Galaxy: A Resource-Efficient Collaborative Edge AI System for In-situ Transformer Inference
2405.17245
0
0
Abstract
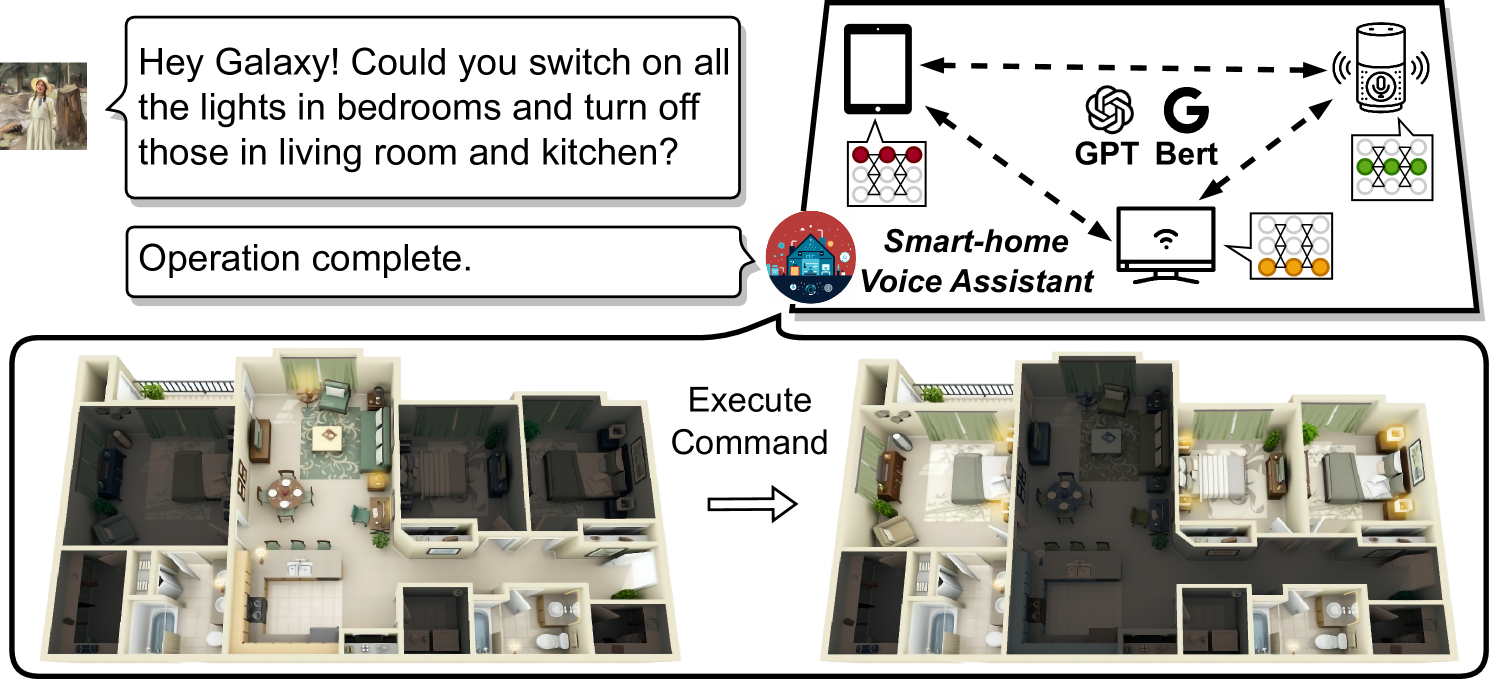
Transformer-based models have unlocked a plethora of powerful intelligent applications at the edge, such as voice assistant in smart home. Traditional deployment approaches offload the inference workloads to the remote cloud server, which would induce substantial pressure on the backbone network as well as raise users' privacy concerns. To address that, in-situ inference has been recently recognized for edge intelligence, but it still confronts significant challenges stemming from the conflict between intensive workloads and limited on-device computing resources. In this paper, we leverage our observation that many edge environments usually comprise a rich set of accompanying trusted edge devices with idle resources and propose Galaxy, a collaborative edge AI system that breaks the resource walls across heterogeneous edge devices for efficient Transformer inference acceleration. Galaxy introduces a novel hybrid model parallelism to orchestrate collaborative inference, along with a heterogeneity-aware parallelism planning for fully exploiting the resource potential. Furthermore, Galaxy devises a tile-based fine-grained overlapping of communication and computation to mitigate the impact of tensor synchronizations on inference latency under bandwidth-constrained edge environments. Extensive evaluation based on prototype implementation demonstrates that Galaxy remarkably outperforms state-of-the-art approaches under various edge environment setups, achieving up to 2.5x end-to-end latency reduction.
Create account to get full access
Overview
- This paper presents "Galaxy," a resource-efficient collaborative edge AI system for in-situ transformer inference.
- Galaxy leverages a novel collaborative edge AI approach to enable efficient on-device inference of large language models.
- The system aims to address the challenges of deploying large AI models on resource-constrained edge devices.
Plain English Explanation
Galaxy is a new way to run powerful AI language models on small devices like smartphones and sensors. Normally, these large AI models are too heavy for devices with limited computing power and memory. Galaxy solves this by splitting up the model and running different parts of it on multiple devices at the same time. This collaborative approach allows the devices to work together to run the full model efficiently, without any single device having to do all the heavy lifting.
The key innovation in Galaxy is how it divides the AI model and coordinates the devices to work together. This "collaborative edge AI" approach means the devices can make use of their combined resources to run large AI models that would be impossible for any one device alone. This could enable powerful AI capabilities, like natural language processing or computer vision, to be deployed widely on edge devices like phones, security cameras, or industrial sensors.
Technical Explanation
Galaxy uses a novel "EdgeShard" architecture to partition a large AI language model across multiple edge devices. Each device runs a specialized sub-component of the full model, and they collaborate to perform the overall inference task. This collaborative approach allows the system to leverage the combined compute and memory resources of the edge devices, while minimizing the burden on any individual node.
The system employs various techniques to optimize performance and resource efficiency, such as model pruning, quantization, and dynamic load balancing. It also includes a "multi-agent RL-based" coordination mechanism to orchestrate the collaborative inference process.
Experiments show that Galaxy can achieve comparable accuracy to a centralized cloud-based deployment, while reducing the compute, memory, and energy requirements by up to 80% compared to standalone edge inference. This makes it well-suited for "integrated sensing-communication-computation" edge AI use cases with tight resource constraints.
Critical Analysis
The paper provides a compelling technical approach for enabling efficient on-device inference of large AI models. However, the evaluation is limited to a single language model and dataset, so further research is needed to assess the generalizability of the Galaxy system across a wider range of AI applications and edge device configurations.
Additionally, the coordination and synchronization overhead introduced by the collaborative approach may become a bottleneck in real-world deployments with unreliable or high-latency network conditions. The authors acknowledge this as a potential limitation that requires further investigation.
Another area for future work is exploring the security and privacy implications of distributing sensitive AI model components across untrusted edge devices. Careful consideration of data protection and model IP concerns will be crucial for deploying Galaxy in mission-critical applications.
Conclusion
Overall, the Galaxy system represents an innovative step towards enabling the use of large AI models on resource-constrained edge devices. The collaborative edge AI approach shows promise for addressing the challenges of deploying powerful AI capabilities at the edge, with potential applications in domains like smart cities, industrial automation, and Internet of Things (IoT) sensing. As the research in this area continues to evolve, it will be important to further investigate the practical implications and ensure the solutions developed are secure, scalable, and aligned with the needs of end-users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Implementation of Big AI Models for Wireless Networks with Collaborative Edge Computing
Liekang Zeng, Shengyuan Ye, Xu Chen, Yang Yang
0
0
Big Artificial Intelligence (AI) models have emerged as a crucial element in various intelligent applications at the edge, such as voice assistants in smart homes and autonomous robotics in smart factories. Training big AI models, e.g., for personalized fine-tuning and continual model refinement, poses significant challenges to edge devices due to the inherent conflict between limited computing resources and intensive workload associated with training. Despite the constraints of on-device training, traditional approaches usually resort to aggregating training data and sending it to a remote cloud for centralized training. Nevertheless, this approach is neither sustainable, which strains long-range backhaul transmission and energy-consuming datacenters, nor safely private, which shares users' raw data with remote infrastructures. To address these challenges, we alternatively observe that prevalent edge environments usually contain a diverse collection of trusted edge devices with untapped idle resources, which can be leveraged for edge training acceleration. Motivated by this, in this article, we propose collaborative edge training, a novel training mechanism that orchestrates a group of trusted edge devices as a resource pool for expedited, sustainable big AI model training at the edge. As an initial step, we present a comprehensive framework for building collaborative edge training systems and analyze in-depth its merits and sustainable scheduling choices following its workflow. To further investigate the impact of its parallelism design, we empirically study a case of four typical parallelisms from the perspective of energy demand with realistic testbeds. Finally, we discuss open challenges for sustainable collaborative edge training to point to future directions of edge-centric big AI model training.
4/30/2024
Collaborative Edge AI Inference over Cloud-RAN
Pengfei Zhang, Dingzhu Wen, Guangxu Zhu, Qimei Chen, Kaifeng Han, Yuanming Shi
0
0
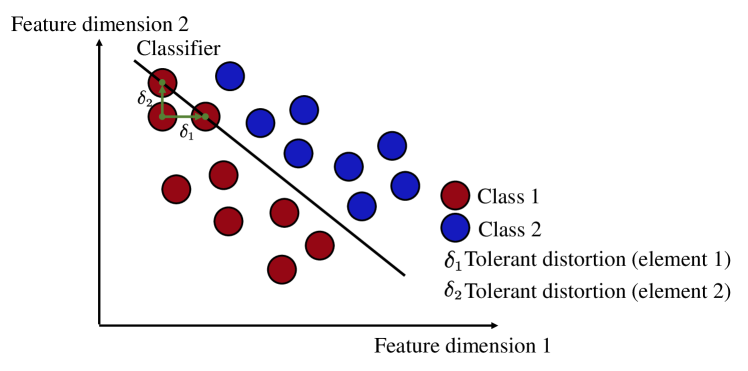
In this paper, a cloud radio access network (Cloud-RAN) based collaborative edge AI inference architecture is proposed. Specifically, geographically distributed devices capture real-time noise-corrupted sensory data samples and extract the noisy local feature vectors, which are then aggregated at each remote radio head (RRH) to suppress sensing noise. To realize efficient uplink feature aggregation, we allow each RRH receives local feature vectors from all devices over the same resource blocks simultaneously by leveraging an over-the-air computation (AirComp) technique. Thereafter, these aggregated feature vectors are quantized and transmitted to a central processor (CP) for further aggregation and downstream inference tasks. Our aim in this work is to maximize the inference accuracy via a surrogate accuracy metric called discriminant gain, which measures the discernibility of different classes in the feature space. The key challenges lie on simultaneously suppressing the coupled sensing noise, AirComp distortion caused by hostile wireless channels, and the quantization error resulting from the limited capacity of fronthaul links. To address these challenges, this work proposes a joint transmit precoding, receive beamforming, and quantization error control scheme to enhance the inference accuracy. Extensive numerical experiments demonstrate the effectiveness and superiority of our proposed optimization algorithm compared to various baselines.
4/10/2024
❗
The Future of Consumer Edge-AI Computing
Stefanos Laskaridis, Stylianos I. Venieris, Alexandros Kouris, Rui Li, Nicholas D. Lane
0
0
In the last decade, Deep Learning has rapidly infiltrated the consumer end, mainly thanks to hardware acceleration across devices. However, as we look towards the future, it is evident that isolated hardware will be insufficient. Increasingly complex AI tasks demand shared resources, cross-device collaboration, and multiple data types, all without compromising user privacy or quality of experience. To address this, we introduce a novel paradigm centered around EdgeAI-Hub devices, designed to reorganise and optimise compute resources and data access at the consumer edge. To this end, we lay a holistic foundation for the transition from on-device to Edge-AI serving systems in consumer environments, detailing their components, structure, challenges and opportunities.
6/19/2024

Hybrid-Parallel: Achieving High Performance and Energy Efficient Distributed Inference on Robots
Zekai Sun, Xiuxian Guan, Junming Wang, Haoze Song, Yuhao Qing, Tianxiang Shen, Dong Huang, Fangming Liu, Heming Cui
0
0
The rapid advancements in machine learning techniques have led to significant achievements in various real-world robotic tasks. These tasks heavily rely on fast and energy-efficient inference of deep neural network (DNN) models when deployed on robots. To enhance inference performance, distributed inference has emerged as a promising approach, parallelizing inference across multiple powerful GPU devices in modern data centers using techniques such as data parallelism, tensor parallelism, and pipeline parallelism. However, when deployed on real-world robots, existing parallel methods fail to provide low inference latency and meet the energy requirements due to the limited bandwidth of robotic IoT. We present Hybrid-Parallel, a high-performance distributed inference system optimized for robotic IoT. Hybrid-Parallel employs a fine-grained approach to parallelize inference at the granularity of local operators within DNN layers (i.e., operators that can be computed independently with the partial input, such as the convolution kernel in the convolution layer). By doing so, Hybrid-Parallel enables different operators of different layers to be computed and transmitted concurrently, and overlap the computation and transmission phases within the same inference task. The evaluation demonstrate that Hybrid-Parallel reduces inference time by 14.9% ~41.1% and energy consumption per inference by up to 35.3% compared to the state-of-the-art baselines.
5/30/2024