Enhancing Emotion Recognition in Conversation through Emotional Cross-Modal Fusion and Inter-class Contrastive Learning
2405.17900
0
0
Abstract
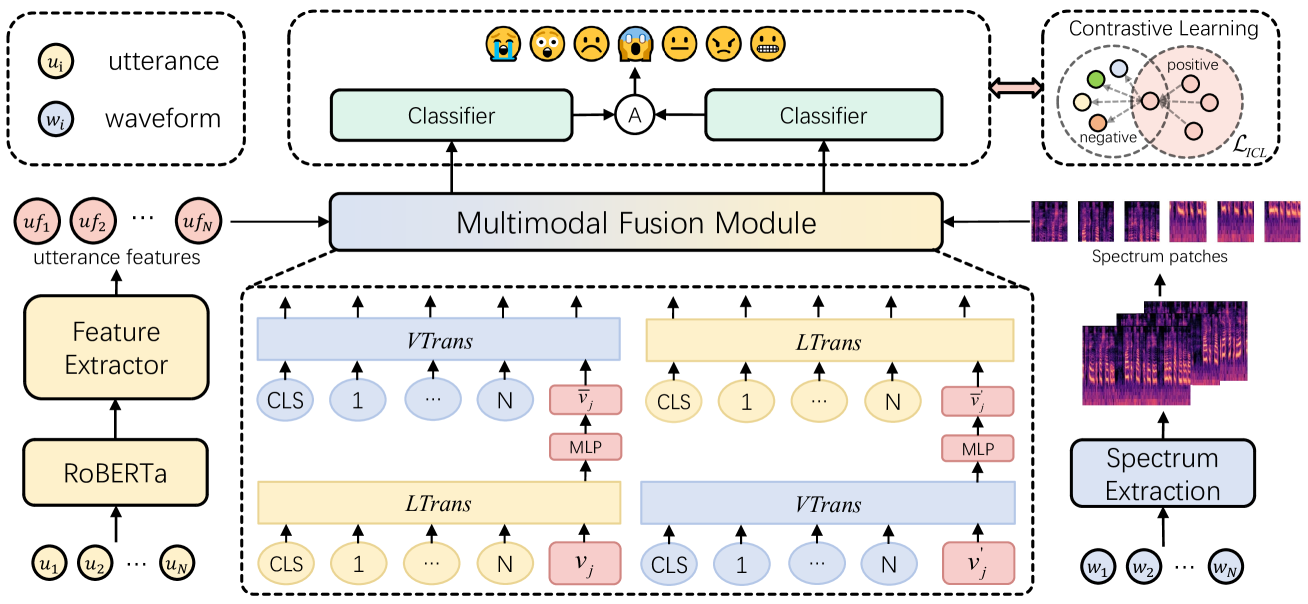
The purpose of emotion recognition in conversation (ERC) is to identify the emotion category of an utterance based on contextual information. Previous ERC methods relied on simple connections for cross-modal fusion and ignored the information differences between modalities, resulting in the model being unable to focus on modality-specific emotional information. At the same time, the shared information between modalities was not processed to generate emotions. Information redundancy problem. To overcome these limitations, we propose a cross-modal fusion emotion prediction network based on vector connections. The network mainly includes two stages: the multi-modal feature fusion stage based on connection vectors and the emotion classification stage based on fused features. Furthermore, we design a supervised inter-class contrastive learning module based on emotion labels. Experimental results confirm the effectiveness of the proposed method, demonstrating excellent performance on the IEMOCAP and MELD datasets.
Create account to get full access
Overview
- The paper explores an approach called "Emotional Cross-Modal Fusion and Inter-class Contrastive Learning" to enhance emotion recognition in conversational settings.
- The method fuses information from multiple modalities (e.g., text, audio, video) to better capture emotional cues and employs contrastive learning to improve the model's ability to distinguish between different emotion classes.
- The proposed framework aims to address challenges in emotion recognition, such as handling complex and ambiguous emotional expressions in conversations.
Plain English Explanation
Recognizing emotions during conversations is an important task with applications in areas like customer service, mental health support, and social robotics. However, it can be challenging because people often express emotions in subtle and nuanced ways that can be difficult for computers to detect.
The researchers in this study developed a new approach that combines information from different sources, like the words people say, the tone of their voice, and their facial expressions. By fusing these "modalities" together, the model can get a more complete picture of the emotional state of the person speaking.
Additionally, the researchers used a technique called "contrastive learning" to help the model learn to better distinguish between different emotion categories, like happiness, anger, and sadness. This involves training the model to recognize the differences between emotions, rather than just memorizing examples of each one.
The goal of this approach is to create an emotion recognition system that is more accurate and robust, able to handle the complexities of real-world conversations. By leveraging multiple modalities and employing advanced machine learning techniques, the researchers aim to advance the state-of-the-art in this important area of artificial intelligence research.
Technical Explanation
The paper proposes an "Emotional Cross-Modal Fusion and Inter-class Contrastive Learning" framework to enhance emotion recognition in conversations. The key components of the approach are:
-
Cross-Modal Fusion: The model takes input from multiple modalities, such as text, audio, and video, and uses specialized fusion modules to combine the information from these sources. This allows the model to leverage complementary emotional cues across different communication channels.
-
Inter-class Contrastive Learning: In addition to the typical classification loss, the model is trained using a contrastive loss that encourages it to learn representations that better distinguish between different emotion categories. This contrastive learning approach helps the model develop a more nuanced understanding of emotional expressions.
-
Emotional Representation Learning: The fusion and contrastive learning components work together to learn rich, discriminative emotional representations that capture the complexity of human emotions in conversational settings. This is achieved through cross-modal fusion networks and revisiting multi-modal emotion learning.
The researchers evaluate their approach on several benchmark datasets for emotion recognition in conversations, demonstrating improved performance compared to previous state-of-the-art methods. The findings suggest that the proposed framework can effectively leverage multimodal information and contrastive learning to enhance the recognition of emotions in complex, real-world conversational scenarios.
Critical Analysis
The paper presents a well-designed and comprehensive approach to improving emotion recognition in conversations. The authors have thoughtfully addressed key challenges in this domain, such as handling ambiguous emotional expressions and exploiting complementary information from multiple modalities.
One potential limitation of the study is the reliance on pre-defined emotion categories, which may not fully capture the nuances and complexities of human emotional experiences. Additionally, the performance of the model may be influenced by the quality and diversity of the training data, which can be affected by factors like cultural biases or limited representativeness.
Furthermore, the paper does not provide a detailed analysis of the model's interpretability or explainability. Understanding how the model makes its decisions and which features it relies on could be valuable for gaining insights into the underlying mechanisms of emotion recognition and potentially improving the model's performance or addressing any biases.
Despite these considerations, the proposed framework represents a significant advancement in the field of emotion recognition in conversations. The authors' innovative use of cross-modal fusion and contrastive learning demonstrates the potential of these techniques to enhance the performance and robustness of emotion recognition systems in real-world applications.
Conclusion
The paper introduces an "Emotional Cross-Modal Fusion and Inter-class Contrastive Learning" framework that aims to improve emotion recognition in conversational settings. By fusing information from multiple modalities and employing contrastive learning techniques, the proposed approach effectively captures the complexity of human emotional expressions and outperforms previous state-of-the-art methods.
The findings of this research have important implications for a wide range of applications, including customer service, mental health support, and social robotics, where accurate emotion recognition is crucial for effective communication and interaction. The authors' contributions represent a significant step forward in the field of affective computing and lay the groundwork for further advancements in this rapidly evolving area of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Emotion-Anchored Contrastive Learning Framework for Emotion Recognition in Conversation
Fangxu Yu, Junjie Guo, Zhen Wu, Xinyu Dai
0
0
Emotion Recognition in Conversation (ERC) involves detecting the underlying emotion behind each utterance within a conversation. Effectively generating representations for utterances remains a significant challenge in this task. Recent works propose various models to address this issue, but they still struggle with differentiating similar emotions such as excitement and happiness. To alleviate this problem, We propose an Emotion-Anchored Contrastive Learning (EACL) framework that can generate more distinguishable utterance representations for similar emotions. To achieve this, we utilize label encodings as anchors to guide the learning of utterance representations and design an auxiliary loss to ensure the effective separation of anchors for similar emotions. Moreover, an additional adaptation process is proposed to adapt anchors to serve as effective classifiers to improve classification performance. Across extensive experiments, our proposed EACL achieves state-of-the-art emotion recognition performance and exhibits superior performance on similar emotions. Our code is available at https://github.com/Yu-Fangxu/EACL.
4/1/2024
🤿
Deep Emotion Recognition in Textual Conversations: A Survey
Patr'icia Pereira, Helena Moniz, Joao Paulo Carvalho
0
0
While Emotion Recognition in Conversations (ERC) has seen a tremendous advancement in the last few years, new applications and implementation scenarios present novel challenges and opportunities. These range from leveraging the conversational context, speaker and emotion dynamics modelling, to interpreting common sense expressions, informal language and sarcasm, addressing challenges of real time ERC, recognizing emotion causes, different taxonomies across datasets, multilingual ERC to interpretability. This survey starts by introducing ERC, elaborating on the challenges and opportunities pertaining to this task. It proceeds with a description of the emotion taxonomies and a variety of ERC benchmark datasets employing such taxonomies. This is followed by descriptions of the most prominent works in ERC with explanations of the Deep Learning architectures employed. Then, it provides advisable ERC practices towards better frameworks, elaborating on methods to deal with subjectivity in annotations and modelling and methods to deal with the typically unbalanced ERC datasets. Finally, it presents systematic review tables comparing several works regarding the methods used and their performance. The survey highlights the advantage of leveraging techniques to address unbalanced data, the exploration of mixed emotions and the benefits of incorporating annotation subjectivity in the learning phase.
5/24/2024
🌐
CFN-ESA: A Cross-Modal Fusion Network with Emotion-Shift Awareness for Dialogue Emotion Recognition
Jiang Li, Xiaoping Wang, Yingjian Liu, Zhigang Zeng
0
0
Multimodal emotion recognition in conversation (ERC) has garnered growing attention from research communities in various fields. In this paper, we propose a Cross-modal Fusion Network with Emotion-Shift Awareness (CFN-ESA) for ERC. Extant approaches employ each modality equally without distinguishing the amount of emotional information in these modalities, rendering it hard to adequately extract complementary information from multimodal data. To cope with this problem, in CFN-ESA, we treat textual modality as the primary source of emotional information, while visual and acoustic modalities are taken as the secondary sources. Besides, most multimodal ERC models ignore emotion-shift information and overfocus on contextual information, leading to the failure of emotion recognition under emotion-shift scenario. We elaborate an emotion-shift module to address this challenge. CFN-ESA mainly consists of unimodal encoder (RUME), cross-modal encoder (ACME), and emotion-shift module (LESM). RUME is applied to extract conversation-level contextual emotional cues while pulling together data distributions between modalities; ACME is utilized to perform multimodal interaction centered on textual modality; LESM is used to model emotion shift and capture emotion-shift information, thereby guiding the learning of the main task. Experimental results demonstrate that CFN-ESA can effectively promote performance for ERC and remarkably outperform state-of-the-art models.
4/16/2024

Revisiting Multimodal Emotion Recognition in Conversation from the Perspective of Graph Spectrum
Tao Meng, Fuchen Zhang, Yuntao Shou, Wei Ai, Nan Yin, Keqin Li
0
0
Efficiently capturing consistent and complementary semantic features in a multimodal conversation context is crucial for Multimodal Emotion Recognition in Conversation (MERC). Existing methods mainly use graph structures to model dialogue context semantic dependencies and employ Graph Neural Networks (GNN) to capture multimodal semantic features for emotion recognition. However, these methods are limited by some inherent characteristics of GNN, such as over-smoothing and low-pass filtering, resulting in the inability to learn long-distance consistency information and complementary information efficiently. Since consistency and complementarity information correspond to low-frequency and high-frequency information, respectively, this paper revisits the problem of multimodal emotion recognition in conversation from the perspective of the graph spectrum. Specifically, we propose a Graph-Spectrum-based Multimodal Consistency and Complementary collaborative learning framework GS-MCC. First, GS-MCC uses a sliding window to construct a multimodal interaction graph to model conversational relationships and uses efficient Fourier graph operators to extract long-distance high-frequency and low-frequency information, respectively. Then, GS-MCC uses contrastive learning to construct self-supervised signals that reflect complementarity and consistent semantic collaboration with high and low-frequency signals, thereby improving the ability of high and low-frequency information to reflect real emotions. Finally, GS-MCC inputs the collaborative high and low-frequency information into the MLP network and softmax function for emotion prediction. Extensive experiments have proven the superiority of the GS-MCC architecture proposed in this paper on two benchmark data sets.
5/6/2024