Enhancing Suicide Risk Detection on Social Media through Semi-Supervised Deep Label Smoothing
2405.05795
0
0

Abstract
Suicide is a prominent issue in society. Unfortunately, many people at risk for suicide do not receive the support required. Barriers to people receiving support include social stigma and lack of access to mental health care. With the popularity of social media, people have turned to online forums, such as Reddit to express their feelings and seek support. This provides the opportunity to support people with the aid of artificial intelligence. Social media posts can be classified, using text classification, to help connect people with professional help. However, these systems fail to account for the inherent uncertainty in classifying mental health conditions. Unlike other areas of healthcare, mental health conditions have no objective measurements of disease often relying on expert opinion. Thus when formulating deep learning problems involving mental health, using hard, binary labels does not accurately represent the true nature of the data. In these settings, where human experts may disagree, fuzzy or soft labels may be more appropriate. The current work introduces a novel label smoothing method which we use to capture any uncertainty within the data. We test our approach on a five-label multi-class classification problem. We show, our semi-supervised deep label smoothing method improves classification accuracy above the existing state of the art. Where existing research reports an accuracy of 43% on the Reddit C-SSRS dataset, using empirical experiments to evaluate our novel label smoothing method, we improve upon this existing benchmark to 52%. These improvements in model performance have the potential to better support those experiencing mental distress. Future work should explore the use of probabilistic methods in both natural language processing and quantifying contributions of both epistemic and aleatoric uncertainty in noisy datasets.
Create account to get full access
Overview
- This paper presents a semi-supervised deep learning approach to enhance the detection of suicide risk on social media.
- The method uses a novel "label smoothing" technique to improve the model's performance on identifying users at risk of suicide.
- The research aims to develop more accurate and reliable tools for identifying and supporting individuals who may be struggling with suicidal thoughts on social media platforms.
Plain English Explanation
The researchers in this paper tackle the important problem of detecting suicide risk on social media. They recognize that many people struggling with suicidal thoughts may express their feelings online, and that early intervention could save lives. However, automatically identifying these individuals is challenging, as their posts may not explicitly mention suicide.
To address this, the researchers developed a new machine learning model that can more accurately detect suicide risk from social media data. The key innovation is a "label smoothing" technique, which helps the model better generalize from the limited labeled data it is trained on. This allows the model to make more nuanced and reliable predictions about who may be at risk of suicide, based on the patterns in their online activity.
By improving the accuracy of suicide risk detection, this research could lead to better tools for mental health professionals and social media platforms to identify and support people in crisis. This work builds on previous efforts in this area, such as the SOS-1K dataset for fine-grained suicide risk classification and the Big Data Analytics System for Predicting Suicidal Ideation.
Technical Explanation
The paper proposes a semi-supervised deep learning approach to enhance suicide risk detection on social media. The key technical innovation is a "semi-supervised deep label smoothing" (SSDLS) method, which helps the model learn more robust and generalizable representations from the limited labeled data available.
Specifically, the SSDLS method involves two main steps:
- Unsupervised feature learning: The model first learns general feature representations from a large corpus of unlabeled social media posts, using self-supervised techniques like masked language modeling.
- Supervised fine-tuning with label smoothing: The pre-trained model is then fine-tuned on the labeled suicide risk dataset, but with a novel "label smoothing" regularization. This encourages the model to make less confident, more nuanced predictions, which can lead to better overall performance.
The researchers evaluate their SSDLS approach on several suicide risk detection benchmarks, including the SOS-1K dataset and others. They demonstrate significant improvements over prior state-of-the-art models, particularly in identifying users at moderate or high risk of suicide.
Critical Analysis
The researchers acknowledge several limitations of their work. First, the labeled suicide risk datasets used are still relatively small, which constrains the model's ability to learn robust representations. Expanding the availability of high-quality annotated data in this domain could further improve performance.
Additionally, the paper does not provide a detailed analysis of the types of social media signals the model uses to make its predictions. Understanding the interpretability and explainability of the model's decision-making process would be valuable for building trust and facilitating real-world deployment.
Finally, while the proposed SSDLS method demonstrates promising results, it is not clear how it would scale to the vast amounts of social media data in production settings. Exploring efficient and distributed implementations of the approach could be an important area for future research.
Overall, this work represents a valuable contribution to the important challenge of suicide risk detection on social media. By introducing novel semi-supervised techniques, the researchers have advanced the state-of-the-art in this domain. However, continued research is needed to address the remaining challenges and develop practical, trustworthy systems that can reliably identify and support individuals at risk of suicide.
Conclusion
This paper presents a novel semi-supervised deep learning approach to enhance suicide risk detection on social media. By incorporating a "label smoothing" technique, the model is able to make more nuanced and reliable predictions about which users may be at risk of suicide based on their online activity.
The researchers demonstrate that their SSDLS method outperforms previous state-of-the-art models on several benchmark datasets, particularly in identifying users at moderate or high risk of suicide. This work builds on and complements other recent efforts in this area, such as the EmoCare system for automatic depression symptom screening and the data-driven semi-supervised approach for disease detection from social media.
Overall, this research represents an important step forward in developing more accurate and effective tools for identifying and supporting individuals at risk of suicide on social media platforms. By continuing to advance the state-of-the-art in this domain, the goal is to save lives and provide timely interventions for those struggling with mental health challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
Supervised Learning and Large Language Model Benchmarks on Mental Health Datasets: Cognitive Distortions and Suicidal Risks in Chinese Social Media
Hongzhi Qi, Qing Zhao, Jianqiang Li, Changwei Song, Wei Zhai, Dan Luo, Shuo Liu, Yi Jing Yu, Fan Wang, Huijing Zou, Bing Xiang Yang, Guanghui Fu
0
0
On social media, users often express their personal feelings, which may exhibit cognitive distortions or even suicidal tendencies on certain specific topics. Early recognition of these signs is critical for effective psychological intervention. In this paper, we introduce two novel datasets from Chinese social media: SOS-HL-1K for suicidal risk classification and SocialCD-3K for cognitive distortions detection. The SOS-HL-1K dataset contained 1,249 posts and SocialCD-3K dataset was a multi-label classification dataset that containing 3,407 posts. We propose a comprehensive evaluation using two supervised learning methods and eight large language models (LLMs) on the proposed datasets. From the prompt engineering perspective, we experimented with two types of prompt strategies, including four zero-shot and five few-shot strategies. We also evaluated the performance of the LLMs after fine-tuning on the proposed tasks. The experimental results show that there is still a huge gap between LLMs relying only on prompt engineering and supervised learning. In the suicide classification task, this gap is 6.95% points in F1-score, while in the cognitive distortion task, the gap is even more pronounced, reaching 31.53% points in F1-score. However, after fine-tuning, this difference is significantly reduced. In the suicide and cognitive distortion classification tasks, the gap decreases to 4.31% and 3.14%, respectively. This research highlights the potential of LLMs in psychological contexts, but supervised learning remains necessary for more challenging tasks. All datasets and code are made available.
6/11/2024
🏷️
SOS-1K: A Fine-grained Suicide Risk Classification Dataset for Chinese Social Media Analysis
Hongzhi Qi, Hanfei Liu, Jianqiang Li, Qing Zhao, Wei Zhai, Dan Luo, Tian Yu He, Shuo Liu, Bing Xiang Yang, Guanghui Fu
0
0
In the social media, users frequently express personal emotions, a subset of which may indicate potential suicidal tendencies. The implicit and varied forms of expression in internet language complicate accurate and rapid identification of suicidal intent on social media, thus creating challenges for timely intervention efforts. The development of deep learning models for suicide risk detection is a promising solution, but there is a notable lack of relevant datasets, especially in the Chinese context. To address this gap, this study presents a Chinese social media dataset designed for fine-grained suicide risk classification, focusing on indicators such as expressions of suicide intent, methods of suicide, and urgency of timing. Seven pre-trained models were evaluated in two tasks: high and low suicide risk, and fine-grained suicide risk classification on a level of 0 to 10. In our experiments, deep learning models show good performance in distinguishing between high and low suicide risk, with the best model achieving an F1 score of 88.39%. However, the results for fine-grained suicide risk classification were still unsatisfactory, with an weighted F1 score of 50.89%. To address the issues of data imbalance and limited dataset size, we investigated both traditional and advanced, large language model based data augmentation techniques, demonstrating that data augmentation can enhance model performance by up to 4.65% points in F1-score. Notably, the Chinese MentalBERT model, which was pre-trained on psychological domain data, shows superior performance in both tasks. This study provides valuable insights for automatic identification of suicidal individuals, facilitating timely psychological intervention on social media platforms. The source code and data are publicly available.
4/22/2024
🗣️
Exploring Social Media Posts for Depression Identification: A Study on Reddit Dataset
Nandigramam Sai Harshit, Nilesh Kumar Sahu, Haroon R. Lone
0
0
Depression is one of the most common mental disorders affecting an individual's personal and professional life. In this work, we investigated the possibility of utilizing social media posts to identify depression in individuals. To achieve this goal, we conducted a preliminary study where we extracted and analyzed the top Reddit posts made in 2022 from depression-related forums. The collected data were labeled as depressive and non-depressive using UMLS Metathesaurus. Further, the pre-processed data were fed to classical machine learning models, where we achieved an accuracy of 92.28% in predicting the depressive and non-depressive posts.
5/14/2024
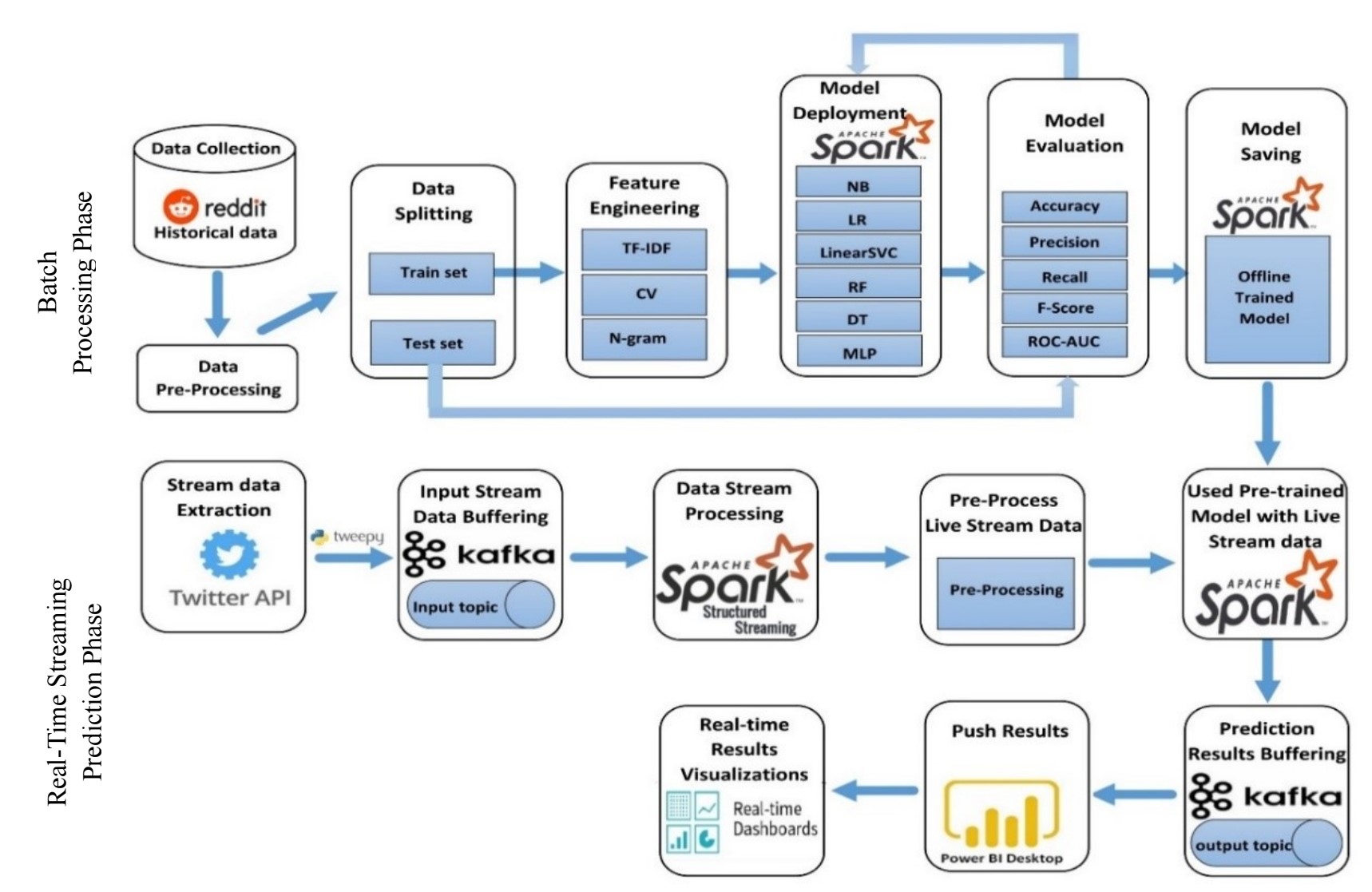
A Big Data Analytics System for Predicting Suicidal Ideation in Real-Time Based on Social Media Streaming Data
Mohamed A. Allayla, Serkan Ayvaz
0
0
Online social media platforms have recently become integral to our society and daily routines. Every day, users worldwide spend a couple of hours on such platforms, expressing their sentiments and emotional state and contacting each other. Analyzing such huge amounts of data from these platforms can provide a clear insight into public sentiments and help detect their mental status. The early identification of these health condition risks may assist in preventing or reducing the number of suicide ideation and potentially saving people's lives. The traditional techniques have become ineffective in processing such streams and large-scale datasets. Therefore, the paper proposed a new methodology based on a big data architecture to predict suicidal ideation from social media content. The proposed approach provides a practical analysis of social media data in two phases: batch processing and real-time streaming prediction. The batch dataset was collected from the Reddit forum and used for model building and training, while streaming big data was extracted using Twitter streaming API and used for real-time prediction. After the raw data was preprocessed, the extracted features were fed to multiple Apache Spark ML classifiers: NB, LR, LinearSVC, DT, RF, and MLP. We conducted various experiments using various feature-extraction techniques with different testing scenarios. The experimental results of the batch processing phase showed that the features extracted of (Unigram + Bigram) + CV-IDF with MLP classifier provided high performance for classifying suicidal ideation, with an accuracy of 93.47%, and then applied for real-time streaming prediction phase.
4/22/2024