Fast Chain-of-Thought: A Glance of Future from Parallel Decoding Leads to Answers Faster
2311.08263
0
0
🎲
Abstract
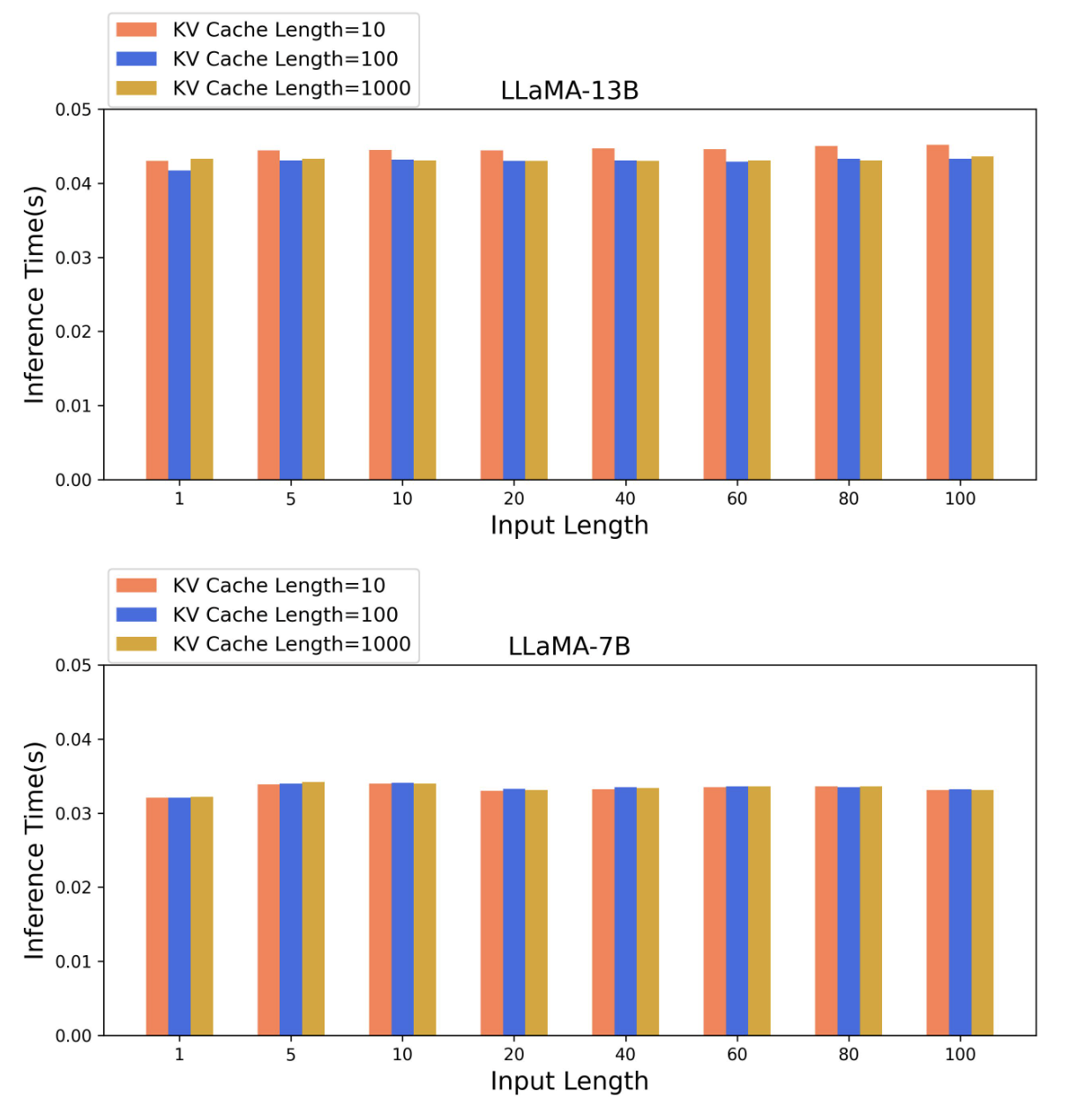
In this work, we propose FastCoT, a model-agnostic framework based on parallel decoding without any further training of an auxiliary model or modification to the LLM itself. FastCoT uses a size-varying context window whose size changes with position to conduct parallel decoding and auto-regressive decoding simultaneously, thus fully utilizing GPU computation resources. In FastCoT, the parallel decoding part provides the LLM with a quick glance of the future composed of approximate tokens, which could lead to faster answers compared to regular autoregressive decoding used by causal transformers. We also provide an implementation of parallel decoding within LLM, which supports KV-cache generation and batch processing. Through extensive experiments, we demonstrate that FastCoT saves inference time by nearly 20% with only a negligible performance drop compared to the regular approach. Additionally, we show that the context window size exhibits considerable robustness for different tasks.
Create account to get full access
Overview
- Proposes a new model-agnostic framework called FastCoT for faster language model inference
- Uses parallel decoding with a size-varying context window to leverage GPU resources and provide the model with an approximate glimpse of the future
- Claims to save up to 20% in inference time compared to regular autoregressive decoding, with only a negligible performance drop
Plain English Explanation
FastCoT is a new technique that aims to make large language models (LLMs) run faster during inference (when the model is being used to generate text). It does this by using a parallel decoding approach, which means the model can process multiple parts of the text at the same time, rather than strictly one word after another.
Typically, LLMs use autoregressive decoding, where they generate text one word at a time, with each new word depending on the previous ones. FastCoT keeps this autoregressive decoding, but also adds a parallel decoding component that gives the model a quick preview of what the future text might look like. This parallel part doesn't have to be 100% accurate - it just provides the model with a rough idea of what's coming next.
By using both parallel and autoregressive decoding together, FastCoT can fully utilize the computational resources of the GPU, leading to faster text generation compared to regular autoregressive decoding alone. The authors claim this can save about 20% on inference time, with only a small drop in the quality of the generated text.
Additionally, the authors show that the size of the "context window" used for parallel decoding can be adjusted quite a bit without significantly impacting performance, making the approach more flexible and robust.
Technical Explanation
FastCoT is a model-agnostic framework that combines parallel decoding and autoregressive decoding to accelerate inference for large language models (LLMs). The parallel decoding component provides the LLM with a quick approximation of future tokens, which can lead to faster text generation compared to regular autoregressive decoding.
The key innovation in FastCoT is the use of a size-varying context window, where the size of the window changes based on the position in the text. This allows the parallel decoding to fully utilize the GPU's computational resources. The authors also provide an implementation of parallel decoding within the LLM, which supports generation of the key-value cache and batch processing.
Through extensive experiments, the authors demonstrate that FastCoT can save inference time by nearly 20% compared to regular autoregressive decoding, with only a negligible performance drop. They also show that the context window size exhibits considerable robustness across different tasks, making the approach more flexible.
Critical Analysis
The FastCoT paper presents a promising approach for accelerating LLM inference, but there are a few potential limitations and areas for further research:
-
Generalization to different models: The authors primarily evaluate FastCoT on the GPT-2 and GPT-3 models. It would be valuable to see how well the technique generalizes to a wider range of LLMs, including those with different architectural choices or training procedures.
-
Handling of long-range dependencies: While the size-varying context window approach seems to work well, it's unclear how effective it would be for tasks that require modeling long-range dependencies in the text. Further investigation may be needed to understand the limitations of this approach in such scenarios.
-
Impact on model performance: The authors report only a "negligible" performance drop, but it would be helpful to have a more detailed analysis of the impact on key metrics like perplexity, task-specific scores, and human evaluations. Certain applications may be more sensitive to changes in text quality.
-
Computational overhead: The parallel decoding component adds some additional computational overhead, which may offset the benefits of faster inference in certain settings. A more thorough analysis of the trade-offs between speed and computational cost would be valuable.
-
Comparison to other approaches: It would be interesting to see how FastCoT compares to other techniques for accelerating LLM inference, such as KV-RunAhead, Decoding at Speed, or Chain-of-Thought reasoning.
Overall, the FastCoT paper presents an interesting and potentially impactful approach for improving the efficiency of LLM inference. Further research and real-world deployment will help clarify the strengths, limitations, and practical applications of this technique.
Conclusion
The FastCoT framework proposes a novel way to accelerate the inference of large language models by combining parallel decoding and autoregressive decoding. The key innovation is the use of a size-varying context window, which allows the parallel decoding component to fully leverage GPU resources and provide the LLM with a quick approximation of future tokens.
Through extensive experiments, the authors demonstrate that FastCoT can save inference time by nearly 20% compared to regular autoregressive decoding, with only a negligible performance drop. The approach also exhibits considerable robustness in terms of the context window size, making it more flexible and adaptable to different tasks and scenarios.
If successful, this type of acceleration technique could have significant implications for the real-world deployment of large language models, enabling faster and more efficient text generation for a wide range of applications, from conversational AI to content creation and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Parallel Decoding via Hidden Transfer for Lossless Large Language Model Acceleration
Pengfei Wu, Jiahao Liu, Zhuocheng Gong, Qifan Wang, Jinpeng Li, Jingang Wang, Xunliang Cai, Dongyan Zhao
0
0
Large language models (LLMs) have recently shown remarkable performance across a wide range of tasks. However, the substantial number of parameters in LLMs contributes to significant latency during model inference. This is particularly evident when utilizing autoregressive decoding methods, which generate one token in a single forward process, thereby not fully capitalizing on the parallel computing capabilities of GPUs. In this paper, we propose a novel parallel decoding approach, namely textit{hidden transfer}, which decodes multiple successive tokens simultaneously in a single forward pass. The idea is to transfer the intermediate hidden states of the previous context to the textit{pseudo} hidden states of the future tokens to be generated, and then the pseudo hidden states will pass the following transformer layers thereby assimilating more semantic information and achieving superior predictive accuracy of the future tokens. Besides, we use the novel tree attention mechanism to simultaneously generate and verify multiple candidates of output sequences, which ensure the lossless generation and further improves the generation efficiency of our method. Experiments demonstrate the effectiveness of our method. We conduct a lot of analytic experiments to prove our motivation. In terms of acceleration metrics, we outperform all the single-model acceleration techniques, including Medusa and Self-Speculative decoding.
4/19/2024

CLLMs: Consistency Large Language Models
Siqi Kou, Lanxiang Hu, Zhezhi He, Zhijie Deng, Hao Zhang
0
0
Parallel decoding methods such as Jacobi decoding show promise for more efficient LLM inference as it breaks the sequential nature of the LLM decoding process and transforms it into parallelizable computation. However, in practice, it achieves little speedup compared to traditional autoregressive (AR) decoding, primarily because Jacobi decoding seldom accurately predicts more than one token in a single fixed-point iteration step. To address this, we develop a new approach aimed at realizing fast convergence from any state to the fixed point on a Jacobi trajectory. This is accomplished by refining the target LLM to consistently predict the fixed point given any state as input. Extensive experiments demonstrate the effectiveness of our method, showing 2.4$times$ to 3.4$times$ improvements in generation speed while preserving generation quality across both domain-specific and open-domain benchmarks.
6/14/2024
Chain of Thought Empowers Transformers to Solve Inherently Serial Problems
Zhiyuan Li, Hong Liu, Denny Zhou, Tengyu Ma
0
0
Instructing the model to generate a sequence of intermediate steps, a.k.a., a chain of thought (CoT), is a highly effective method to improve the accuracy of large language models (LLMs) on arithmetics and symbolic reasoning tasks. However, the mechanism behind CoT remains unclear. This work provides a theoretical understanding of the power of CoT for decoder-only transformers through the lens of expressiveness. Conceptually, CoT empowers the model with the ability to perform inherently serial computation, which is otherwise lacking in transformers, especially when depth is low. Given input length $n$, previous works have shown that constant-depth transformers with finite precision $mathsf{poly}(n)$ embedding size can only solve problems in $mathsf{TC}^0$ without CoT. We first show an even tighter expressiveness upper bound for constant-depth transformers with constant-bit precision, which can only solve problems in $mathsf{AC}^0$, a proper subset of $ mathsf{TC}^0$. However, with $T$ steps of CoT, constant-depth transformers using constant-bit precision and $O(log n)$ embedding size can solve any problem solvable by boolean circuits of size $T$. Empirically, enabling CoT dramatically improves the accuracy for tasks that are hard for parallel computation, including the composition of permutation groups, iterated squaring, and circuit value problems, especially for low-depth transformers.
5/24/2024

Decoding at the Speed of Thought: Harnessing Parallel Decoding of Lexical Units for LLMs
Chenxi Sun, Hongzhi Zhang, Zijia Lin, Jingyuan Zhang, Fuzheng Zhang, Zhongyuan Wang, Bin Chen, Chengru Song, Di Zhang, Kun Gai, Deyi Xiong
0
0
Large language models have demonstrated exceptional capability in natural language understanding and generation. However, their generation speed is limited by the inherently sequential nature of their decoding process, posing challenges for real-time applications. This paper introduces Lexical Unit Decoding (LUD), a novel decoding methodology implemented in a data-driven manner, accelerating the decoding process without sacrificing output quality. The core of our approach is the observation that a pre-trained language model can confidently predict multiple contiguous tokens, forming the basis for a textit{lexical unit}, in which these contiguous tokens could be decoded in parallel. Extensive experiments validate that our method substantially reduces decoding time while maintaining generation quality, i.e., 33% speed up on natural language generation with no quality loss, and 30% speed up on code generation with a negligible quality loss of 3%. Distinctively, LUD requires no auxiliary models and does not require changes to existing architectures. It can also be integrated with other decoding acceleration methods, thus achieving an even more pronounced inference efficiency boost. We posit that the foundational principles of LUD could define a new decoding paradigm for future language models, enhancing their applicability for a broader spectrum of applications. All codes are be publicly available at https://github.com/tjunlp-lab/Lexical-Unit-Decoding-LUD-. Keywords: Parallel Decoding, Lexical Unit Decoding, Large Language Model
5/27/2024