Enhancing EEG-to-Text Decoding through Transferable Representations from Pre-trained Contrastive EEG-Text Masked Autoencoder
2402.17433
0
0
🖼️
Abstract
Reconstructing natural language from non-invasive electroencephalography (EEG) holds great promise as a language decoding technology for brain-computer interfaces (BCIs). However, EEG-based language decoding is still in its nascent stages, facing several technical issues such as: 1) Absence of a hybrid strategy that can effectively integrate cross-modality (between EEG and text) self-learning with intra-modality self-reconstruction of EEG features or textual sequences; 2) Under-utilization of large language models (LLMs) to enhance EEG-based language decoding. To address above issues, we propose the Contrastive EEG-Text Masked Autoencoder (CET-MAE), a novel model that orchestrates compound self-supervised learning across and within EEG and text through a dedicated multi-stream encoder. Furthermore, we develop a framework called E2T-PTR (EEG-to-Text decoding using Pretrained Transferable Representations), which leverages pre-trained modules alongside the EEG stream from CET-MAE and further enables an LLM (specifically BART) to decode text from EEG sequences. Comprehensive experiments conducted on the popular text-evoked EEG database, ZuCo, demonstrate the superiority of E2T-PTR, which outperforms the state-of-the-art in ROUGE-1 F1 and BLEU-4 scores by 8.34% and 32.21%, respectively. These results indicate significant advancements in the field and underscores the proposed framework's potential to enable more powerful and widespread BCI applications.
Create account to get full access
Overview
- This paper presents research on using machine learning models to decode brain signals recorded via electroencephalography (EEG) and generate natural language text.
- The researchers explore different techniques for aligning EEG data with text, including multi-alignment decoding (MAD) and open-vocabulary decoding (EEG2Text).
- The paper also provides a review of recent advancements in the field of EEG-to-text decoding, discussing the progress made and the challenges that remain (Unveiling Thoughts).
Plain English Explanation
The human brain generates electrical signals that can be measured using a device called an electroencephalogram (EEG). Researchers are exploring ways to use machine learning to decode these EEG signals and translate them into text that can be understood by humans. This could have important applications, such as helping people with speech or motor impairments communicate more easily.
The key idea is to find ways to align the EEG data with corresponding text, so the model can learn to generate text that matches the brain signals. The paper discusses two specific approaches for doing this: multi-alignment decoding (MAD) and open-vocabulary decoding (EEG2Text). These methods aim to make the translation process more accurate and flexible.
The paper also provides an overview of the recent progress made in this field, highlighting the successes as well as the ongoing challenges. For example, the models are getting better at decoding EEG signals, but there is still room for improvement in terms of the fluency and coherence of the generated text.
Technical Explanation
The paper explores two main approaches for aligning EEG data with corresponding text:
-
Multi-Alignment Decoding (MAD): This method aims to jointly align the EEG data with multiple relevant text sources, such as transcripts, image captions, or other modalities. By leveraging this additional contextual information, the model can learn more robust associations between the brain signals and the language.
-
Open-Vocabulary Decoding (EEG2Text): Traditional EEG-to-text models have been limited to predicting a fixed set of words. EEG2Text instead uses a large language model with an open vocabulary, allowing the model to generate more diverse and natural-sounding text.
The paper also reviews the broader progress made in the field of EEG-to-text decoding, discussing the improvements in model architectures, training techniques, and dataset sizes. It highlights the increasing use of large transformer-based models, which have shown superior performance compared to earlier approaches (Are EEG-to-Text Models Working).
Critical Analysis
The paper acknowledges several limitations and areas for further research:
- The models still struggle to generate highly fluent and coherent text, with some incoherence and grammatical errors.
- The performance of the models is heavily dependent on the quality and size of the training data, which can be challenging to collect for EEG-based tasks.
- There are ethical concerns around the potential misuse of this technology, such as privacy violations or the creation of misleading synthetic text.
Additionally, the paper does not address the computational complexity and resource requirements of the proposed approaches, which could be a practical concern for real-world deployment.
Conclusion
This research represents an important step forward in the field of EEG-to-text decoding, demonstrating the potential of using machine learning to translate brain signals into natural language. The proposed techniques, such as multi-alignment decoding and open-vocabulary generation, show promising results and could lead to new applications for assistive technology and brain-computer interfaces.
However, there are still significant challenges to overcome, including improving the fluency and coherence of the generated text, addressing ethical concerns, and making the models more efficient and accessible. Continued research and collaboration between neuroscientists, machine learning experts, and ethicists will be crucial for realizing the full potential of this technology while mitigating its risks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
EEG2TEXT: Open Vocabulary EEG-to-Text Decoding with EEG Pre-Training and Multi-View Transformer
Hanwen Liu, Daniel Hajialigol, Benny Antony, Aiguo Han, Xuan Wang
0
0
Deciphering the intricacies of the human brain has captivated curiosity for centuries. Recent strides in Brain-Computer Interface (BCI) technology, particularly using motor imagery, have restored motor functions such as reaching, grasping, and walking in paralyzed individuals. However, unraveling natural language from brain signals remains a formidable challenge. Electroencephalography (EEG) is a non-invasive technique used to record electrical activity in the brain by placing electrodes on the scalp. Previous studies of EEG-to-text decoding have achieved high accuracy on small closed vocabularies, but still fall short of high accuracy when dealing with large open vocabularies. We propose a novel method, EEG2TEXT, to improve the accuracy of open vocabulary EEG-to-text decoding. Specifically, EEG2TEXT leverages EEG pre-training to enhance the learning of semantics from EEG signals and proposes a multi-view transformer to model the EEG signal processing by different spatial regions of the brain. Experiments show that EEG2TEXT has superior performance, outperforming the state-of-the-art baseline methods by a large margin of up to 5% in absolute BLEU and ROUGE scores. EEG2TEXT shows great potential for a high-performance open-vocabulary brain-to-text system to facilitate communication.
5/6/2024
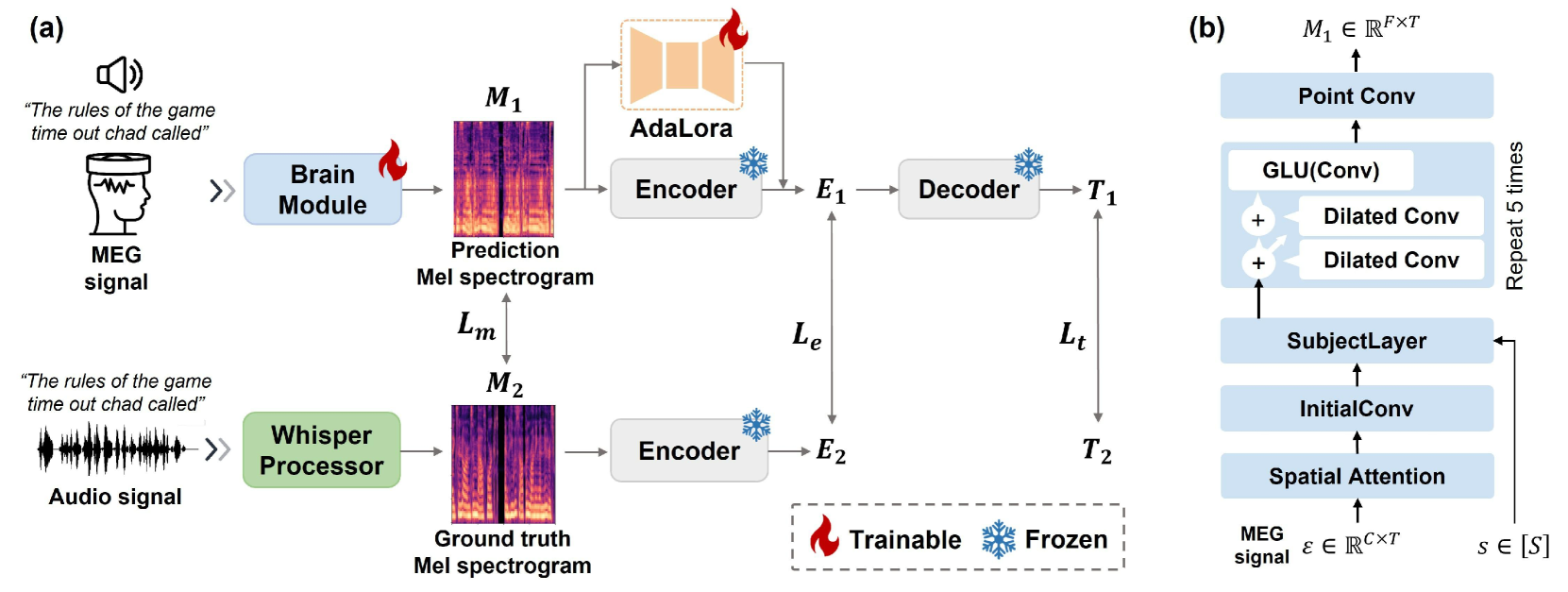
MAD: Multi-Alignment MEG-to-Text Decoding
Yiqian Yang, Hyejeong Jo, Yiqun Duan, Qiang Zhang, Jinni Zhou, Won Hee Lee, Renjing Xu, Hui Xiong
0
0
Deciphering language from brain activity is a crucial task in brain-computer interface (BCI) research. Non-invasive cerebral signaling techniques including electroencephalography (EEG) and magnetoencephalography (MEG) are becoming increasingly popular due to their safety and practicality, avoiding invasive electrode implantation. However, current works under-investigated three points: 1) a predominant focus on EEG with limited exploration of MEG, which provides superior signal quality; 2) poor performance on unseen text, indicating the need for models that can better generalize to diverse linguistic contexts; 3) insufficient integration of information from other modalities, which could potentially constrain our capacity to comprehensively understand the intricate dynamics of brain activity. This study presents a novel approach for translating MEG signals into text using a speech-decoding framework with multiple alignments. Our method is the first to introduce an end-to-end multi-alignment framework for totally unseen text generation directly from MEG signals. We achieve an impressive BLEU-1 score on the $textit{GWilliams}$ dataset, significantly outperforming the baseline from 5.49 to 10.44 on the BLEU-1 metric. This improvement demonstrates the advancement of our model towards real-world applications and underscores its potential in advancing BCI research. Code is available at $href{https://github.com/NeuSpeech/MAD-MEG2text}{https://github.com/NeuSpeech/MAD-MEG2text}$.
6/4/2024
👀
Unveiling Thoughts: A Review of Advancements in EEG Brain Signal Decoding into Text
Saydul Akbar Murad, Nick Rahimi
0
0
The conversion of brain activity into text using electroencephalography (EEG) has gained significant traction in recent years. Many researchers are working to develop new models to decode EEG signals into text form. Although this area has shown promising developments, it still faces numerous challenges that necessitate further improvement. It's important to outline this area's recent developments and future research directions. In this review article, we thoroughly summarize the progress in EEG-to-text conversion. Firstly, we talk about how EEG-to-text technology has grown and what problems we still face. Secondly, we discuss existing techniques used in this field. This includes methods for collecting EEG data, the steps to process these signals, and the development of systems capable of translating these signals into coherent text. We conclude with potential future research directions, emphasizing the need for enhanced accuracy, reduced system constraints, and the exploration of novel applications across varied sectors. By addressing these aspects, this review aims to contribute to developing more accessible and effective Brain-Computer Interface (BCI) technology for a broader user base.
5/3/2024
🤿
Are EEG-to-Text Models Working?
Hyejeong Jo, Yiqian Yang, Juhyeok Han, Yiqun Duan, Hui Xiong, Won Hee Lee
0
0
This work critically analyzes existing models for open-vocabulary EEG-to-Text translation. We identify a crucial limitation: previous studies often employed implicit teacher-forcing during evaluation, artificially inflating performance metrics. Additionally, they lacked a critical benchmark - comparing model performance on pure noise inputs. We propose a methodology to differentiate between models that truly learn from EEG signals and those that simply memorize training data. Our analysis reveals that model performance on noise data can be comparable to that on EEG data. These findings highlight the need for stricter evaluation practices in EEG-to-Text research, emphasizing transparent reporting and rigorous benchmarking with noise inputs. This approach will lead to more reliable assessments of model capabilities and pave the way for robust EEG-to-Text communication systems.
6/17/2024