A Generative Framework for Self-Supervised Facial Representation Learning
2309.08273
0
0
👀
Abstract
Self-supervised representation learning has gained increasing attention for strong generalization ability without relying on paired datasets. However, it has not been explored sufficiently for facial representation. Self-supervised facial representation learning remains unsolved due to the coupling of facial identities, expressions, and external factors like pose and light. Prior methods primarily focus on contrastive learning and pixel-level consistency, leading to limited interpretability and suboptimal performance. In this paper, we propose LatentFace, a novel generative framework for self-supervised facial representations. We suggest that the disentangling problem can be also formulated as generative objectives in space and time, and propose the solution using a 3D-aware latent diffusion model. First, we introduce a 3D-aware autoencoder to encode face images into 3D latent embeddings. Second, we propose a novel representation diffusion model to disentangle 3D latent into facial identity and expression. Consequently, our method achieves state-of-the-art performance in facial expression recognition (FER) and face verification among self-supervised facial representation learning models. Our model achieves a 3.75% advantage in FER accuracy on RAF-DB and 3.35% on AffectNet compared to SOTA methods.
Create account to get full access
Overview
- Self-supervised representation learning has shown promise for strong generalization without relying on paired datasets, but it has not been sufficiently explored for facial representation.
- Facial representation learning is challenging due to the coupling of facial identities, expressions, and external factors like pose and lighting.
- Prior methods have focused on contrastive learning and pixel-level consistency, leading to limited interpretability and suboptimal performance.
Plain English Explanation
The paper introduces a novel approach called LatentFace, which uses a generative framework for self-supervised facial representation learning. The key idea is to formulate the disentangling problem as generative objectives in space and time, and solve it using a 3D-aware latent diffusion model.
First, the method encodes face images into 3D latent embeddings using a 3D-aware autoencoder. This allows the model to capture the 3D structure of the face, which is important for disentangling different facial attributes like identity and expression.
Second, the paper proposes a representation diffusion model to further disentangle the 3D latent space into separate representations for facial identity and expression. This is done in a self-supervised way, without relying on labeled datasets.
The resulting facial representations achieve state-of-the-art performance on tasks like facial expression recognition and face verification, outperforming other self-supervised methods. This suggests that the proposed generative approach is an effective way to learn interpretable and disentangled facial representations.
Technical Explanation
The paper introduces LatentFace, a novel generative framework for self-supervised facial representation learning. The key components are:
-
3D-aware Autoencoder: The method first encodes face images into a 3D latent embedding using a 3D-aware autoencoder, similar to WildFusion and NeRF-MAE. This allows the model to capture the 3D structure of the face, which is important for disentangling different facial attributes.
-
Representation Diffusion Model: The paper then proposes a novel representation diffusion model to further disentangle the 3D latent space into separate representations for facial identity and expression. This is inspired by recent work on 3D face modeling via disentanglement and synthetic face datasets generation.
-
Self-supervised Training: The entire framework is trained in a self-supervised manner, without relying on any labeled facial datasets. This allows the model to learn interpretable and disentangled facial representations that generalize well to downstream tasks.
The proposed LatentFace model achieves state-of-the-art performance on facial expression recognition (FER) and face verification tasks, outperforming other self-supervised facial representation learning methods. For example, it achieves a 3.75% advantage in FER accuracy on the RAF-DB dataset and a 3.35% advantage on the AffectNet dataset compared to the previous best self-supervised methods.
Critical Analysis
The paper presents a compelling approach to self-supervised facial representation learning, but there are a few potential caveats and areas for further research:
-
Generalization to Diverse Datasets: While the model performs well on the tested datasets, it would be important to evaluate its performance on more diverse and challenging facial datasets, such as those with greater variation in ethnicity, age, and other demographic factors.
-
Interpretability of Learned Representations: The paper claims the proposed method leads to more interpretable facial representations, but it would be valuable to further analyze and visualize the learned representations to better understand what information they capture.
-
Computational Complexity: The use of a 3D-aware autoencoder and a diffusion-based representation model may come with increased computational cost, which could limit the practical deployment of the method. Further analysis of the model's efficiency would be helpful.
-
Ethical Considerations: As with any facial analysis technology, there are potential ethical concerns around bias, privacy, and the misuse of the learned representations. The paper would benefit from a more in-depth discussion of these issues.
Overall, the LatentFace approach represents an interesting and promising direction for self-supervised facial representation learning, but further research and analysis would be valuable to address these potential limitations.
Conclusion
The paper presents LatentFace, a novel generative framework for self-supervised facial representation learning. By formulating the disentangling problem as generative objectives in space and time and solving it with a 3D-aware latent diffusion model, the method achieves state-of-the-art performance on facial expression recognition and face verification tasks.
This work demonstrates the power of generative models and 3D-aware representations for learning interpretable and disentangled facial features in a self-supervised manner. The resulting representations can have significant impact on a wide range of facial analysis and understanding applications, paving the way for more robust and equitable facial computing systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Enhancing Generalizability of Representation Learning for Data-Efficient 3D Scene Understanding
Yunsong Wang, Na Zhao, Gim Hee Lee
0
0
The field of self-supervised 3D representation learning has emerged as a promising solution to alleviate the challenge presented by the scarcity of extensive, well-annotated datasets. However, it continues to be hindered by the lack of diverse, large-scale, real-world 3D scene datasets for source data. To address this shortfall, we propose Generalizable Representation Learning (GRL), where we devise a generative Bayesian network to produce diverse synthetic scenes with real-world patterns, and conduct pre-training with a joint objective. By jointly learning a coarse-to-fine contrastive learning task and an occlusion-aware reconstruction task, the model is primed with transferable, geometry-informed representations. Post pre-training on synthetic data, the acquired knowledge of the model can be seamlessly transferred to two principal downstream tasks associated with 3D scene understanding, namely 3D object detection and 3D semantic segmentation, using real-world benchmark datasets. A thorough series of experiments robustly display our method's consistent superiority over existing state-of-the-art pre-training approaches.
6/18/2024
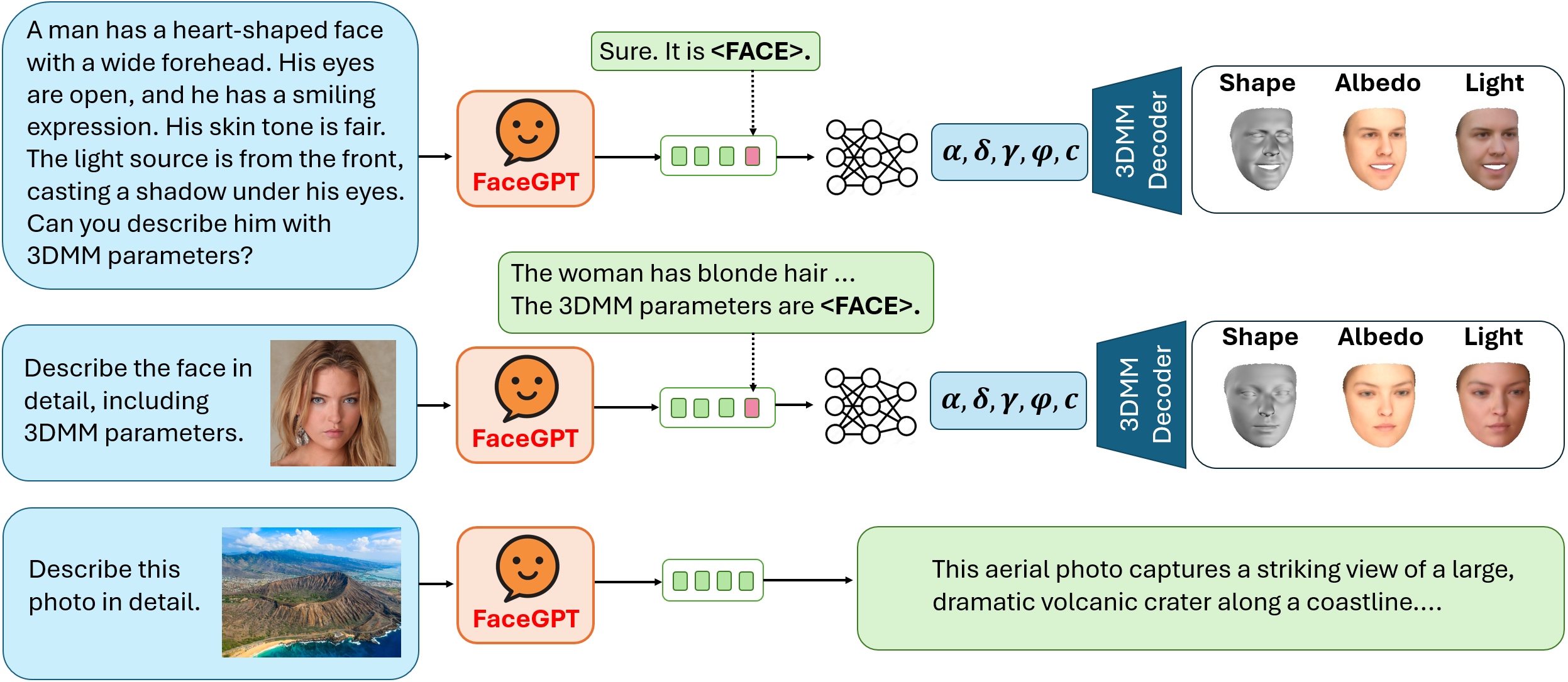
FaceGPT: Self-supervised Learning to Chat about 3D Human Faces
Haoran Wang, Mohit Mendiratta, Christian Theobalt, Adam Kortylewski
0
0
We introduce FaceGPT, a self-supervised learning framework for Large Vision-Language Models (VLMs) to reason about 3D human faces from images and text. Typical 3D face reconstruction methods are specialized algorithms that lack semantic reasoning capabilities. FaceGPT overcomes this limitation by embedding the parameters of a 3D morphable face model (3DMM) into the token space of a VLM, enabling the generation of 3D faces from both textual and visual inputs. FaceGPT is trained in a self-supervised manner as a model-based autoencoder from in-the-wild images. In particular, the hidden state of LLM is projected into 3DMM parameters and subsequently rendered as 2D face image to guide the self-supervised learning process via image-based reconstruction. Without relying on expensive 3D annotations of human faces, FaceGPT obtains a detailed understanding about 3D human faces, while preserving the capacity to understand general user instructions. Our experiments demonstrate that FaceGPT not only achieves high-quality 3D face reconstructions but also retains the ability for general-purpose visual instruction following. Furthermore, FaceGPT learns fully self-supervised to generate 3D faces based on complex textual inputs, which opens a new direction in human face analysis.
6/12/2024
💬
WildFusion: Learning 3D-Aware Latent Diffusion Models in View Space
Katja Schwarz, Seung Wook Kim, Jun Gao, Sanja Fidler, Andreas Geiger, Karsten Kreis
0
0
Modern learning-based approaches to 3D-aware image synthesis achieve high photorealism and 3D-consistent viewpoint changes for the generated images. Existing approaches represent instances in a shared canonical space. However, for in-the-wild datasets a shared canonical system can be difficult to define or might not even exist. In this work, we instead model instances in view space, alleviating the need for posed images and learned camera distributions. We find that in this setting, existing GAN-based methods are prone to generating flat geometry and struggle with distribution coverage. We hence propose WildFusion, a new approach to 3D-aware image synthesis based on latent diffusion models (LDMs). We first train an autoencoder that infers a compressed latent representation, which additionally captures the images' underlying 3D structure and enables not only reconstruction but also novel view synthesis. To learn a faithful 3D representation, we leverage cues from monocular depth prediction. Then, we train a diffusion model in the 3D-aware latent space, thereby enabling synthesis of high-quality 3D-consistent image samples, outperforming recent state-of-the-art GAN-based methods. Importantly, our 3D-aware LDM is trained without any direct supervision from multiview images or 3D geometry and does not require posed images or learned pose or camera distributions. It directly learns a 3D representation without relying on canonical camera coordinates. This opens up promising research avenues for scalable 3D-aware image synthesis and 3D content creation from in-the-wild image data. See https://katjaschwarz.github.io/wildfusion for videos of our 3D results.
4/15/2024

NeRF-MAE: Masked AutoEncoders for Self-Supervised 3D Representation Learning for Neural Radiance Fields
Muhammad Zubair Irshad, Sergey Zakahrov, Vitor Guizilini, Adrien Gaidon, Zsolt Kira, Rares Ambrus
0
0
Neural fields excel in computer vision and robotics due to their ability to understand the 3D visual world such as inferring semantics, geometry, and dynamics. Given the capabilities of neural fields in densely representing a 3D scene from 2D images, we ask the question: Can we scale their self-supervised pretraining, specifically using masked autoencoders, to generate effective 3D representations from posed RGB images. Owing to the astounding success of extending transformers to novel data modalities, we employ standard 3D Vision Transformers to suit the unique formulation of NeRFs. We leverage NeRF's volumetric grid as a dense input to the transformer, contrasting it with other 3D representations such as pointclouds where the information density can be uneven, and the representation is irregular. Due to the difficulty of applying masked autoencoders to an implicit representation, such as NeRF, we opt for extracting an explicit representation that canonicalizes scenes across domains by employing the camera trajectory for sampling. Our goal is made possible by masking random patches from NeRF's radiance and density grid and employing a standard 3D Swin Transformer to reconstruct the masked patches. In doing so, the model can learn the semantic and spatial structure of complete scenes. We pretrain this representation at scale on our proposed curated posed-RGB data, totaling over 1.6 million images. Once pretrained, the encoder is used for effective 3D transfer learning. Our novel self-supervised pretraining for NeRFs, NeRF-MAE, scales remarkably well and improves performance on various challenging 3D tasks. Utilizing unlabeled posed 2D data for pretraining, NeRF-MAE significantly outperforms self-supervised 3D pretraining and NeRF scene understanding baselines on Front3D and ScanNet datasets with an absolute performance improvement of over 20% AP50 and 8% AP25 for 3D object detection.
4/19/2024