Giving a Hand to Diffusion Models: a Two-Stage Approach to Improving Conditional Human Image Generation
2403.10731
0
0

Abstract
Recent years have seen significant progress in human image generation, particularly with the advancements in diffusion models. However, existing diffusion methods encounter challenges when producing consistent hand anatomy and the generated images often lack precise control over the hand pose. To address this limitation, we introduce a novel approach to pose-conditioned human image generation, dividing the process into two stages: hand generation and subsequent body outpainting around the hands. We propose training the hand generator in a multi-task setting to produce both hand images and their corresponding segmentation masks, and employ the trained model in the first stage of generation. An adapted ControlNet model is then used in the second stage to outpaint the body around the generated hands, producing the final result. A novel blending technique is introduced to preserve the hand details during the second stage that combines the results of both stages in a coherent way. This involves sequential expansion of the outpainted region while fusing the latent representations, to ensure a seamless and cohesive synthesis of the final image. Experimental evaluations demonstrate the superiority of our proposed method over state-of-the-art techniques, in both pose accuracy and image quality, as validated on the HaGRID dataset. Our approach not only enhances the quality of the generated hands but also offers improved control over hand pose, advancing the capabilities of pose-conditioned human image generation. The source code of the proposed approach is available at https://github.com/apelykh/hand-to-diffusion.
Create account to get full access
Overview
- This research paper presents a two-stage approach to improving conditional human image generation using diffusion models.
- The key ideas are:
- Employing a hand-specific diffusion model to generate realistic hands as part of the image
- Coupling this with a separate body diffusion model to produce high-quality human images
- The authors demonstrate the effectiveness of their approach through extensive experiments and comparisons to existing methods.
Plain English Explanation
The paper describes a new way to generate realistic-looking images of people using a special kind of AI model called a "diffusion model". Diffusion models work by starting with random noise and gradually refining it into an image.
The researchers found that the standard diffusion model had trouble creating natural-looking hands as part of the full human images. To fix this, they developed a separate diffusion model specifically focused on generating high-quality hands. This "hand-specific" model was then combined with the main body diffusion model to produce complete images of people that look much more realistic, especially in the hand regions.
[Providing an example image with a caption could help illustrate this concept.]
The key innovation is this two-stage approach, with one model handling the body and another handling the hands. This allows the system to pay special attention to the hands, which are a crucial part of making human images look authentic. The authors show through various experiments that this method outperforms existing single-stage diffusion models for generating realistic conditional human images.
Technical Explanation
The paper introduces a two-stage approach to conditional human image generation using diffusion models. The first stage employs a hand-specific diffusion model, called HandDiffer, to generate realistic hand images. This is then combined with a separate body diffusion model in the second stage to produce the final human image.
The motivation behind this approach is that standard diffusion models struggle to generate high-quality hands as part of the full human figure. By decoupling the hand generation into a dedicated model, the authors are able to better capture the fine-grained details and complex structure of hands.
The HandDiffer model is trained on a large dataset of hand images and learns to generate realistic hand poses and appearances. During inference, this hand-specific model is used to produce a hand image, which is then seamlessly merged with the body image generated by the separate diffusion model.
The authors also introduce techniques to ensure smooth integration between the hand and body, such as RHands, which refines any misaligned or malformed hands. Additionally, they leverage a DiffBody model to restore and enhance the generated human body.
Through extensive experiments, the researchers demonstrate that their two-stage approach, called HandDiffuser, outperforms existing single-stage diffusion models in terms of generating more realistic and visually appealing conditional human images.
Critical Analysis
The researchers have provided a thoughtful and well-designed solution to the challenge of generating realistic human images using diffusion models. By decoupling the hand generation into a separate model, they are able to better capture the complex structure and fine details of hands, which are a crucial component of realistic human images.
However, one potential limitation of the approach is the increased computational complexity and training requirements compared to a single-stage diffusion model. The need to train and run multiple models in sequence may make the method less efficient or practical in certain real-world applications.
Additionally, while the authors demonstrate the effectiveness of their approach through various experiments, there may be room for further improvement or exploration of alternative techniques. For example, it would be interesting to see how the two-stage approach compares to other methods, such as using a single, more sophisticated diffusion model or leveraging additional modalities (e.g., 3D hand pose information) to enhance the hand generation.
Overall, the researchers have made a valuable contribution to the field of conditional human image generation, and their work provides a promising direction for further advancements in this area.
Conclusion
This paper presents a novel two-stage approach to improving conditional human image generation using diffusion models. By employing a dedicated hand-specific diffusion model in the first stage, the researchers are able to generate more realistic and visually appealing human images compared to existing single-stage diffusion models.
The key innovation is the decoupling of hand generation from the overall body, which allows the system to better capture the fine-grained details and complex structure of hands. The authors demonstrate the effectiveness of their HandDiffuser approach through extensive experiments and comparisons to state-of-the-art methods.
This work has the potential to significantly advance the field of conditional human image generation, with applications in areas such as computer graphics, virtual reality, and human-computer interaction. The two-stage approach could also inspire further research into modular and task-specific diffusion models for other complex image generation tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

HanDiffuser: Text-to-Image Generation With Realistic Hand Appearances
Supreeth Narasimhaswamy, Uttaran Bhattacharya, Xiang Chen, Ishita Dasgupta, Saayan Mitra, Minh Hoai
0
0
Text-to-image generative models can generate high-quality humans, but realism is lost when generating hands. Common artifacts include irregular hand poses, shapes, incorrect numbers of fingers, and physically implausible finger orientations. To generate images with realistic hands, we propose a novel diffusion-based architecture called HanDiffuser that achieves realism by injecting hand embeddings in the generative process. HanDiffuser consists of two components: a Text-to-Hand-Params diffusion model to generate SMPL-Body and MANO-Hand parameters from input text prompts, and a Text-Guided Hand-Params-to-Image diffusion model to synthesize images by conditioning on the prompts and hand parameters generated by the previous component. We incorporate multiple aspects of hand representation, including 3D shapes and joint-level finger positions, orientations and articulations, for robust learning and reliable performance during inference. We conduct extensive quantitative and qualitative experiments and perform user studies to demonstrate the efficacy of our method in generating images with high-quality hands.
4/23/2024
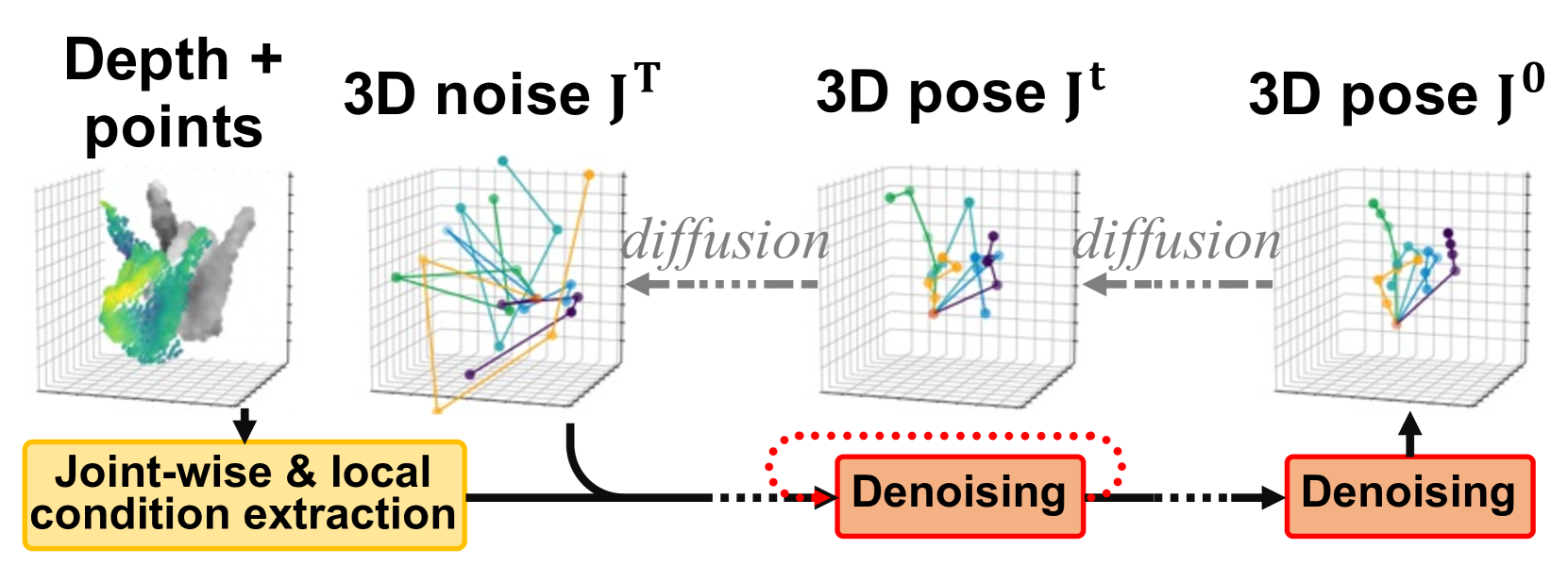
HandDiff: 3D Hand Pose Estimation with Diffusion on Image-Point Cloud
Wencan Cheng, Hao Tang, Luc Van Gool, Jong Hwan Ko
0
0
Extracting keypoint locations from input hand frames, known as 3D hand pose estimation, is a critical task in various human-computer interaction applications. Essentially, the 3D hand pose estimation can be regarded as a 3D point subset generative problem conditioned on input frames. Thanks to the recent significant progress on diffusion-based generative models, hand pose estimation can also benefit from the diffusion model to estimate keypoint locations with high quality. However, directly deploying the existing diffusion models to solve hand pose estimation is non-trivial, since they cannot achieve the complex permutation mapping and precise localization. Based on this motivation, this paper proposes HandDiff, a diffusion-based hand pose estimation model that iteratively denoises accurate hand pose conditioned on hand-shaped image-point clouds. In order to recover keypoint permutation and accurate location, we further introduce joint-wise condition and local detail condition. Experimental results demonstrate that the proposed HandDiff significantly outperforms the existing approaches on four challenging hand pose benchmark datasets. Codes and pre-trained models are publicly available at https://github.com/cwc1260/HandDiff.
4/5/2024

RHanDS: Refining Malformed Hands for Generated Images with Decoupled Structure and Style Guidance
Chengrui Wang, Pengfei Liu, Min Zhou, Ming Zeng, Xubin Li, Tiezheng Ge, Bo zheng
0
0
Although diffusion models can generate high-quality human images, their applications are limited by the instability in generating hands with correct structures. Some previous works mitigate the problem by considering hand structure yet struggle to maintain style consistency between refined malformed hands and other image regions. In this paper, we aim to solve the problem of inconsistency regarding hand structure and style. We propose a conditional diffusion-based framework RHanDS to refine the hand region with the help of decoupled structure and style guidance. Specifically, the structure guidance is the hand mesh reconstructed from the malformed hand, serving to correct the hand structure. The style guidance is a hand image, e.g., the malformed hand itself, and is employed to furnish the style reference for hand refining. In order to suppress the structure leakage when referencing hand style and effectively utilize hand data to improve the capability of the model, we build a multi-style hand dataset and introduce a twostage training strategy. In the first stage, we use paired hand images for training to generate hands with the same style as the reference. In the second stage, various hand images generated based on the human mesh are used for training to enable the model to gain control over the hand structure. We evaluate our method and counterparts on the test dataset of the proposed multi-style hand dataset. The experimental results show that RHanDS can effectively refine hands structure- and style- correctly compared with previous methods. The codes and datasets will be available soon.
4/23/2024

DiffBody: Human Body Restoration by Imagining with Generative Diffusion Prior
Yiming Zhang, Zhe Wang, Xinjie Li, Yunchen Yuan, Chengsong Zhang, Xiao Sun, Zhihang Zhong, Jian Wang
0
0
Human body restoration plays a vital role in various applications related to the human body. Despite recent advances in general image restoration using generative models, their performance in human body restoration remains mediocre, often resulting in foreground and background blending, over-smoothing surface textures, missing accessories, and distorted limbs. Addressing these challenges, we propose a novel approach by constructing a human body-aware diffusion model that leverages domain-specific knowledge to enhance performance. Specifically, we employ a pretrained body attention module to guide the diffusion model's focus on the foreground, addressing issues caused by blending between the subject and background. We also demonstrate the value of revisiting the language modality of the diffusion model in restoration tasks by seamlessly incorporating text prompt to improve the quality of surface texture and additional clothing and accessories details. Additionally, we introduce a diffusion sampler tailored for fine-grained human body parts, utilizing local semantic information to rectify limb distortions. Lastly, we collect a comprehensive dataset for benchmarking and advancing the field of human body restoration. Extensive experimental validation showcases the superiority of our approach, both quantitatively and qualitatively, over existing methods.
4/5/2024