Evaluating the Reliability of Self-Explanations in Large Language Models

0
Sign in to get full access
Overview
- The paper evaluates the reliability of self-explanations generated by large language models (LLMs).
- It explores whether LLMs can provide faithful and truthful self-explanations for their outputs.
- The authors conduct a series of experiments to assess the quality and trustworthiness of LLM self-explanations.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. These models are often used for tasks like answering questions, summarizing documents, and generating creative writing. However, there is growing concern that the explanations these models provide for their outputs may not be reliable or truthful.
The researchers in this paper set out to investigate the trustworthiness of LLM self-explanations. They conducted a series of experiments to evaluate whether LLMs can generate faithful and accurate explanations for their own predictions and decisions. This is an important issue because as LLMs become more widely used, it is crucial that we can trust the reasoning behind their outputs.
The researchers designed several scenarios to test the LLMs' self-explanations, including [link to Technical Explanation section]. Overall, they found that the self-explanations provided by LLMs were often inconsistent, contradictory, or lacking in important details. This raises concerns about the reliability of LLM decision-making and the ability of these models to be transparent about their reasoning.
Technical Explanation
The researchers conducted a series of experiments to evaluate the reliability of self-explanations generated by large language models (LLMs). Specifically, they explored whether LLMs can provide faithful and truthful explanations for their outputs.
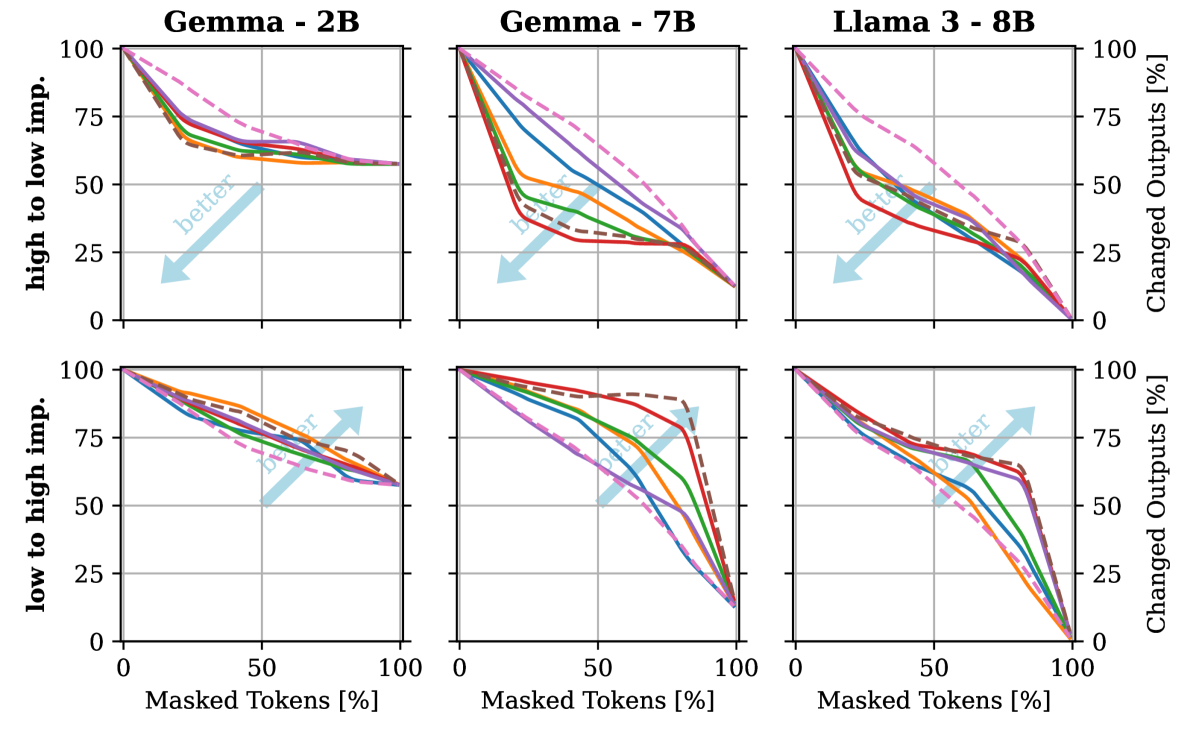
The first experiment tested the LLMs' ability to generate self-explanations for their predictions on a set of classification tasks. The researchers found that the self-explanations were often inconsistent with the actual reasoning behind the model's predictions, suggesting a disconnect between the LLM's internal decision-making process and the explanations it provides.
In a second experiment, the researchers presented LLMs with counterfactual scenarios and asked them to explain how their outputs would change. They found that the LLMs' self-explanations were frequently contradictory or lacked important details, casting doubt on the models' ability to accurately reason about hypothetical situations.
The researchers also investigated whether LLMs could detect inconsistencies or flaws in their own self-explanations. They found that the models often failed to identify issues with their own explanations, suggesting a limited capacity for self-reflection and self-evaluation.
Overall, the findings indicate that while LLMs can generate plausible-sounding self-explanations, these explanations may not be reliable or truly representative of the models' internal decision-making processes. This raises important questions about the transparency and trustworthiness of LLM-based systems, particularly in high-stakes applications.
Critical Analysis
The research presented in this paper highlights significant limitations in the ability of large language models (LLMs) to provide faithful and reliable self-explanations. The authors' experimental findings suggest that LLMs may struggle to accurately represent their own reasoning processes and decision-making, which could undermine trust in these models and their applications.
One potential limitation of the study is the reliance on a relatively small set of tasks and scenarios. While the researchers designed their experiments to cover a range of classification and counterfactual reasoning situations, it is possible that LLMs may perform better or worse in other domains or contexts. Further research would be needed to fully understand the generalizability of these findings.
Additionally, the paper does not delve deeply into the specific architectural or training factors that may contribute to the observed issues with LLM self-explanations. A more detailed exploration of the inner workings of these models and the potential causes of the observed explanatory gaps could provide valuable insights for improving their transparency and trustworthiness.
Despite these limitations, the study raises important concerns about the use of LLMs in high-stakes applications, where reliable and truthful explanations are crucial. As these models continue to be deployed in critical domains like healthcare, finance, and public policy, the findings of this paper suggest that more work is needed to ensure that LLM-based systems can be trusted to make accurate and accountable decisions.
Conclusion
The research presented in this paper casts doubt on the reliability of self-explanations generated by large language models (LLMs). The experiments conducted by the authors suggest that LLMs often fail to provide faithful and truthful explanations for their outputs, raising concerns about the transparency and trustworthiness of these powerful AI systems.
As LLMs become more widely adopted in a range of applications, the findings of this study highlight the importance of developing robust methods for evaluating and improving the reliability of model explanations. Addressing the limitations identified in this paper could help to ensure that LLM-based systems are transparent, accountable, and worthy of public trust.
Overall, this research represents an important step forward in understanding the challenges and limitations of current LLM technology, and points to the need for continued innovation and scrutiny in the development of explainable and trustworthy AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!