FLIGAN: Enhancing Federated Learning with Incomplete Data using GAN
2403.16930
0
0
Abstract
Federated Learning (FL) provides a privacy-preserving mechanism for distributed training of machine learning models on networked devices (e.g., mobile devices, IoT edge nodes). It enables Artificial Intelligence (AI) at the edge by creating models without sharing actual data across the network. Existing research typically focuses on generic aspects of non-IID data and heterogeneity in client's system characteristics, but they often neglect the issue of insufficient data for model development, which can arise from uneven class label distribution and highly variable data volumes across edge nodes. In this work, we propose FLIGAN, a novel approach to address the issue of data incompleteness in FL. First, we leverage Generative Adversarial Networks (GANs) to adeptly capture complex data distributions and generate synthetic data that closely resemble real-world data. Then, we use synthetic data to enhance the robustness and completeness of datasets across nodes. Our methodology adheres to FL's privacy requirements by generating synthetic data in a federated manner without sharing the actual data in the process. We incorporate techniques such as classwise sampling and node grouping, designed to improve the federated GAN's performance, enabling the creation of high-quality synthetic datasets and facilitating efficient FL training. Empirical results from our experiments demonstrate that FLIGAN significantly improves model accuracy, especially in scenarios with high class imbalances, achieving up to a 20% increase in model accuracy over traditional FL baselines.
Create account to get full access
Overview
- Federated learning is a distributed machine learning technique where multiple devices collaboratively train a shared model without sharing their local data.
- Data incompleteness is a challenge in federated learning, as devices may have missing or partial data.
- This paper introduces FLIGAN, a framework that uses Generative Adversarial Networks (GANs) to enhance federated learning with incomplete data.
Plain English Explanation
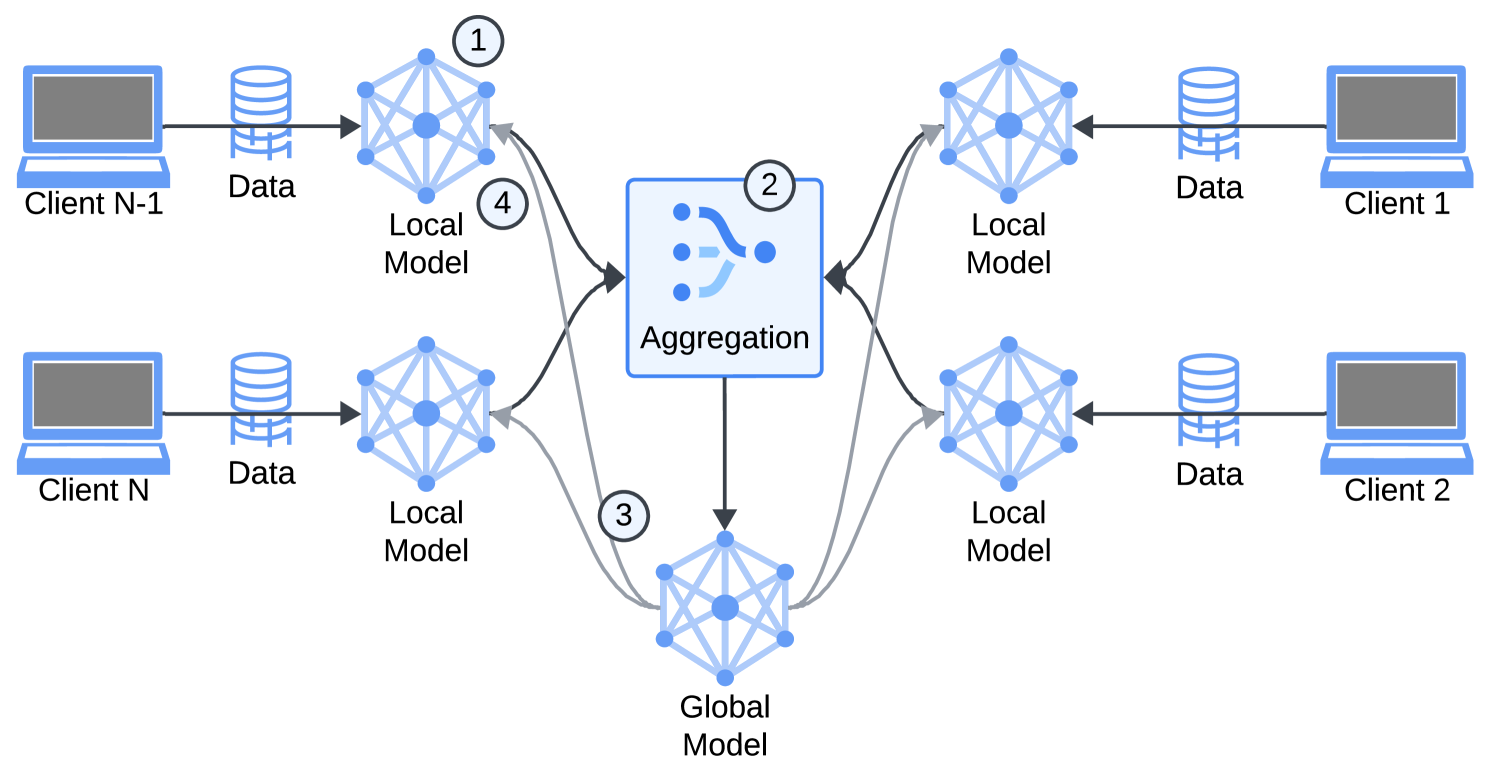
Federated learning is a way for multiple devices, like smartphones or computers, to work together to train a single machine learning model. The key idea is that the devices don't have to share their private, local data with a central server. Instead, they each train the model on their own data and then share the model updates with the server. This helps protect the privacy of the data.
However, a problem can arise when some devices have incomplete or missing data. This can happen for various reasons, like sensors failing or users not providing full information. The FLIGAN framework addresses this challenge. It uses a special type of machine learning model called a Generative Adversarial Network (GAN) to "fill in the gaps" in the incomplete data. The GAN learns to generate synthetic data that resembles the real, incomplete data from the devices.
By incorporating this GAN-generated data, FLIGAN is able to improve the federated learning process even when some devices have incomplete information. This makes federated learning more robust and effective, especially in real-world scenarios where data incompleteness is common.
Technical Explanation
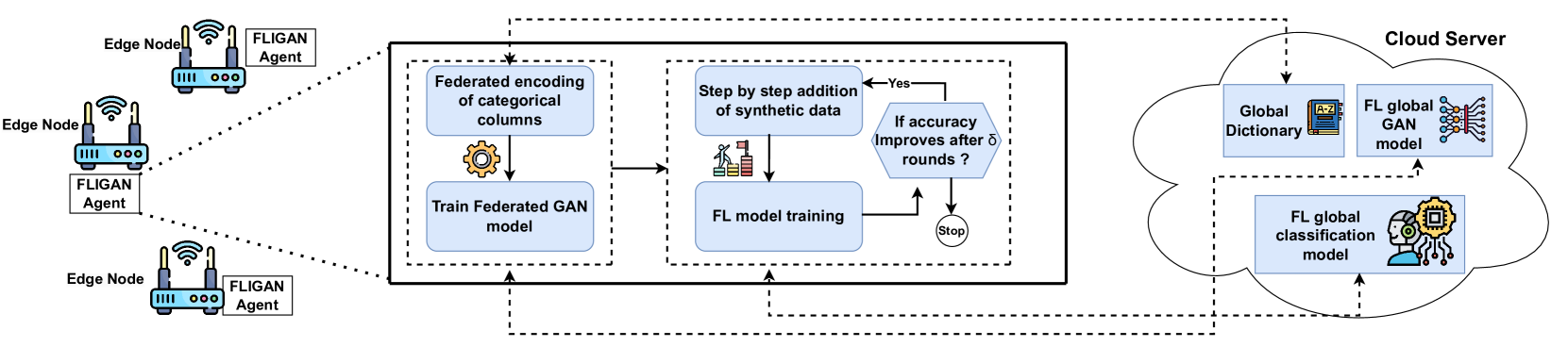
The FLIGAN framework consists of two main components: a federated learning module and a GAN-based data generation module. The federated learning module follows a standard federated learning approach, where devices collaboratively train a shared model by exchanging model updates without sharing their local data.
The GAN-based data generation module operates in parallel to the federated learning module. It trains a GAN using the incomplete data from the participating devices. The generator component of the GAN learns to produce synthetic data that mimics the statistical properties of the real, incomplete data. This generated data is then used to supplement the incomplete data during the federated learning process.
The key insight is that by combining the federated learning and GAN-based data generation, FLIGAN is able to leverage the strengths of both approaches. The federated learning component allows for collaborative model training while preserving data privacy, and the GAN-based module compensates for the incompleteness of the data.
The authors evaluate FLIGAN on several benchmark datasets and demonstrate its effectiveness in improving model performance compared to standard federated learning with incomplete data.
Critical Analysis
The FLIGAN framework represents a promising approach for enhancing federated learning in the presence of incomplete data. The authors have carefully designed the system and provided thorough experimental evaluations to validate its effectiveness.
One potential limitation is that the performance of FLIGAN may be sensitive to the quality and characteristics of the incomplete data. If the missing data patterns are too complex or biased, the GAN module may struggle to generate realistic synthetic data, which could impact the overall federated learning process.
Additionally, the computational and communication overhead of running the GAN-based data generation module in parallel to the federated learning process could be a consideration, especially for resource-constrained edge devices. The authors briefly discuss these trade-offs, but further analysis on the scalability and efficiency of FLIGAN would be valuable.
Lastly, the paper does not explore the broader implications of using synthetic data generated by GANs in federated learning. While the authors demonstrate the benefits in terms of model performance, there may be concerns around the ethical use of such generated data, particularly in sensitive domains like healthcare or finance.
Conclusion
The FLIGAN framework represents a novel and effective approach for addressing the challenge of data incompleteness in federated learning. By seamlessly integrating federated learning and GAN-based data generation, FLIGAN is able to improve model performance even when participating devices have partial or missing data.
This work highlights the potential of combining different machine learning techniques to enhance the robustness and applicability of federated learning, particularly in real-world scenarios where data incompleteness is a common issue. As federated learning continues to gain traction in various applications, the insights and techniques presented in this paper will be valuable for researchers and practitioners working to advance the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Systematic Review of Federated Generative Models
Ashkan Vedadi Gargary, Emiliano De Cristofaro
0
0
Federated Learning (FL) has emerged as a solution for distributed systems that allow clients to train models on their data and only share models instead of local data. Generative Models are designed to learn the distribution of a dataset and generate new data samples that are similar to the original data. Many prior works have tried proposing Federated Generative Models. Using Federated Learning and Generative Models together can be susceptible to attacks, and designing the optimal architecture remains challenging. This survey covers the growing interest in the intersection of FL and Generative Models by comprehensively reviewing research conducted from 2019 to 2024. We systematically compare nearly 100 papers, focusing on their FL and Generative Model methods and privacy considerations. To make this field more accessible to newcomers, we highlight the state-of-the-art advancements and identify unresolved challenges, offering insights for future research in this evolving field.
5/28/2024
Federated Learning with Incomplete Sensing Modalities
Adiba Orzikulova, Jaehyun Kwak, Jaemin Shin, Sung-Ju Lee
0
0
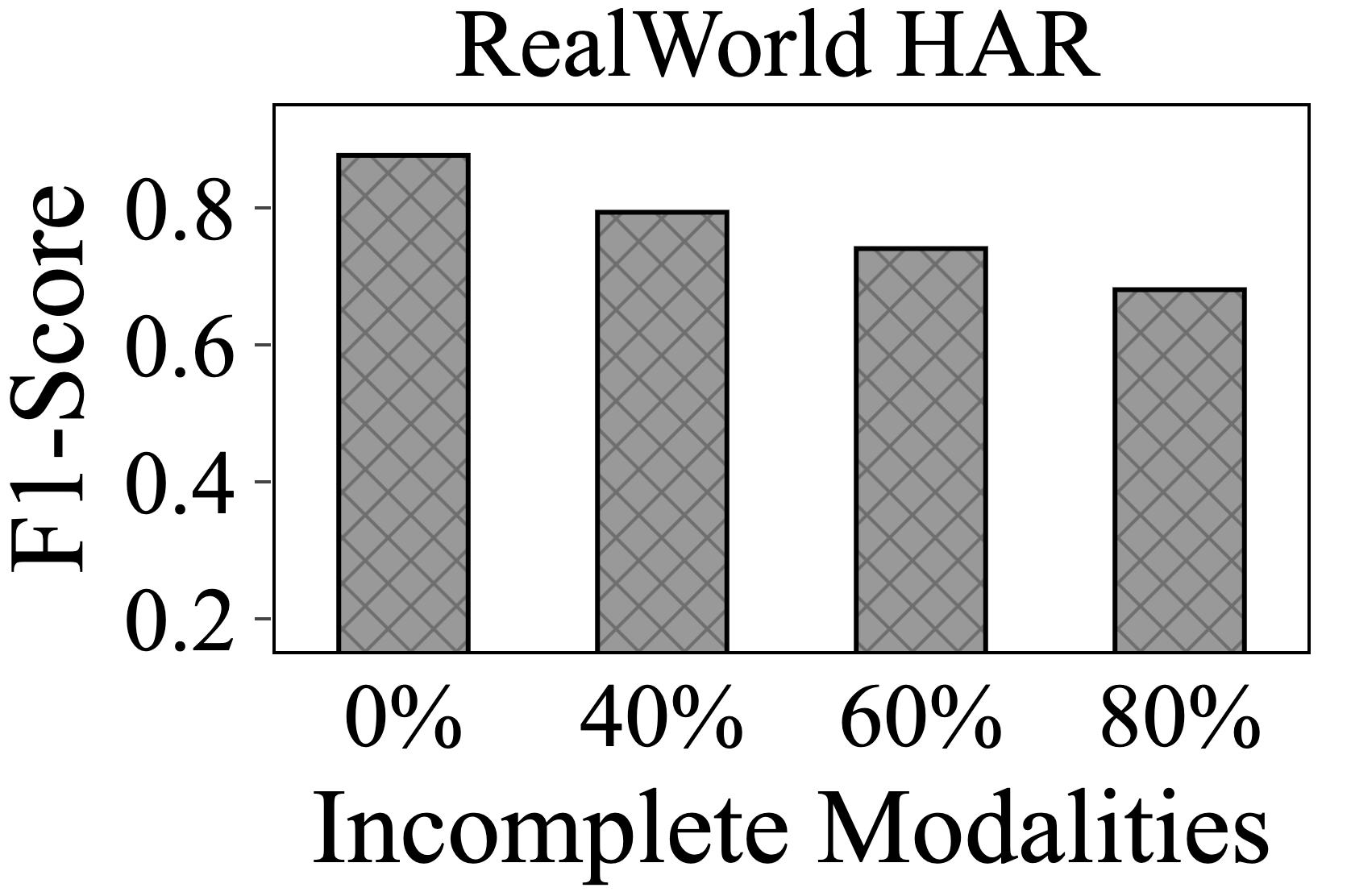
Many mobile sensing applications utilize data from various modalities, including motion and physiological sensors in mobile and wearable devices. Federated Learning (FL) is particularly suitable for these applications thanks to its privacy-preserving feature. However, challenges such as limited battery life, poor network conditions, and sensor malfunctions can restrict the use of all available modalities for local model training. Additionally, existing multimodal FL systems also struggle with scalability and efficiency as the number of modality sources increases. To address these issues, we introduce FLISM, a framework designed to enable multimodal FL with incomplete modalities. FLISM leverages simulation technique to learn robust representations that can handle missing modalities and transfers model knowledge across clients with varying set of modalities. The evaluation results using three real-world datasets and simulations demonstrate FLISM's effective balance between model performance and system efficiency. It shows an average improvement of .067 in F1-score, while also reducing communication (2.69x faster) and computational (2.28x more efficient) overheads compared to existing methods addressing incomplete modalities. Moreover, in simulated scenarios involving tasks with a larger number of modalities, FLISM achieves a significant speedup of 3.23x~85.10x in communication and 3.73x~32.29x in computational efficiency.
5/21/2024
🏅
Data-Free Federated Class Incremental Learning with Diffusion-Based Generative Memory
Naibo Wang, Yuchen Deng, Wenjie Feng, Jianwei Yin, See-Kiong Ng
0
0
Federated Class Incremental Learning (FCIL) is a critical yet largely underexplored issue that deals with the dynamic incorporation of new classes within federated learning (FL). Existing methods often employ generative adversarial networks (GANs) to produce synthetic images to address privacy concerns in FL. However, GANs exhibit inherent instability and high sensitivity, compromising the effectiveness of these methods. In this paper, we introduce a novel data-free federated class incremental learning framework with diffusion-based generative memory (DFedDGM) to mitigate catastrophic forgetting by generating stable, high-quality images through diffusion models. We design a new balanced sampler to help train the diffusion models to alleviate the common non-IID problem in FL, and introduce an entropy-based sample filtering technique from an information theory perspective to enhance the quality of generative samples. Finally, we integrate knowledge distillation with a feature-based regularization term for better knowledge transfer. Our framework does not incur additional communication costs compared to the baseline FedAvg method. Extensive experiments across multiple datasets demonstrate that our method significantly outperforms existing baselines, e.g., over a 4% improvement in average accuracy on the Tiny-ImageNet dataset.
5/29/2024

VFLGAN: Vertical Federated Learning-based Generative Adversarial Network for Vertically Partitioned Data Publication
Xun Yuan, Yang Yang, Prosanta Gope, Aryan Pasikhani, Biplab Sikdar
0
0
In the current artificial intelligence (AI) era, the scale and quality of the dataset play a crucial role in training a high-quality AI model. However, good data is not a free lunch and is always hard to access due to privacy regulations like the General Data Protection Regulation (GDPR). A potential solution is to release a synthetic dataset with a similar distribution to that of the private dataset. Nevertheless, in some scenarios, it has been found that the attributes needed to train an AI model belong to different parties, and they cannot share the raw data for synthetic data publication due to privacy regulations. In PETS 2023, Xue et al. proposed the first generative adversary network-based model, VertiGAN, for vertically partitioned data publication. However, after thoroughly investigating, we found that VertiGAN is less effective in preserving the correlation among the attributes of different parties. This article proposes a Vertical Federated Learning-based Generative Adversarial Network, VFLGAN, for vertically partitioned data publication to address the above issues. Our experimental results show that compared with VertiGAN, VFLGAN significantly improves the quality of synthetic data. Taking the MNIST dataset as an example, the quality of the synthetic dataset generated by VFLGAN is 3.2 times better than that generated by VertiGAN w.r.t. the Fr'echet Distance. We also designed a more efficient and effective Gaussian mechanism for the proposed VFLGAN to provide the synthetic dataset with a differential privacy guarantee. On the other hand, differential privacy only gives the upper bound of the worst-case privacy guarantee. This article also proposes a practical auditing scheme that applies membership inference attacks to estimate privacy leakage through the synthetic dataset.
4/16/2024