Enhancing Brazilian Sign Language Recognition through Skeleton Image Representation
2404.19148
0
0
Abstract
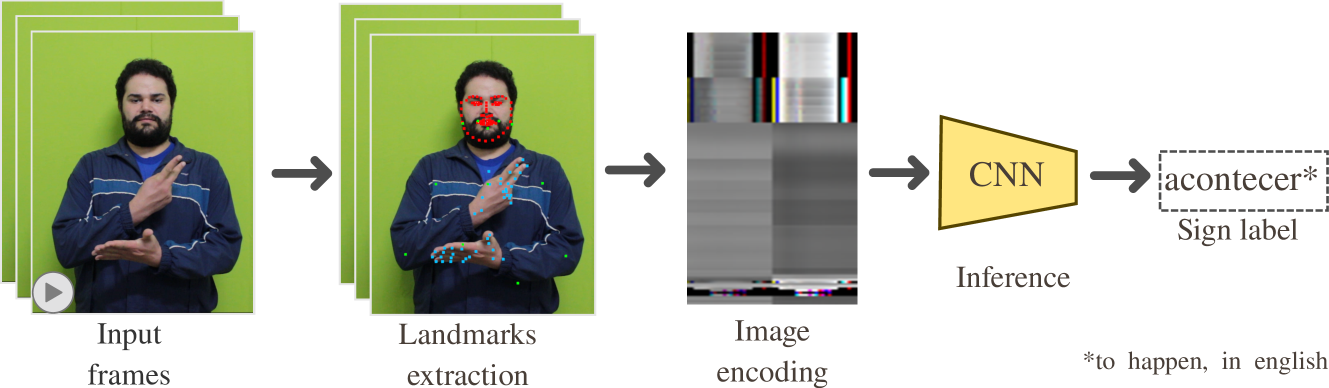
Effective communication is paramount for the inclusion of deaf individuals in society. However, persistent communication barriers due to limited Sign Language (SL) knowledge hinder their full participation. In this context, Sign Language Recognition (SLR) systems have been developed to improve communication between signing and non-signing individuals. In particular, there is the problem of recognizing isolated signs (Isolated Sign Language Recognition, ISLR) of great relevance in the development of vision-based SL search engines, learning tools, and translation systems. This work proposes an ISLR approach where body, hands, and facial landmarks are extracted throughout time and encoded as 2-D images. These images are processed by a convolutional neural network, which maps the visual-temporal information into a sign label. Experimental results demonstrate that our method surpassed the state-of-the-art in terms of performance metrics on two widely recognized datasets in Brazilian Sign Language (LIBRAS), the primary focus of this study. In addition to being more accurate, our method is more time-efficient and easier to train due to its reliance on a simpler network architecture and solely RGB data as input.
Create account to get full access
Enhancing Brazilian Sign Language Recognition through Skeleton Image Representation
Overview
- The paper focuses on improving recognition of Brazilian Sign Language (Libras) by using a novel technique called Isolated Sign Language Recognition (ISLR) that represents sign language gestures as skeleton images.
- The ISLR method captures the spatial-temporal dynamics of sign language by extracting the skeletal pose of the signer's body and hands, and then encoding this information into a 2D image representation.
- This allows the use of powerful image classification models to recognize the sign language gestures.
Plain English Explanation
The researchers developed a new way to recognize Brazilian Sign Language (Libras) gestures by representing them as 2D skeleton images. Rather than just looking at the raw video of the sign language, their method extracts the poses and movements of the signer's body and hands over time and encodes this information into an image format.
This allows them to use advanced image classification models, which are very good at recognizing patterns, to identify the different Libras signs. The key idea is that the spatial and temporal dynamics of the sign language gestures are captured in this 2D skeleton image representation, making it easier for the computer to understand and classify the signs accurately.
The benefit of this approach is that it can potentially achieve better recognition performance compared to previous sign language recognition methods, while also being more efficient and scalable. By converting the video data into a standardized image format, the researchers can leverage powerful computer vision techniques that have been optimized for image recognition tasks.
Technical Explanation
The paper introduces the Isolated Sign Language Recognition (ISLR) method, which represents sign language gestures as 2D skeleton images. The ISLR approach consists of the following key steps:
-
Pose Estimation: The researchers use a pre-trained human pose estimation model to extract the 2D skeletal joints of the signer's body and hands from the input video frames.
-
Spatial-Temporal Encoding: The 2D skeletal joint coordinates are then encoded into a fixed-size 2D image representation, preserving both the spatial configuration of the joints as well as their temporal evolution over the duration of the sign.
-
Classification: The resulting skeleton images are fed into a deep convolutional neural network (CNN) model, which is trained to recognize the different Libras sign classes.
The paper evaluates the ISLR method on two Libras datasets, comparing its performance to several baseline sign language recognition approaches. The results demonstrate that the ISLR method achieves state-of-the-art accuracy in recognizing isolated Libras signs, outperforming prior techniques that relied on raw video or hand-crafted features.
The authors attribute the success of ISLR to its ability to effectively capture the spatial-temporal dynamics of sign language gestures in a compact 2D image format, which can be efficiently processed by powerful CNN models trained for image recognition tasks.
Critical Analysis
The paper provides a compelling approach for enhancing sign language recognition by leveraging recent advancements in computer vision and deep learning. The key strength of the ISLR method is its ability to transform the complex spatio-temporal data of sign language gestures into a standardized 2D image representation, which enables the use of highly optimized image classification models.
However, the paper does not address some potential limitations and areas for further research. For example, the ISLR method is evaluated on isolated sign recognition, whereas real-world sign language communication often involves continuous, connected signing. Extending the approach to handle continuous signing would be an important next step.
Additionally, the paper does not discuss the robustness of the ISLR method to variations in signer appearance, lighting conditions, camera angles, and other real-world factors that can affect sign language recognition performance. Evaluating the method's ability to generalize to diverse signing environments would be a valuable area of investigation.
Furthermore, the paper does not provide a detailed analysis of the computational efficiency and resource requirements of the ISLR method, which would be important considerations for deploying the system in practical applications, such as sign language interpretation or assistive technologies.
Overall, the paper presents a promising direction for advancing sign language recognition, but further research is needed to address the limitations and fully realize the potential of the ISLR approach.
Conclusion
The paper introduces a novel Isolated Sign Language Recognition (ISLR) method that represents sign language gestures as 2D skeleton images, enabling the use of powerful deep learning-based image classification techniques for sign recognition. The ISLR approach effectively captures the spatial-temporal dynamics of sign language and outperforms previous methods on Libras datasets.
While the paper demonstrates the effectiveness of the ISLR method for isolated sign recognition, further research is needed to address the limitations of the approach, such as extending it to continuous signing, improving robustness to real-world variations, and optimizing computational efficiency. Nonetheless, the ISLR technique represents an important step forward in enhancing the recognition of sign languages, which has the potential to improve accessibility and communication for the deaf and hard-of-hearing community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
StepNet: Spatial-temporal Part-aware Network for Isolated Sign Language Recognition
Xiaolong Shen, Zhedong Zheng, Yi Yang
0
0
The goal of sign language recognition (SLR) is to help those who are hard of hearing or deaf overcome the communication barrier. Most existing approaches can be typically divided into two lines, i.e., Skeleton-based and RGB-based methods, but both the two lines of methods have their limitations. Skeleton-based methods do not consider facial expressions, while RGB-based approaches usually ignore the fine-grained hand structure. To overcome both limitations, we propose a new framework called Spatial-temporal Part-aware network~(StepNet), based on RGB parts. As its name suggests, it is made up of two modules: Part-level Spatial Modeling and Part-level Temporal Modeling. Part-level Spatial Modeling, in particular, automatically captures the appearance-based properties, such as hands and faces, in the feature space without the use of any keypoint-level annotations. On the other hand, Part-level Temporal Modeling implicitly mines the long-short term context to capture the relevant attributes over time. Extensive experiments demonstrate that our StepNet, thanks to spatial-temporal modules, achieves competitive Top-1 Per-instance accuracy on three commonly-used SLR benchmarks, i.e., 56.89% on WLASL, 77.2% on NMFs-CSL, and 77.1% on BOBSL. Additionally, the proposed method is compatible with the optical flow input and can produce superior performance if fused. For those who are hard of hearing, we hope that our work can act as a preliminary step.
4/9/2024

PenSLR: Persian end-to-end Sign Language Recognition Using Ensembling
Amirparsa Salmankhah, Amirreza Rajabi, Negin Kheirmand, Ali Fadaeimanesh, Amirreza Tarabkhah, Amirreza Kazemzadeh, Hamed Farbeh
0
0
Sign Language Recognition (SLR) is a fast-growing field that aims to fill the communication gaps between the hearing-impaired and people without hearing loss. Existing solutions for Persian Sign Language (PSL) are limited to word-level interpretations, underscoring the need for more advanced and comprehensive solutions. Moreover, previous work on other languages mainly focuses on manipulating the neural network architectures or hardware configurations instead of benefiting from the aggregated results of multiple models. In this paper, we introduce PenSLR, a glove-based sign language system consisting of an Inertial Measurement Unit (IMU) and five flexible sensors powered by a deep learning framework capable of predicting variable-length sequences. We achieve this in an end-to-end manner by leveraging the Connectionist Temporal Classification (CTC) loss function, eliminating the need for segmentation of input signals. To further enhance its capabilities, we propose a novel ensembling technique by leveraging a multiple sequence alignment algorithm known as Star Alignment. Furthermore, we introduce a new PSL dataset, including 16 PSL signs with more than 3000 time-series samples in total. We utilize this dataset to evaluate the performance of our system based on four word-level and sentence-level metrics. Our evaluations show that PenSLR achieves a remarkable word accuracy of 94.58% and 96.70% in subject-independent and subject-dependent setups, respectively. These achievements are attributable to our ensembling algorithm, which not only boosts the word-level performance by 0.51% and 1.32% in the respective scenarios but also yields significant enhancements of 1.46% and 4.00%, respectively, in sentence-level accuracy.
6/26/2024
Transfer Learning for Cross-dataset Isolated Sign Language Recognition in Under-Resourced Datasets
Ahmet Alp Kindiroglu, Ozgur Kara, Ogulcan Ozdemir, Lale Akarun
0
0
Sign language recognition (SLR) has recently achieved a breakthrough in performance thanks to deep neural networks trained on large annotated sign datasets. Of the many different sign languages, these annotated datasets are only available for a select few. Since acquiring gloss-level labels on sign language videos is difficult, learning by transferring knowledge from existing annotated sources is useful for recognition in under-resourced sign languages. This study provides a publicly available cross-dataset transfer learning benchmark from two existing public Turkish SLR datasets. We use a temporal graph convolution-based sign language recognition approach to evaluate five supervised transfer learning approaches and experiment with closed-set and partial-set cross-dataset transfer learning. Experiments demonstrate that improvement over finetuning based transfer learning is possible with specialized supervised transfer learning methods.
4/16/2024

A Comparative Study of Continuous Sign Language Recognition Techniques
Sarah Alyami, Hamzah Luqman
0
0
Continuous Sign Language Recognition (CSLR) focuses on the interpretation of a sequence of sign language gestures performed continually without pauses. In this study, we conduct an empirical evaluation of recent deep learning CSLR techniques and assess their performance across various datasets and sign languages. The models selected for analysis implement a range of approaches for extracting meaningful features and employ distinct training strategies. To determine their efficacy in modeling different sign languages, these models were evaluated using multiple datasets, specifically RWTH-PHOENIX-Weather-2014, ArabSign, and GrSL, each representing a unique sign language. The performance of the models was further tested with unseen signers and sentences. The conducted experiments establish new benchmarks on the selected datasets and provide valuable insights into the robustness and generalization of the evaluated techniques under challenging scenarios.
6/19/2024