Generative Multimodal Models are In-Context Learners
2312.13286
153
0
🖼️
Abstract
The human ability to easily solve multimodal tasks in context (i.e., with only a few demonstrations or simple instructions), is what current multimodal systems have largely struggled to imitate. In this work, we demonstrate that the task-agnostic in-context learning capabilities of large multimodal models can be significantly enhanced by effective scaling-up. We introduce Emu2, a generative multimodal model with 37 billion parameters, trained on large-scale multimodal sequences with a unified autoregressive objective. Emu2 exhibits strong multimodal in-context learning abilities, even emerging to solve tasks that require on-the-fly reasoning, such as visual prompting and object-grounded generation. The model sets a new record on multiple multimodal understanding tasks in few-shot settings. When instruction-tuned to follow specific instructions, Emu2 further achieves new state-of-the-art on challenging tasks such as question answering benchmarks for large multimodal models and open-ended subject-driven generation. These achievements demonstrate that Emu2 can serve as a base model and general-purpose interface for a wide range of multimodal tasks. Code and models are publicly available to facilitate future research.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Current multimodal systems struggle to match the human ability to easily solve multimodal tasks with just a few demonstrations or simple instructions.
- This work introduces Emu2, a 37 billion parameter generative multimodal model that exhibits strong multimodal in-context learning abilities.
- Emu2 sets new state-of-the-art performance on various multimodal understanding tasks in few-shot settings and can perform challenging tasks like question answering and open-ended generation when instruction-tuned.
Plain English Explanation
Humans can easily perform complex tasks that involve different types of information, like images and text, by learning from just a few examples or simple instructions. Current AI systems struggle to match this multimodal ability.
The researchers developed a very large generative multimodal model called Emu2 that can learn to perform a wide variety of multimodal tasks from limited information. Emu2 has 37 billion parameters, meaning it's a very complex model that has been trained on a huge amount of diverse multimodal data.
This allows Emu2 to quickly adapt and solve new tasks by learning in context, even if the task requires on-the-fly reasoning like generating text based on visual prompts. Emu2 outperforms other large multimodal models on various benchmarks, especially when given just a few examples to work with.
The model can also be fine-tuned with specific instructions, allowing it to tackle challenging tasks like answering questions about images and generating open-ended text on requested topics. This makes Emu2 a versatile foundation that can be used for many different multimodal applications.
Technical Explanation
Emu2 is a 37 billion parameter generative multimodal model trained on large-scale multimodal sequences with a unified autoregressive objective. This means the model learns to predict the next element in a sequence of multimodal data (e.g. an image followed by text) through a single, overarching training process.
The researchers show that effectively scaling up the model size and training data significantly enhances its task-agnostic in-context learning capabilities. Emu2 can solve a variety of multimodal tasks, including those requiring on-the-fly reasoning, by quickly adapting based on just a few demonstrations or instructions.
Emu2 sets new state-of-the-art performance on multiple multimodal understanding benchmarks in few-shot settings. When further instruction-tuned, the model achieves new advances on challenging tasks like visual question answering and open-ended subject-driven generation.
These results demonstrate that large, generatively pre-trained multimodal models like Emu2 can serve as powerful base models and general-purpose interfaces for a wide range of multimodal applications.
Critical Analysis
The paper provides a compelling demonstration of the benefits of scaling up multimodal models, but it also acknowledges several caveats and areas for future work:
-
The researchers note that while Emu2 exhibits strong in-context learning, the model still has limitations in its ability to compositionally generalize to novel combinations of modalities and concepts.
-
The training and inference costs for models of this size are still very high, which could limit their practical deployment. Further research is needed to improve the efficiency and accessibility of such large-scale multimodal systems.
-
The paper does not provide a deep analysis of the latent representations learned by Emu2 or explore potential biases in the model's outputs. Investigating these aspects could lead to important insights and improvements.
Overall, the work represents a significant advancement in multimodal AI, but continued research is necessary to fully unlock the potential of these powerful models and ensure they are developed responsibly.
Conclusion
This research demonstrates that the task-agnostic in-context learning capabilities of large multimodal models can be substantially enhanced through effective scaling. The Emu2 model sets new state-of-the-art performance on various multimodal understanding benchmarks and can tackle challenging tasks like visual question answering and open-ended generation when instruction-tuned.
These achievements suggest that large, generatively pre-trained multimodal models can serve as versatile foundations for a wide range of multimodal applications. However, the paper also highlights the need for further research to address the limitations of current approaches and ensure the responsible development of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Emu: Generative Pretraining in Multimodality
Quan Sun, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, Yueze Wang, Hongcheng Gao, Jingjing Liu, Tiejun Huang, Xinlong Wang
0
0
We present Emu, a Transformer-based multimodal foundation model, which can seamlessly generate images and texts in multimodal context. This omnivore model can take in any single-modality or multimodal data input indiscriminately (e.g., interleaved image, text and video) through a one-model-for-all autoregressive training process. First, visual signals are encoded into embeddings, and together with text tokens form an interleaved input sequence. Emu is then end-to-end trained with a unified objective of classifying the next text token or regressing the next visual embedding in the multimodal sequence. This versatile multimodality empowers the exploration of diverse pretraining data sources at scale, such as videos with interleaved frames and text, webpages with interleaved images and text, as well as web-scale image-text pairs and video-text pairs. Emu can serve as a generalist multimodal interface for both image-to-text and text-to-image tasks, and supports in-context image and text generation. Across a broad range of zero-shot/few-shot tasks including image captioning, visual question answering, video question answering and text-to-image generation, Emu demonstrates superb performance compared to state-of-the-art large multimodal models. Extended capabilities such as multimodal assistants via instruction tuning are also demonstrated with impressive performance.
5/9/2024
Sequential Compositional Generalization in Multimodal Models
Semih Yagcioglu, Osman Batur .Ince, Aykut Erdem, Erkut Erdem, Desmond Elliott, Deniz Yuret
0
0
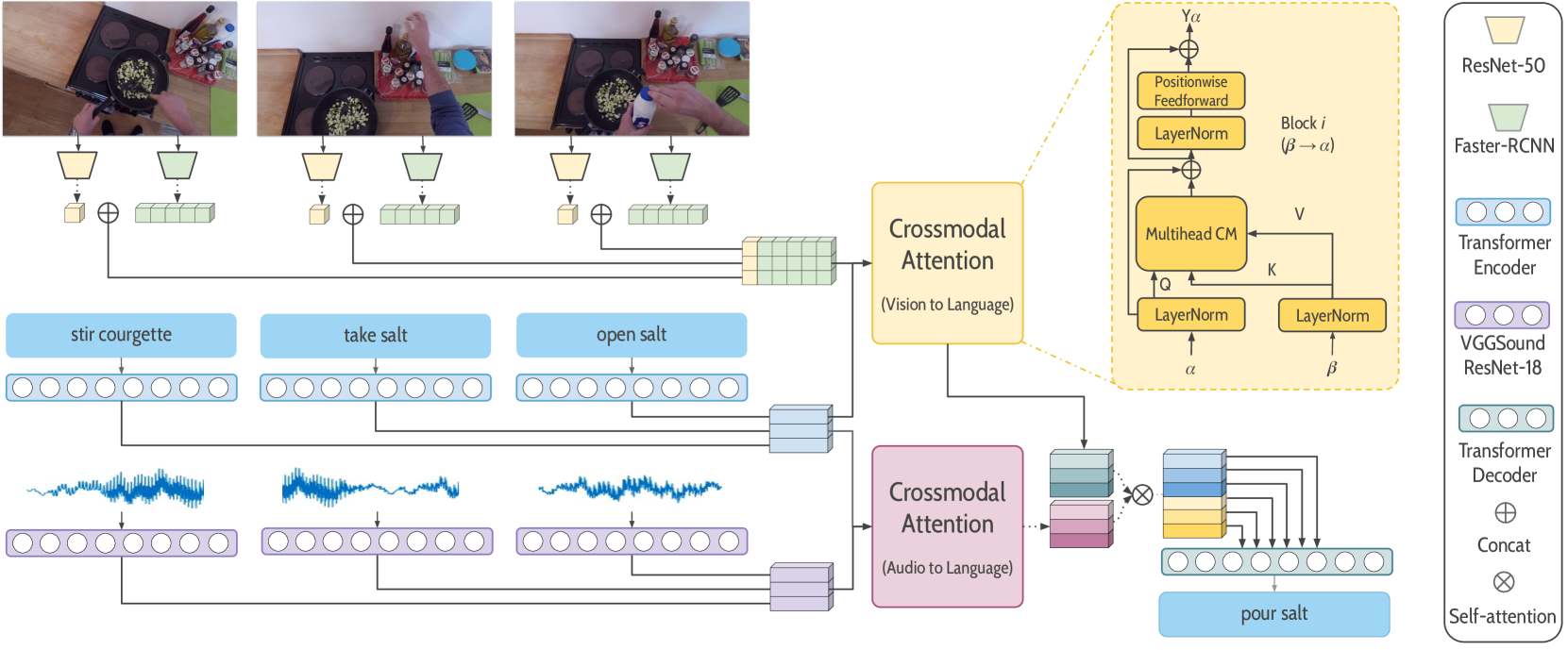
The rise of large-scale multimodal models has paved the pathway for groundbreaking advances in generative modeling and reasoning, unlocking transformative applications in a variety of complex tasks. However, a pressing question that remains is their genuine capability for stronger forms of generalization, which has been largely underexplored in the multimodal setting. Our study aims to address this by examining sequential compositional generalization using textsc{CompAct} (underline{Comp}ositional underline{Act}ivities)footnote{Project Page: url{http://cyberiada.github.io/CompAct}}, a carefully constructed, perceptually grounded dataset set within a rich backdrop of egocentric kitchen activity videos. Each instance in our dataset is represented with a combination of raw video footage, naturally occurring sound, and crowd-sourced step-by-step descriptions. More importantly, our setup ensures that the individual concepts are consistently distributed across training and evaluation sets, while their compositions are novel in the evaluation set. We conduct a comprehensive assessment of several unimodal and multimodal models. Our findings reveal that bi-modal and tri-modal models exhibit a clear edge over their text-only counterparts. This highlights the importance of multimodality while charting a trajectory for future research in this domain.
4/19/2024
💬
Multimodal Dialog Systems with Dual Knowledge-enhanced Generative Pretrained Language Model
Xiaolin Chen, Xuemeng Song, Liqiang Jing, Shuo Li, Linmei Hu, Liqiang Nie
0
0
Text response generation for multimodal task-oriented dialog systems, which aims to generate the proper text response given the multimodal context, is an essential yet challenging task. Although existing efforts have achieved compelling success, they still suffer from two pivotal limitations: 1) overlook the benefit of generative pre-training, and 2) ignore the textual context related knowledge. To address these limitations, we propose a novel dual knowledge-enhanced generative pretrained language model for multimodal task-oriented dialog systems (DKMD), consisting of three key components: dual knowledge selection, dual knowledge-enhanced context learning, and knowledge-enhanced response generation. To be specific, the dual knowledge selection component aims to select the related knowledge according to both textual and visual modalities of the given context. Thereafter, the dual knowledge-enhanced context learning component targets seamlessly integrating the selected knowledge into the multimodal context learning from both global and local perspectives, where the cross-modal semantic relation is also explored. Moreover, the knowledge-enhanced response generation component comprises a revised BART decoder, where an additional dot-product knowledge-decoder attention sub-layer is introduced for explicitly utilizing the knowledge to advance the text response generation. Extensive experiments on a public dataset verify the superiority of the proposed DKMD over state-of-the-art competitors.
5/14/2024
What Makes Multimodal In-Context Learning Work?
Folco Bertini Baldassini, Mustafa Shukor, Matthieu Cord, Laure Soulier, Benjamin Piwowarski
0
0
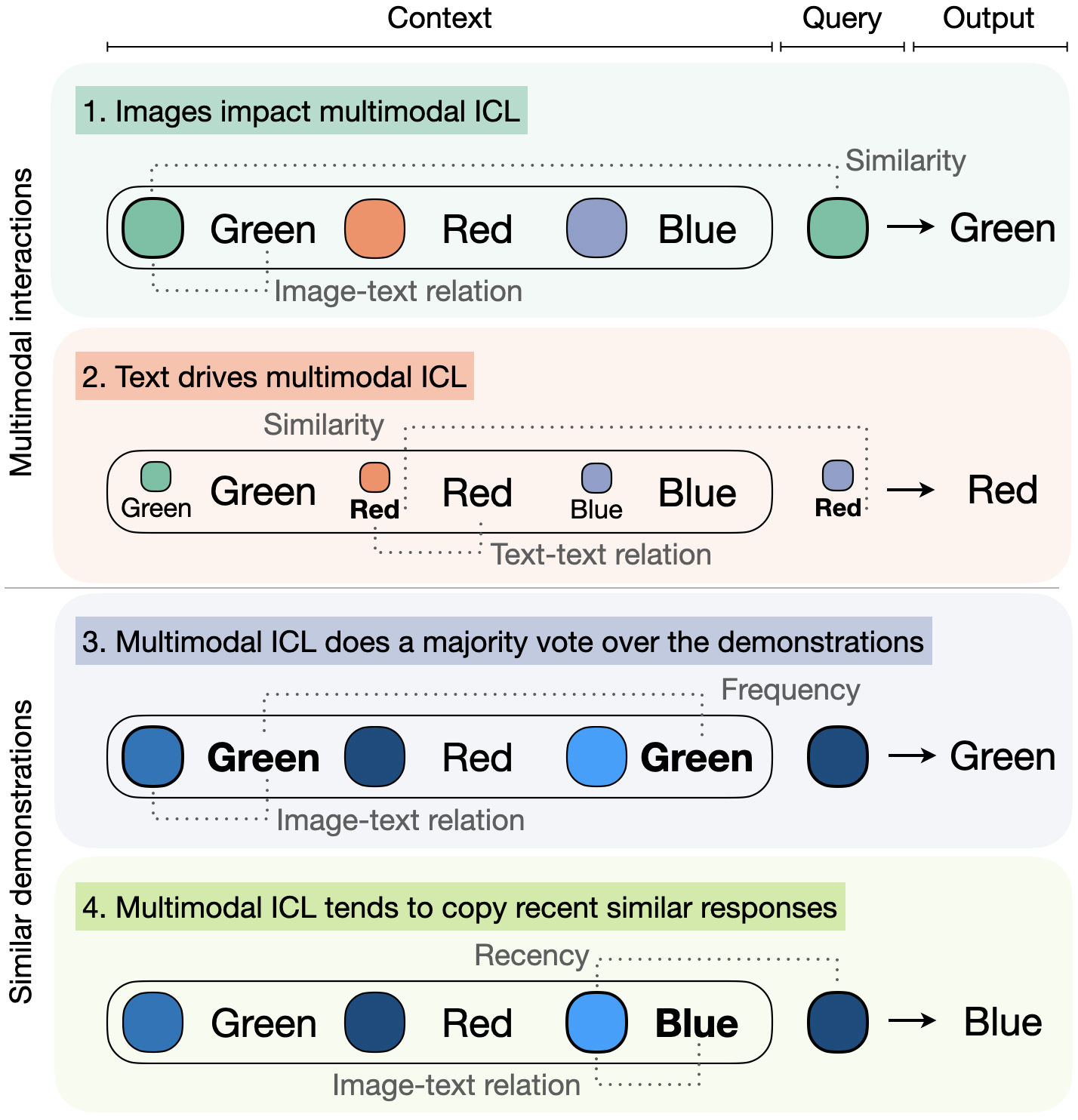
Large Language Models have demonstrated remarkable performance across various tasks, exhibiting the capacity to swiftly acquire new skills, such as through In-Context Learning (ICL) with minimal demonstration examples. In this work, we present a comprehensive framework for investigating Multimodal ICL (M-ICL) in the context of Large Multimodal Models. We consider the best open-source multimodal models (e.g., IDEFICS, OpenFlamingo) and a wide range of multimodal tasks. Our study unveils several noteworthy findings: (1) M-ICL primarily relies on text-driven mechanisms, showing little to no influence from the image modality. (2) When used with advanced-ICL strategy (like RICES), M-ICL is not better than a simple strategy based on majority voting over context examples. Moreover, we identify several biases and limitations of M-ICL that warrant consideration prior to deployment. Code available at https://gitlab.com/folbaeni/multimodal-icl
4/26/2024