Flexible SE(2) graph neural networks with applications to PDE surrogates
2405.20287
0
0

Abstract
This paper presents a novel approach for constructing graph neural networks equivariant to 2D rotations and translations and leveraging them as PDE surrogates on non-gridded domains. We show that aligning the representations with the principal axis allows us to sidestep many constraints while preserving SE(2) equivariance. By applying our model as a surrogate for fluid flow simulations and conducting thorough benchmarks against non-equivariant models, we demonstrate significant gains in terms of both data efficiency and accuracy.
Create account to get full access
Overview
- This paper introduces a novel type of graph neural network (GNN) called Flexible SE(2) GNNs, which can be applied to a variety of partial differential equation (PDE) problems.
- The key innovations include the ability to handle irregular spatial domains, learn rotation-equivariant representations, and achieve state-of-the-art performance on PDE surrogate modeling tasks.
- The paper demonstrates the effectiveness of Flexible SE(2) GNNs on several benchmark PDE problems, showing significant improvements over existing methods.
Plain English Explanation
Partial differential equations (PDEs) are mathematical models that describe how various physical quantities, such as temperature or fluid flow, change over space and time. These PDEs are widely used in science and engineering, but solving them can be computationally expensive, especially for complex geometries or high-dimensional systems.
Flexible SE(2) graph neural networks with applications to PDE surrogates introduces a new type of machine learning model called a "Flexible SE(2) Graph Neural Network" that can be used to efficiently approximate the solutions to PDEs. This approach has several key advantages:
-
Handling Irregular Spatial Domains: Traditional neural network models often struggle with complex geometric shapes, but Flexible SE(2) GNNs can handle irregular spatial domains by representing the problem as a graph, where the nodes correspond to points in the domain and the edges represent the connections between them.
-
Learning Rotation-Equivariant Representations: Many physical systems, like fluid dynamics, exhibit rotational symmetry. Flexible SE(2) GNNs can learn representations that are equivariant to rotations, meaning that the model's outputs transform in a predictable way when the input is rotated. This can improve the model's performance and generalization.
-
Achieving State-of-the-Art Performance: The paper demonstrates that Flexible SE(2) GNNs outperform other machine learning methods on several benchmark PDE problems, including fluid flow, heat transfer, and wave propagation. This suggests that the model can serve as an effective "surrogate" for computationally expensive PDE solvers.
Overall, this research represents an important advance in the field of geometric deep learning, which aims to develop neural network architectures that can better capture the underlying geometric structure of data. By applying these techniques to PDE surrogate modeling, the paper opens up new possibilities for efficiently simulating complex physical systems using machine learning.
Technical Explanation
The core idea behind Flexible SE(2) GNNs is to represent the spatial domain of a PDE problem as a graph, where the nodes correspond to points in the domain and the edges represent the connections between them. This allows the model to handle irregular geometries and learn representations that are equivariant to rotations.
The key components of the Flexible SE(2) GNN architecture include:
-
Graph Representation: The spatial domain is discretized into a graph, where the node features encode information about the PDE, such as the values of the dependent variables and their derivatives.
-
SE(2)-Equivariant Convolutions: The model uses a novel type of convolution operation that is equivariant to translations and rotations in the 2D plane. This allows the model to learn representations that capture the underlying symmetries of the PDE.
-
Flexible Pooling and Unpooling: The graph structure is adaptively coarsened and refined during the model's computations, allowing it to efficiently capture features at multiple scales.
The paper evaluates the performance of Flexible SE(2) GNNs on several benchmark PDE problems, including fluid flow, heat transfer, and wave propagation. The results show that the proposed model outperforms other machine learning approaches, such as traditional convolutional neural networks and physics-informed neural networks, in terms of both accuracy and computational efficiency.
Critical Analysis
One potential limitation of the Flexible SE(2) GNN approach is that it relies on a discretized graph representation of the spatial domain, which may not capture all the fine-grained details of the underlying PDE. While the paper demonstrates that the model can handle irregular geometries, it's unclear how well it would perform on problems with highly complex or multi-scale spatial structures.
Additionally, the paper does not provide a comprehensive analysis of the model's robustness to variations in the PDE parameters or boundary conditions. It would be interesting to see how the model's performance scales with the complexity of the PDE problem and the degree of irregularity in the spatial domain.
Finally, while the paper highlights the potential for using Flexible SE(2) GNNs as efficient PDE surrogates, it does not address the practical challenges of deploying such models in real-world applications, such as the need for reliable uncertainty quantification and the computational overhead of training and inference.
Conclusion
Flexible SE(2) graph neural networks with applications to PDE surrogates represents an important advancement in the field of geometric deep learning, providing a novel neural network architecture that can effectively capture the underlying symmetries and spatial structures of partial differential equations. By demonstrating state-of-the-art performance on a range of benchmark PDE problems, the paper opens up new possibilities for using machine learning to accelerate the simulation and analysis of complex physical systems. While the approach has some limitations, it lays the groundwork for further research and development in this exciting area of PDE surrogate modeling and equivariant neural networks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
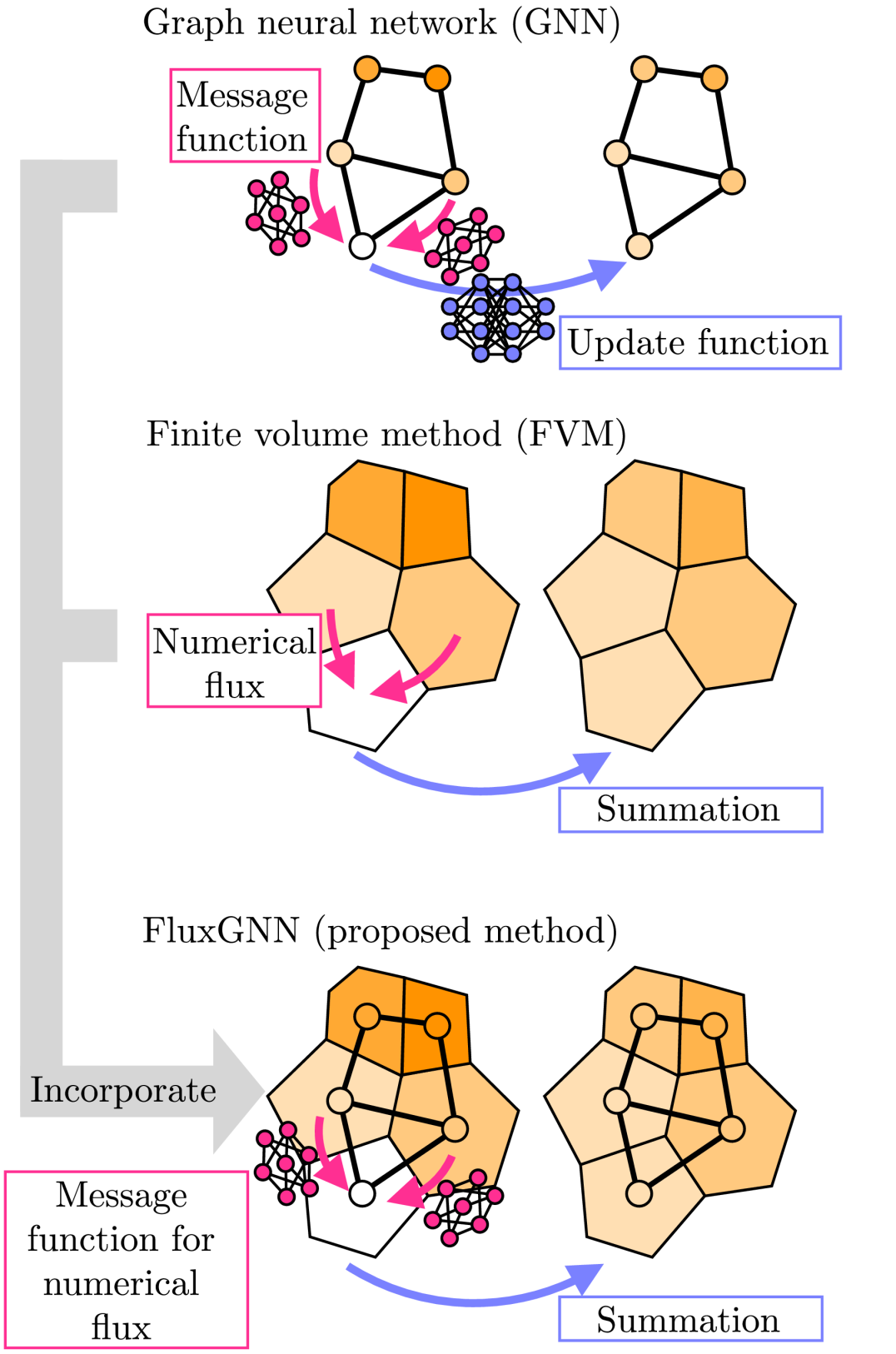
Graph Neural PDE Solvers with Conservation and Similarity-Equivariance
Masanobu Horie, Naoto Mitsume
0
0
Utilizing machine learning to address partial differential equations (PDEs) presents significant challenges due to the diversity of spatial domains and their corresponding state configurations, which complicates the task of encompassing all potential scenarios through data-driven methodologies alone. Moreover, there are legitimate concerns regarding the generalization and reliability of such approaches, as they often overlook inherent physical constraints. In response to these challenges, this study introduces a novel machine-learning architecture that is highly generalizable and adheres to conservation laws and physical symmetries, thereby ensuring greater reliability. The foundation of this architecture is graph neural networks (GNNs), which are adept at accommodating a variety of shapes and forms. Additionally, we explore the parallels between GNNs and traditional numerical solvers, facilitating a seamless integration of conservative principles and symmetries into machine learning models. Our findings from experiments demonstrate that the model's inclusion of physical laws significantly enhances its generalizability, i.e., no significant accuracy degradation for unseen spatial domains while other models degrade. The code is available at https://github.com/yellowshippo/fluxgnn-icml2024.
5/28/2024
🧠
Unifying O(3) Equivariant Neural Networks Design with Tensor-Network Formalism
Zimu Li, Zihan Pengmei, Han Zheng, Erik Thiede, Junyu Liu, Risi Kondor
0
0
Many learning tasks, including learning potential energy surfaces from ab initio calculations, involve global spatial symmetries and permutational symmetry between atoms or general particles. Equivariant graph neural networks are a standard approach to such problems, with one of the most successful methods employing tensor products between various tensors that transform under the spatial group. However, as the number of different tensors and the complexity of relationships between them increase, maintaining parsimony and equivariance becomes increasingly challenging. In this paper, we propose using fusion diagrams, a technique widely employed in simulating SU($2$)-symmetric quantum many-body problems, to design new equivariant components for equivariant neural networks. This results in a diagrammatic approach to constructing novel neural network architectures. When applied to particles within a given local neighborhood, the resulting components, which we term fusion blocks, serve as universal approximators of any continuous equivariant function defined in the neighborhood. We incorporate a fusion block into pre-existing equivariant architectures (Cormorant and MACE), leading to improved performance with fewer parameters on a range of challenging chemical problems. Furthermore, we apply group-equivariant neural networks to study non-adiabatic molecular dynamics of stilbene cis-trans isomerization. Our approach, which combines tensor networks with equivariant neural networks, suggests a potentially fruitful direction for designing more expressive equivariant neural networks.
5/24/2024
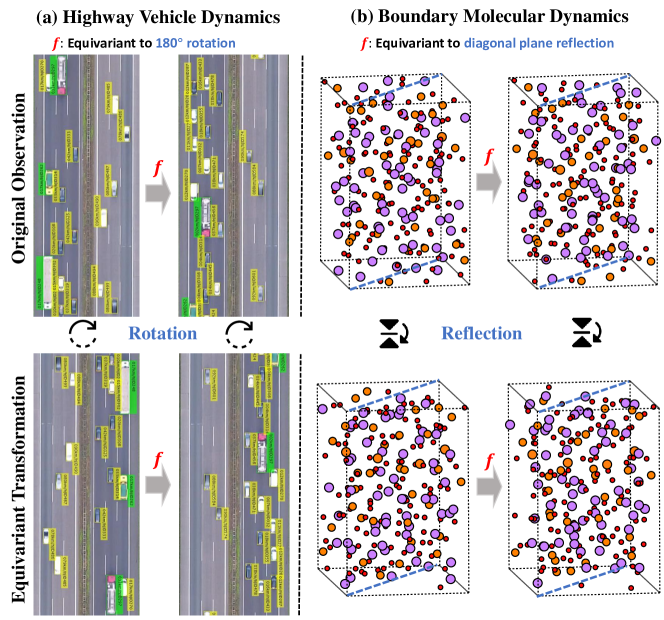
Relaxing Continuous Constraints of Equivariant Graph Neural Networks for Physical Dynamics Learning
Zinan Zheng, Yang Liu, Jia Li, Jianhua Yao, Yu Rong
0
0
Incorporating Euclidean symmetries (e.g. rotation equivariance) as inductive biases into graph neural networks has improved their generalization ability and data efficiency in unbounded physical dynamics modeling. However, in various scientific and engineering applications, the symmetries of dynamics are frequently discrete due to the boundary conditions. Thus, existing GNNs either overlook necessary symmetry, resulting in suboptimal representation ability, or impose excessive equivariance, which fails to generalize to unobserved symmetric dynamics. In this work, we propose a general Discrete Equivariant Graph Neural Network (DEGNN) that guarantees equivariance to a given discrete point group. Specifically, we show that such discrete equivariant message passing could be constructed by transforming geometric features into permutation-invariant embeddings. Through relaxing continuous equivariant constraints, DEGNN can employ more geometric feature combinations to approximate unobserved physical object interaction functions. Two implementation approaches of DEGNN are proposed based on ranking or pooling permutation-invariant functions. We apply DEGNN to various physical dynamics, ranging from particle, molecular, crowd to vehicle dynamics. In twenty scenarios, DEGNN significantly outperforms existing state-of-the-art approaches. Moreover, we show that DEGNN is data efficient, learning with less data, and can generalize across scenarios such as unobserved orientation.
6/26/2024
Scalable Expressiveness through Preprocessed Graph Perturbations
Danial Saber, Amirali Salehi-Abari
0
0
Graph Neural Networks (GNNs) have emerged as the predominant method for analyzing graph-structured data. However, canonical GNNs have limited expressive power and generalization capability, thus triggering the development of more expressive yet computationally intensive methods. One such approach is to create a series of perturbed versions of input graphs and then repeatedly conduct multiple message-passing operations on all variations during training. Despite their expressive power, this approach does not scale well on larger graphs. To address this scalability issue, we introduce Scalable Expressiveness through Preprocessed Graph Perturbation (SE2P). This model offers a flexible, configurable balance between scalability and generalizability with four distinct configuration classes. At one extreme, the configuration prioritizes scalability through minimal learnable feature extraction and extensive preprocessing; at the other extreme, it enhances generalizability with more learnable feature extractions, though this increases scalability costs. We conduct extensive experiments on real-world datasets to evaluate the generalizability and scalability of SE2P variants compared to various state-of-the-art benchmarks. Our results indicate that, depending on the chosen SE2P configuration, the model can enhance generalizability compared to benchmarks while achieving significant speed improvements of up to 8-fold.
6/18/2024