Gradient-based Automatic Per-Weight Mixed Precision Quantization for Neural Networks On-Chip

0
Sign in to get full access
Overview
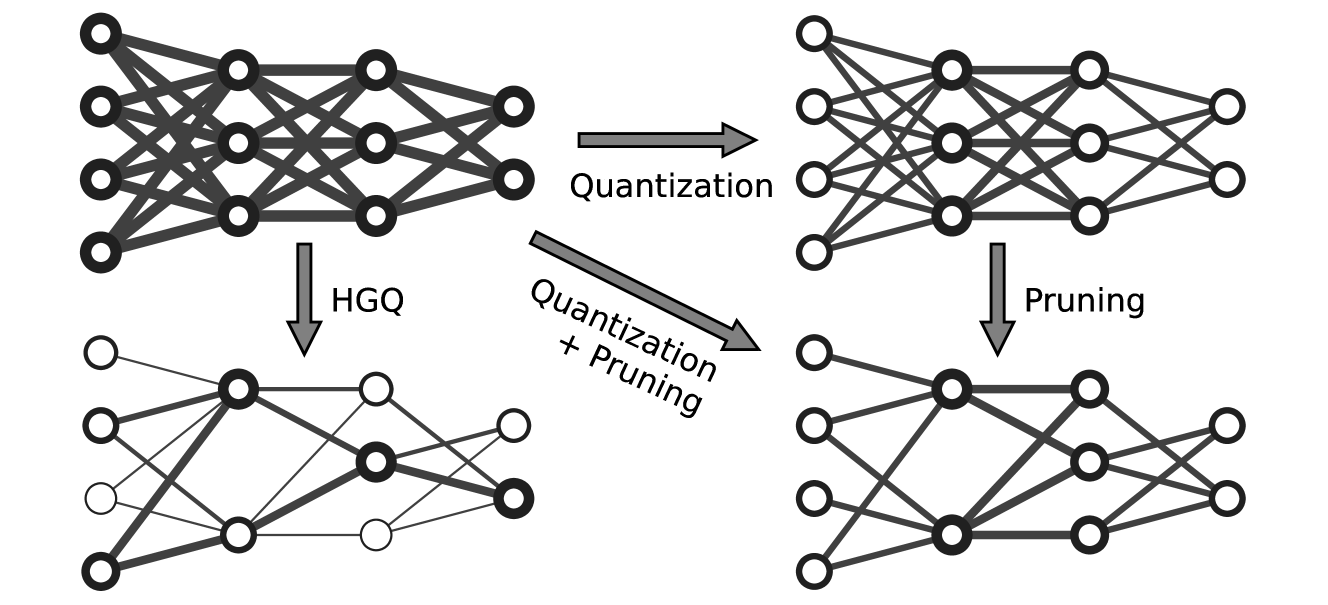
- This paper presents a new approach for automatically determining the optimal bitwidth for each weight in a neural network, a technique known as "per-weight mixed precision quantization."
- The authors propose a gradient-based method to find the best bitwidth for each weight during training, without requiring manual tuning or architecture search.
- The technique is designed to enable efficient neural network inference on edge devices with limited computational resources.
Plain English Explanation
The main idea behind this research is to find the optimal way to represent the numbers (or "weights") inside a neural network using as few bits as possible, while still maintaining the network's accuracy. [This is similar to the techniques used in the papers <a href="https://aimodels.fyi/papers/arxiv/qgen-ability-to-generalize-quantization-aware-training">QGen</a>, <a href="https://aimodels.fyi/papers/arxiv/aptq-attention-aware-post-training-mixed-precision">APTQ</a>, <a href="https://aimodels.fyi/papers/arxiv/adaqat-adaptive-bit-width-quantization-aware-training">AdaQAT</a>, <a href="https://aimodels.fyi/papers/arxiv/qllm-accurate-efficient-low-bitwidth-quantization-large">QLLM</a>, and <a href="https://aimodels.fyi/papers/arxiv/dnn-memory-footprint-reduction-via-post-training">DNN Memory Footprint Reduction</a>.]
Typically, neural networks use 32-bit floating-point numbers to represent these weights, which can be computationally expensive, especially on devices with limited hardware resources like phones or edge devices. The authors' approach allows the network to use different precisions (i.e., number of bits) for different weights, which can significantly reduce the overall memory and computation requirements without sacrificing too much accuracy.
The key innovation is that the authors developed a way to automatically determine the optimal bitwidth for each weight during the training process, rather than having to manually tune this or search through different configurations. This makes the technique easier to apply and more broadly useful.
Technical Explanation
The paper presents a new method for "per-weight mixed precision quantization" - the process of representing each weight in a neural network using the minimum number of bits required, rather than using the same precision for all weights.
The authors propose a gradient-based approach to automatically determine the optimal bitwidth for each weight during the training process. They introduce a set of "bitwidth parameters" that are learned alongside the network weights, allowing the bitwidth to be optimized for each weight through backpropagation.
The method works by adding a regularization term to the loss function that encourages the use of lower bitwidths where possible. This allows the network to find the sweet spot between accuracy and efficiency, using high precision only where necessary.
The authors evaluate their technique on several benchmark neural network models and datasets, demonstrating significant reductions in model size and computation requirements compared to uniform precision quantization, with only minor accuracy degradation. For example, on the ImageNet dataset, they were able to achieve a 4.5x reduction in model size and 3.5x reduction in multiply-accumulate operations with less than 1% top-1 accuracy loss.
Critical Analysis
The authors provide a thorough evaluation of their method, testing it on a variety of neural network architectures and datasets. The results show that the technique is effective at finding efficient mixed-precision representations without sacrificing too much accuracy.
One potential limitation is that the method requires modifying the training process, which may add some complexity compared to post-training quantization approaches. However, the authors argue that the benefits of automated bitwidth selection outweigh this drawback.
Additionally, the paper does not explore the impact of the proposed method on various hardware platforms or real-world deployment scenarios. Further research would be needed to understand how the technique performs in practical applications with strict latency and power constraints.
Overall, this work represents an interesting contribution to the field of efficient neural network inference, and the gradient-based approach to per-weight mixed precision quantization is a promising direction for future research.
Conclusion
This paper introduces a new gradient-based method for automatically determining the optimal bitwidth for each weight in a neural network during training. The technique, called "automatic per-weight mixed precision quantization," allows neural networks to use lower-precision representations where possible, leading to significant reductions in model size and computational requirements without major accuracy loss.
The authors demonstrate the effectiveness of their approach on several benchmark tasks, showing that it outperforms uniform precision quantization methods. While there are still some open questions around practical deployment, this work represents an important step towards enabling efficient and high-performing neural networks on resource-constrained edge devices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!