ExpertQA: Expert-Curated Questions and Attributed Answers
2309.07852
3
0
👁️
Abstract
As language models are adopted by a more sophisticated and diverse set of users, the importance of guaranteeing that they provide factually correct information supported by verifiable sources is critical across fields of study. This is especially the case for high-stakes fields, such as medicine and law, where the risk of propagating false information is high and can lead to undesirable societal consequences. Previous work studying attribution and factuality has not focused on analyzing these characteristics of language model outputs in domain-specific scenarios. In this work, we conduct human evaluation of responses from a few representative systems along various axes of attribution and factuality, by bringing domain experts in the loop. Specifically, we collect expert-curated questions from 484 participants across 32 fields of study, and then ask the same experts to evaluate generated responses to their own questions. In addition, we ask experts to improve upon responses from language models. The output of our analysis is ExpertQA, a high-quality long-form QA dataset with 2177 questions spanning 32 fields, along with verified answers and attributions for claims in the answers.
Create account to get full access
Overview
- As language models become more widely used, it's crucial that they provide accurate, verifiable information, especially in high-stakes fields like medicine and law.
- Previous studies on factuality and attribution of language model outputs have not focused on domain-specific scenarios.
- This research aims to address this gap by conducting a human evaluation of language model responses across various fields of study.
Plain English Explanation
Language models, which are AI systems that can generate human-like text, are being used in an increasing number of applications. However, it's essential that these models provide information that is factually correct and supported by reliable sources, particularly in areas like healthcare and law where inaccurate information can have serious consequences.
In the past, researchers have looked at the factuality and attribution (i.e., how well the model can cite its sources) of language model outputs, but they haven't focused on how these characteristics play out in specific fields of study. This new research aims to fill that gap by having experts in various domains evaluate the responses generated by language models.
The researchers first collected questions from 484 participants across 32 different fields, such as biology, history, and engineering. Then, they asked the same experts to assess the factuality and attribution of the language models' responses to their own questions. The experts were also asked to improve upon the language model responses.
The result of this process is a new dataset called ExpertQA, which contains 2,177 high-quality, long-form questions spanning 32 fields, along with verified answers and information about the factual claims and sources used in those answers.
Technical Explanation
The researchers conducted a human evaluation of language model outputs across various domains to assess their factuality and attribution. They first collected 2,177 expert-curated questions from 484 participants across 32 fields of study, including medicine, law, history, and engineering.
Next, the researchers presented these questions to language models and asked the original experts to evaluate the factuality and attribution of the generated responses. The experts were also asked to provide improved responses based on the language model outputs.
The resulting ExpertQA dataset includes the original expert-provided questions, the language model responses, the expert evaluations of factuality and attribution, and the expert-improved responses. This dataset allows for a detailed analysis of how well language models perform in terms of providing accurate, verifiable information in domain-specific scenarios.
Critical Analysis
The researchers acknowledge that their study is limited to the evaluation of a few representative language models, and that the findings may not generalize to all existing systems. They also note that the expert evaluations could be subjective, and that the process of improving the language model responses may have introduced human biases.
Additionally, the researchers did not explore the potential reasons for the language models' performance issues, such as the training data, model architectures, or prompting strategies used. Further research is needed to understand the underlying factors that contribute to the factuality and attribution of language model outputs in high-stakes domains.
It would also be valuable to investigate how the ExpertQA dataset could be used to develop or fine-tune language models that are better equipped to provide accurate, verifiable information in domain-specific contexts. The dataset could serve as a benchmark for evaluating and improving the reliability of language models in critical applications.
Conclusion
This research highlights the importance of ensuring that language models provide factually correct information supported by verifiable sources, especially in high-stakes fields like medicine and law. By conducting a human evaluation of language model responses across a diverse range of domains, the researchers have created a valuable dataset that can be used to better understand and improve the factuality and attribution of these AI systems.
The findings from this study underscore the need for continued research and development in this area, as language models become increasingly integrated into various applications that have significant societal impact. Maintaining the reliability and trustworthiness of these models is crucial for their safe and responsible deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
Towards Faithful and Robust LLM Specialists for Evidence-Based Question-Answering
Tobias Schimanski, Jingwei Ni, Mathias Kraus, Elliott Ash, Markus Leippold
0
0
Advances towards more faithful and traceable answers of Large Language Models (LLMs) are crucial for various research and practical endeavors. One avenue in reaching this goal is basing the answers on reliable sources. However, this Evidence-Based QA has proven to work insufficiently with LLMs in terms of citing the correct sources (source quality) and truthfully representing the information within sources (answer attributability). In this work, we systematically investigate how to robustly fine-tune LLMs for better source quality and answer attributability. Specifically, we introduce a data generation pipeline with automated data quality filters, which can synthesize diversified high-quality training and testing data at scale. We further introduce four test sets to benchmark the robustness of fine-tuned specialist models. Extensive evaluation shows that fine-tuning on synthetic data improves performance on both in- and out-of-distribution. Furthermore, we show that data quality, which can be drastically improved by proposed quality filters, matters more than quantity in improving Evidence-Based QA.
6/4/2024
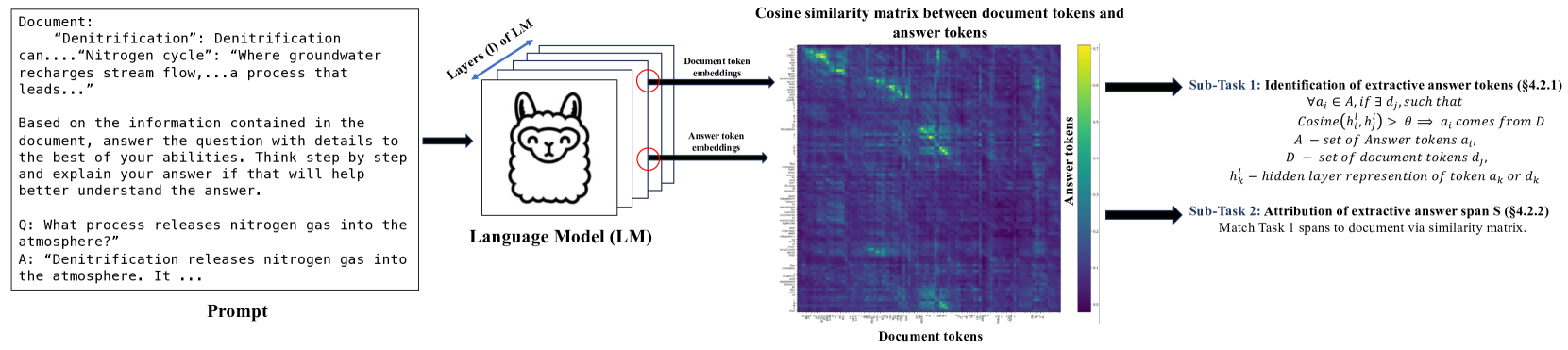
Peering into the Mind of Language Models: An Approach for Attribution in Contextual Question Answering
Anirudh Phukan, Shwetha Somasundaram, Apoorv Saxena, Koustava Goswami, Balaji Vasan Srinivasan
0
0
With the enhancement in the field of generative artificial intelligence (AI), contextual question answering has become extremely relevant. Attributing model generations to the input source document is essential to ensure trustworthiness and reliability. We observe that when large language models (LLMs) are used for contextual question answering, the output answer often consists of text copied verbatim from the input prompt which is linked together with glue text generated by the LLM. Motivated by this, we propose that LLMs have an inherent awareness from where the text was copied, likely captured in the hidden states of the LLM. We introduce a novel method for attribution in contextual question answering, leveraging the hidden state representations of LLMs. Our approach bypasses the need for extensive model retraining and retrieval model overhead, offering granular attributions and preserving the quality of generated answers. Our experimental results demonstrate that our method performs on par or better than GPT-4 at identifying verbatim copied segments in LLM generations and in attributing these segments to their source. Importantly, our method shows robust performance across various LLM architectures, highlighting its broad applicability. Additionally, we present Verifiability-granular, an attribution dataset which has token level annotations for LLM generations in the contextual question answering setup.
5/29/2024

Facilitating Human-LLM Collaboration through Factuality Scores and Source Attributions
Hyo Jin Do, Rachel Ostrand, Justin D. Weisz, Casey Dugan, Prasanna Sattigeri, Dennis Wei, Keerthiram Murugesan, Werner Geyer
0
0
While humans increasingly rely on large language models (LLMs), they are susceptible to generating inaccurate or false information, also known as hallucinations. Technical advancements have been made in algorithms that detect hallucinated content by assessing the factuality of the model's responses and attributing sections of those responses to specific source documents. However, there is limited research on how to effectively communicate this information to users in ways that will help them appropriately calibrate their trust toward LLMs. To address this issue, we conducted a scenario-based study (N=104) to systematically compare the impact of various design strategies for communicating factuality and source attribution on participants' ratings of trust, preferences, and ease in validating response accuracy. Our findings reveal that participants preferred a design in which phrases within a response were color-coded based on the computed factuality scores. Additionally, participants increased their trust ratings when relevant sections of the source material were highlighted or responses were annotated with reference numbers corresponding to those sources, compared to when they received no annotation in the source material. Our study offers practical design guidelines to facilitate human-LLM collaboration and it promotes a new human role to carefully evaluate and take responsibility for their use of LLM outputs.
6/3/2024

Improving Health Question Answering with Reliable and Time-Aware Evidence Retrieval
Juraj Vladika, Florian Matthes
0
0
In today's digital world, seeking answers to health questions on the Internet is a common practice. However, existing question answering (QA) systems often rely on using pre-selected and annotated evidence documents, thus making them inadequate for addressing novel questions. Our study focuses on the open-domain QA setting, where the key challenge is to first uncover relevant evidence in large knowledge bases. By utilizing the common retrieve-then-read QA pipeline and PubMed as a trustworthy collection of medical research documents, we answer health questions from three diverse datasets. We modify different retrieval settings to observe their influence on the QA pipeline's performance, including the number of retrieved documents, sentence selection process, the publication year of articles, and their number of citations. Our results reveal that cutting down on the amount of retrieved documents and favoring more recent and highly cited documents can improve the final macro F1 score up to 10%. We discuss the results, highlight interesting examples, and outline challenges for future research, like managing evidence disagreement and crafting user-friendly explanations.
4/15/2024