct seamless frames by encoding the motion and residual information from existing frames. Previous neural video compression methods necessitate distinct codecs for three types of frames (I-frame, P-frame and B-frame), which hinders a unified approach and generalization across different video contexts. Intra-codec techniques lack the advanced Motion Estimation and Motion Compensation (MEMC) found in inter-codec, leading to fragmented frameworks lacking uniformity. Our proposed Intra- & Inter-frame Video Compression (I$^2$VC) framework employs a single spatio-temporal codec that guides feature compression rates according to content importance. This unified codec transforms the dependence across frames into a conditional coding scheme, thus integrating intra- and inter-frame compression into one cohesive strategy. Given the absence of explicit motion data, achieving competent inter-frame compression with only a conditional codec poses a challenge. To resolve this, our approach includes an implicit inter-frame alignment mechanism. With the pre-trained diffusion denoising process, the utilization of a diffusion-inverted reference feature rather than random noise supports the initial compression state. This process allows for selective denoising of motion-rich regions based on decoded features, facilitating accurate alignment without the need for MEMC. Our experimental findings, across various compression configurations (AI, LD and RA) and frame types, prove that I$^2$VC outperforms the state-of-the-art perceptual learned codecs. Impressively, it exhibits a 58.4% enhancement in perceptual reconstruction performance when benchmarked against the H.266/VVC standard (VTM). Official implementation can be found at https://github.com/GYukai/I2VC.
6/4/2024