FedAQ: Communication-Efficient Federated Edge Learning via Joint Uplink and Downlink Adaptive Quantization
2406.18156
0
0

Abstract
Federated learning (FL) is a powerful machine learning paradigm which leverages the data as well as the computational resources of clients, while protecting clients' data privacy. However, the substantial model size and frequent aggregation between the server and clients result in significant communication overhead, making it challenging to deploy FL in resource-limited wireless networks. In this work, we aim to mitigate the communication overhead by using quantization. Previous research on quantization has primarily focused on the uplink communication, employing either fixed-bit quantization or adaptive quantization methods. In this work, we introduce a holistic approach by joint uplink and downlink adaptive quantization to reduce the communication overhead. In particular, we optimize the learning convergence by determining the optimal uplink and downlink quantization bit-length, with a communication energy constraint. Theoretical analysis shows that the optimal quantization levels depend on the range of model gradients or weights. Based on this insight, we propose a decreasing-trend quantization for the uplink and an increasing-trend quantization for the downlink, which aligns with the change of the model parameters during the training process. Experimental results show that, the proposed joint uplink and downlink adaptive quantization strategy can save up to 66.7% energy compared with the existing schemes.
Create account to get full access
Overview
- Federated learning (FL) is a collaborative machine learning approach that allows multiple devices to train a shared model without sharing their raw data.
- Communication efficiency is a key challenge in FL, as frequent data exchanges between devices and a central server can be costly and slow.
- The paper introduces FedAQ, a novel FL framework that employs adaptive quantization to reduce the communication overhead in both the uplink (device-to-server) and downlink (server-to-device) directions.
Plain English Explanation
FedAQ is a new approach to federated learning that aims to make the communication more efficient. In traditional federated learning, devices like phones or sensors send their trained model updates to a central server, which then aggregates the updates and sends the new model back to the devices. This back-and-forth communication can be slow and expensive, especially for devices with limited bandwidth or computing power.
To address this, FedAQ uses a technique called "adaptive quantization" to compress the data being sent in both directions. This means that the values in the model updates are converted into a smaller number of bits, reducing the amount of data that needs to be transmitted. The key insight is that the quantization can be adjusted dynamically based on the characteristics of the data, allowing for greater compression without losing too much accuracy.
By reducing the communication overhead, FedAQ can enable federated learning to work more effectively on devices at the "edge" of the network, such as smartphones, sensors, and IoT devices. This could lead to improvements in areas like personalized AI assistants, smart home systems, and distributed monitoring applications.
Technical Explanation
FedAQ employs a joint uplink and downlink adaptive quantization scheme to improve the communication efficiency of federated learning. In the uplink, the model updates from client devices are quantized using a learnable clipped uniform quantizer, which adaptively adjusts the quantization levels based on the distribution of the update values. In the downlink, the server-to-client model transmissions are also quantized using a similar adaptive quantizer.
The key technical contributions of FedAQ include:
- Adaptive Quantization: The quantization parameters (e.g., number of bits, clipping thresholds) are dynamically adjusted during training to optimize the trade-off between communication cost and model accuracy.
- Joint Uplink and Downlink Optimization: The uplink and downlink quantizers are jointly optimized to minimize the overall communication overhead while preserving model performance.
- Theoretical Analysis: The authors provide convergence guarantees for FedAQ and analyze the impact of quantization on the model's performance.
Experiments on various datasets and model architectures demonstrate that FedAQ can achieve significant communication savings (up to 90%) compared to standard federated learning approaches, with only a minor impact on model accuracy. The benefits of FedAQ are particularly pronounced in federated learning scenarios with limited bandwidth or computationally-constrained edge devices.
Critical Analysis
The FedAQ approach addresses an important challenge in federated learning, but there are a few potential limitations and areas for further research:
- Heterogeneous Devices: The paper assumes that all client devices have similar data distributions and computational capabilities. In real-world scenarios, client devices can be highly heterogeneous, which may require more sophisticated quantization strategies.
- Robustness to Noise: The adaptive quantization in FedAQ may be sensitive to noise or communication errors, which could impact the model's performance. Investigating the robustness of the approach in noisy environments would be valuable.
- Scalability: As the number of clients grows, the computational and communication overhead of the joint uplink-downlink optimization in FedAQ may become a bottleneck. Exploring more scalable quantization methods could broaden the applicability of the approach.
- Real-world Deployments: The paper evaluates FedAQ on standard machine learning benchmarks, but the impact of quantization on the performance of federated learning models in real-world scenarios may differ. Further research is needed to understand the practical implications of the technique.
Overall, FedAQ represents a promising step towards more communication-efficient federated learning, but additional research is needed to address the challenges of heterogeneous devices, noise robustness, and real-world deployments.
Conclusion
FedAQ is a novel federated learning framework that employs joint uplink and downlink adaptive quantization to significantly reduce the communication overhead between client devices and the central server. By dynamically adjusting the quantization parameters, FedAQ can achieve substantial communication savings without major impacts on model accuracy, making it a valuable tool for deploying federated learning on resource-constrained edge devices.
The key innovations of FedAQ, such as the adaptive quantization scheme and the joint optimization of uplink and downlink quantizers, could have broader implications for communication-efficient distributed learning and edge computing. As the demand for federated learning continues to grow, techniques like FedAQ will play an increasingly important role in enabling scalable, privacy-preserving, and resource-efficient AI applications at the edge of the network.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Clipped Uniform Quantizers for Communication-Efficient Federated Learning
Zavareh Bozorgasl, Hao Chen
0
0
This paper introduces an approach to employ clipped uniform quantization in federated learning settings, aiming to enhance model efficiency by reducing communication overhead without compromising accuracy. By employing optimal clipping thresholds and adaptive quantization schemes, our method significantly curtails the bit requirements for model weight transmissions between clients and the server. We explore the implications of symmetric clipping and uniform quantization on model performance, highlighting the utility of stochastic quantization to mitigate quantization artifacts and improve model robustness. Through extensive simulations on the MNIST dataset, our results demonstrate that the proposed method achieves near full-precision performance while ensuring substantial communication savings. Specifically, our approach facilitates efficient weight averaging based on quantization errors, effectively balancing the trade-off between communication efficiency and model accuracy. The comparative analysis with conventional quantization methods further confirms the superiority of our technique.
5/24/2024
🛠️
FedMPQ: Secure and Communication-Efficient Federated Learning with Multi-codebook Product Quantization
Xu Yang, Jiapeng Zhang, Qifeng Zhang, Zhuo Tang
0
0
In federated learning, particularly in cross-device scenarios, secure aggregation has recently gained popularity as it effectively defends against inference attacks by malicious aggregators. However, secure aggregation often requires additional communication overhead and can impede the convergence rate of the global model, which is particularly challenging in wireless network environments with extremely limited bandwidth. Therefore, achieving efficient communication compression under the premise of secure aggregation presents a highly challenging and valuable problem. In this work, we propose a novel uplink communication compression method for federated learning, named FedMPQ, which is based on multi shared codebook product quantization.Specifically, we utilize updates from the previous round to generate sufficiently robust codebooks. Secure aggregation is then achieved through trusted execution environments (TEE) or a trusted third party (TTP).In contrast to previous works, our approach exhibits greater robustness in scenarios where data is not independently and identically distributed (non-IID) and there is a lack of sufficient public data. The experiments conducted on the LEAF dataset demonstrate that our proposed method achieves 99% of the baseline's final accuracy, while reducing uplink communications by 90-95%
4/23/2024
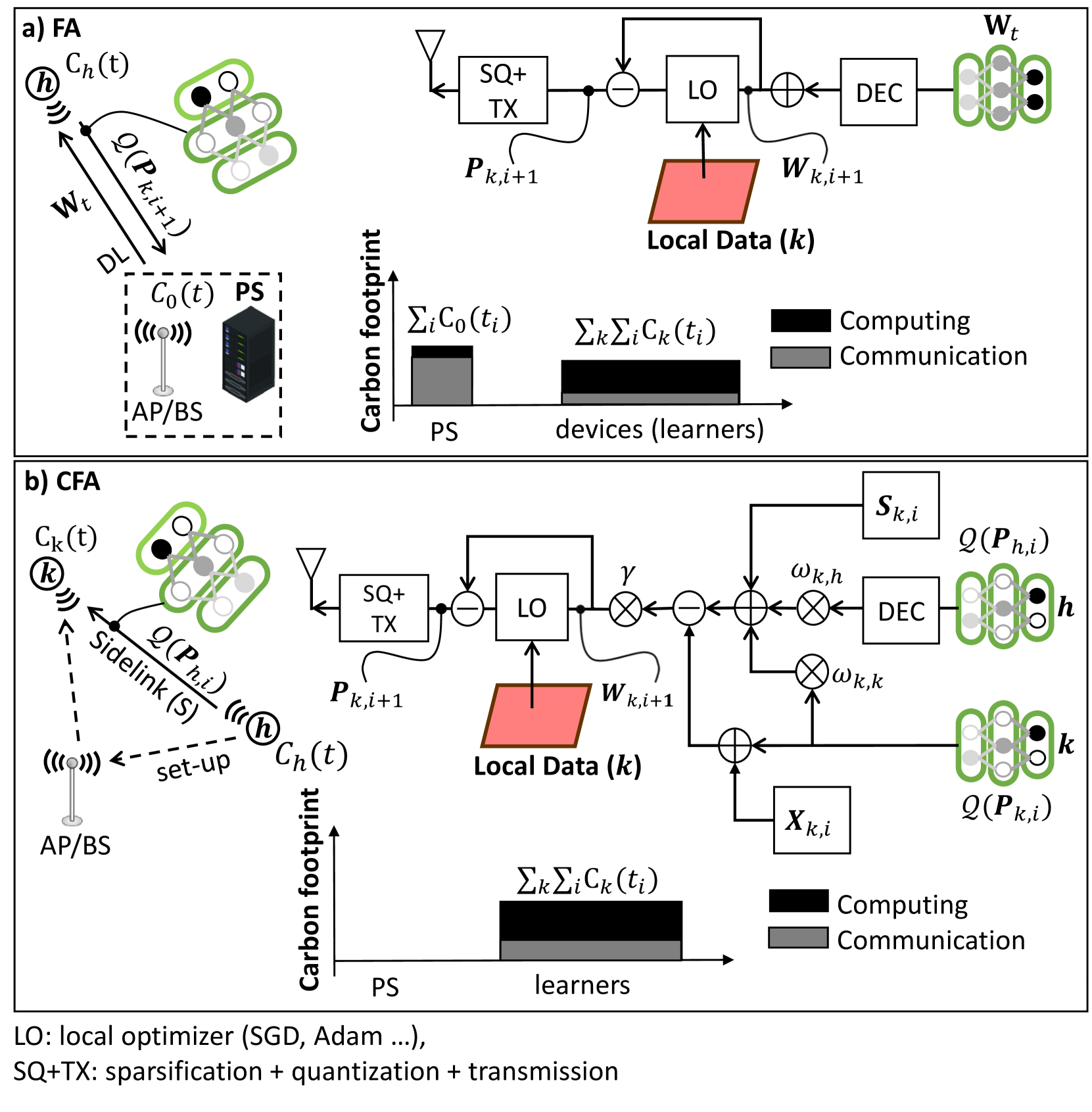
A Carbon Tracking Model for Federated Learning: Impact of Quantization and Sparsification
Luca Barbieri, Stefano Savazzi, Sanaz Kianoush, Monica Nicoli, Luigi Serio
0
0
Federated Learning (FL) methods adopt efficient communication technologies to distribute machine learning tasks across edge devices, reducing the overhead in terms of data storage and computational complexity compared to centralized solutions. Rather than moving large data volumes from producers (sensors, machines) to energy-hungry data centers, raising environmental concerns due to resource demands, FL provides an alternative solution to mitigate the energy demands of several learning tasks while enabling new Artificial Intelligence of Things (AIoT) applications. This paper proposes a framework for real-time monitoring of the energy and carbon footprint impacts of FL systems. The carbon tracking tool is evaluated for consensus (fully decentralized) and classical FL policies. For the first time, we present a quantitative evaluation of different computationally and communication efficient FL methods from the perspectives of energy consumption and carbon equivalent emissions, suggesting also general guidelines for energy-efficient design. Results indicate that consensus-driven FL implementations should be preferred for limiting carbon emissions when the energy efficiency of the communication is low (i.e., < 25 Kbit/Joule). Besides, quantization and sparsification operations are shown to strike a balance between learning performances and energy consumption, leading to sustainable FL designs.
5/27/2024
🚀
Communication-Efficient Federated Learning with Adaptive Compression under Dynamic Bandwidth
Ying Zhuansun, Dandan Li, Xiaohong Huang, Caijun Sun
0
0
Federated learning can train models without directly providing local data to the server. However, the frequent updating of the local model brings the problem of large communication overhead. Recently, scholars have achieved the communication efficiency of federated learning mainly by model compression. But they ignore two problems: 1) network state of each client changes dynamically; 2) network state among clients is not the same. The clients with poor bandwidth update local model slowly, which leads to low efficiency. To address this challenge, we propose a communication-efficient federated learning algorithm with adaptive compression under dynamic bandwidth (called AdapComFL). Concretely, each client performs bandwidth awareness and bandwidth prediction. Then, each client adaptively compresses its local model via the improved sketch mechanism based on his predicted bandwidth. Further, the server aggregates sketched models with different sizes received. To verify the effectiveness of the proposed method, the experiments are based on real bandwidth data which are collected from the network topology we build, and benchmark datasets which are obtained from open repositories. We show the performance of AdapComFL algorithm, and compare it with existing algorithms. The experimental results show that our AdapComFL achieves more efficient communication as well as competitive accuracy compared to existing algorithms.
5/7/2024