Graph External Attention Enhanced Transformer
2405.21061
0
0

Abstract
The Transformer architecture has recently gained considerable attention in the field of graph representation learning, as it naturally overcomes several limitations of Graph Neural Networks (GNNs) with customized attention mechanisms or positional and structural encodings. Despite making some progress, existing works tend to overlook external information of graphs, specifically the correlation between graphs. Intuitively, graphs with similar structures should have similar representations. Therefore, we propose Graph External Attention (GEA) -- a novel attention mechanism that leverages multiple external node/edge key-value units to capture inter-graph correlations implicitly. On this basis, we design an effective architecture called Graph External Attention Enhanced Transformer (GEAET), which integrates local structure and global interaction information for more comprehensive graph representations. Extensive experiments on benchmark datasets demonstrate that GEAET achieves state-of-the-art empirical performance. The source code is available for reproducibility at: https://github.com/icm1018/GEAET.
Create account to get full access
Overview
- The paper introduces a new transformer-based architecture called Graph External Attention Enhanced Transformer (GEAET) that improves upon existing graph neural network models by incorporating an external attention mechanism.
- The key idea is to leverage information from the graph structure to enhance the attention process, enabling the model to better capture the relationships between nodes.
- This approach is claimed to outperform state-of-the-art graph neural network models on various graph-based tasks.
Plain English Explanation
The paper presents a new type of transformer model designed to work with graph-structured data, such as social networks or molecular structures. Transformers are a popular type of neural network architecture that have been very successful in tasks like language modeling and translation.
The core innovation in this paper is the addition of an "external attention" mechanism. Typical transformer models use an "internal attention" process to let each part of the input attend to other relevant parts. In contrast, the external attention in GEAET also takes into account the connections in the input graph structure when determining what parts of the input to focus on.
This allows the model to better capture the relationships between different nodes or entities in the graph. For example, in a social network, the external attention could help the model understand how a person's connections to their friends and family influence their behavior, beyond just looking at the person's individual attributes.
The paper demonstrates that GEAET outperforms other state-of-the-art graph neural network models on a variety of benchmark tasks. This suggests the external attention approach is a promising direction for improving the performance of transformer-based models on graph-structured data.
Technical Explanation
The key aspect of the Graph External Attention Enhanced Transformer (GEAET) is the incorporation of an "external attention" mechanism in addition to the standard "internal attention" used in transformer models.
In a typical transformer, the internal attention allows each part of the input to attend to other relevant parts, helping the model capture dependencies. GEAET builds on this by also considering the graph structure of the input data when determining attention weights.
Specifically, the external attention module takes the node features and the adjacency matrix representing the graph connections as inputs. It then computes attention weights that capture both the content similarity between nodes as well as their structural proximity in the graph. These attention weights are then used to aggregate information from neighboring nodes, enhancing the representations.
The authors demonstrate the effectiveness of this approach through experiments on several graph-based tasks, including node classification, graph classification, and link prediction. GEAET is shown to outperform other state-of-the-art graph neural network models and transformer-based architectures for these tasks.
Critical Analysis
The paper presents a well-designed study and a promising new architecture for graph-based tasks. The authors have carefully compared GEAET to a range of existing methods and demonstrated its superior performance.
However, some potential limitations and areas for further research are worth considering:
-
The authors only evaluate GEAET on relatively small-scale graph datasets. It would be valuable to see how the model scales to larger, more complex graph structures that are more representative of real-world applications.
-
The paper does not provide a detailed analysis of the types of graph structures or tasks where the external attention mechanism is most beneficial. Further investigation into the specific properties of graphs that enable GEAET to excel would be insightful.
-
While the external attention approach is novel, the authors do not discuss its computational complexity or training efficiency compared to other graph neural network models. These practical considerations could be important for real-world deployment.
-
The paper would be strengthened by a more thorough discussion of how GEAET relates to and differs from other transformer-based graph models in the literature.
Overall, the GEAET architecture represents a valuable contribution to the field of graph neural networks. The external attention mechanism is a compelling idea that merits further exploration and refinement.
Conclusion
The Graph External Attention Enhanced Transformer (GEAET) proposed in this paper introduces an innovative way to incorporate graph structure information into a transformer-based architecture. By leveraging an external attention mechanism, the model is able to better capture the relationships between nodes in graph-structured data, leading to improved performance on a variety of graph-based tasks.
This research suggests that carefully designing attention processes to match the properties of the input data can be a fruitful direction for advancing the state-of-the-art in transformer-based models. The external attention approach demonstrated in GEAET could inspire similar enhancements to transformer architectures for other types of structured data beyond just graphs.
While the paper presents a solid technical contribution, there are some areas for further exploration, such as evaluating the model's scalability, understanding its strengths and weaknesses for different graph characteristics, and comparing it more extensively to other transformer-based graph models. Nonetheless, the GEAET architecture represents an important step forward in the field of graph neural networks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
AnchorGT: Efficient and Flexible Attention Architecture for Scalable Graph Transformers
Wenhao Zhu, Guojie Song, Liang Wang, Shaoguo Liu
0
0
Graph Transformers (GTs) have significantly advanced the field of graph representation learning by overcoming the limitations of message-passing graph neural networks (GNNs) and demonstrating promising performance and expressive power. However, the quadratic complexity of self-attention mechanism in GTs has limited their scalability, and previous approaches to address this issue often suffer from expressiveness degradation or lack of versatility. To address this issue, we propose AnchorGT, a novel attention architecture for GTs with global receptive field and almost linear complexity, which serves as a flexible building block to improve the scalability of a wide range of GT models. Inspired by anchor-based GNNs, we employ structurally important $k$-dominating node set as anchors and design an attention mechanism that focuses on the relationship between individual nodes and anchors, while retaining the global receptive field for all nodes. With its intuitive design, AnchorGT can easily replace the attention module in various GT models with different network architectures and structural encodings, resulting in reduced computational overhead without sacrificing performance. In addition, we theoretically prove that AnchorGT attention can be strictly more expressive than Weisfeiler-Lehman test, showing its superiority in representing graph structures. Our experiments on three state-of-the-art GT models demonstrate that their AnchorGT variants can achieve better results while being faster and significantly more memory efficient.
5/7/2024
A Scalable and Effective Alternative to Graph Transformers
Kaan Sancak, Zhigang Hua, Jin Fang, Yan Xie, Andrey Malevich, Bo Long, Muhammed Fatih Balin, Umit V. c{C}atalyurek
0
0
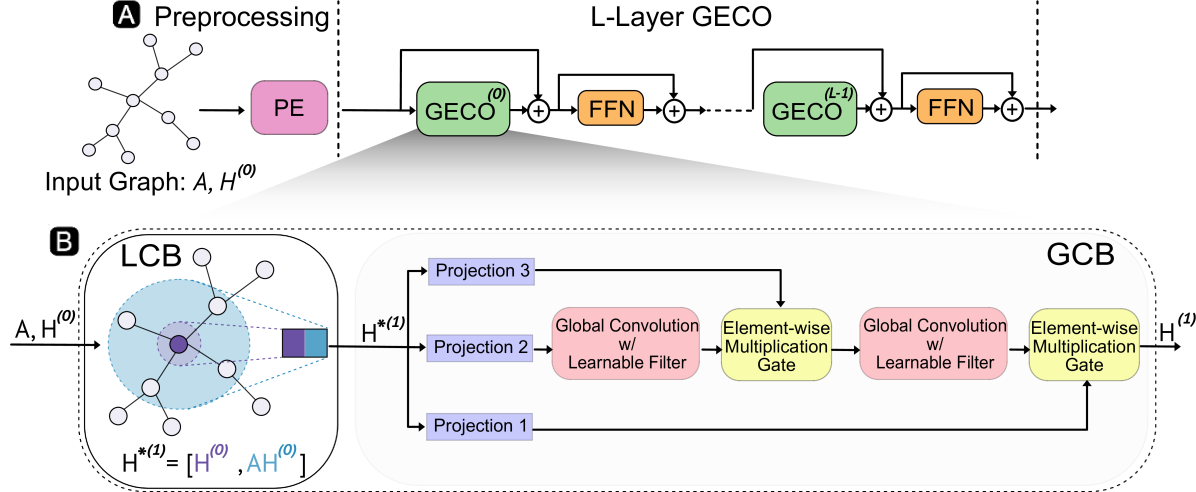
Graph Neural Networks (GNNs) have shown impressive performance in graph representation learning, but they face challenges in capturing long-range dependencies due to their limited expressive power. To address this, Graph Transformers (GTs) were introduced, utilizing self-attention mechanism to effectively model pairwise node relationships. Despite their advantages, GTs suffer from quadratic complexity w.r.t. the number of nodes in the graph, hindering their applicability to large graphs. In this work, we present Graph-Enhanced Contextual Operator (GECO), a scalable and effective alternative to GTs that leverages neighborhood propagation and global convolutions to effectively capture local and global dependencies in quasilinear time. Our study on synthetic datasets reveals that GECO reaches 169x speedup on a graph with 2M nodes w.r.t. optimized attention. Further evaluations on diverse range of benchmarks showcase that GECO scales to large graphs where traditional GTs often face memory and time limitations. Notably, GECO consistently achieves comparable or superior quality compared to baselines, improving the SOTA up to 4.5%, and offering a scalable and effective solution for large-scale graph learning.
6/19/2024

Towards Principled Graph Transformers
Luis Muller, Daniel Kusuma, Blai Bonet, Christopher Morris
0
0
Graph learning architectures based on the k-dimensional Weisfeiler-Leman (k-WL) hierarchy offer a theoretically well-understood expressive power. However, such architectures often fail to deliver solid predictive performance on real-world tasks, limiting their practical impact. In contrast, global attention-based models such as graph transformers demonstrate strong performance in practice, but comparing their expressive power with the k-WL hierarchy remains challenging, particularly since these architectures rely on positional or structural encodings for their expressivity and predictive performance. To address this, we show that the recently proposed Edge Transformer, a global attention model operating on node pairs instead of nodes, has at least 3-WL expressive power. Empirically, we demonstrate that the Edge Transformer surpasses other theoretically aligned architectures regarding predictive performance while not relying on positional or structural encodings. Our code is available at https://github.com/luis-mueller/towards-principled-gts
5/27/2024
🔎
Topology-guided Hypergraph Transformer Network: Unveiling Structural Insights for Improved Representation
Khaled Mohammed Saifuddin, Mehmet Emin Aktas, Esra Akbas
0
0
Hypergraphs, with their capacity to depict high-order relationships, have emerged as a significant extension of traditional graphs. Although Graph Neural Networks (GNNs) have remarkable performance in graph representation learning, their extension to hypergraphs encounters challenges due to their intricate structures. Furthermore, current hypergraph transformers, a special variant of GNN, utilize semantic feature-based self-attention, ignoring topological attributes of nodes and hyperedges. To address these challenges, we propose a Topology-guided Hypergraph Transformer Network (THTN). In this model, we first formulate a hypergraph from a graph while retaining its structural essence to learn higher-order relations within the graph. Then, we design a simple yet effective structural and spatial encoding module to incorporate the topological and spatial information of the nodes into their representation. Further, we present a structure-aware self-attention mechanism that discovers the important nodes and hyperedges from both semantic and structural viewpoints. By leveraging these two modules, THTN crafts an improved node representation, capturing both local and global topological expressions. Extensive experiments conducted on node classification tasks demonstrate that the performance of the proposed model consistently exceeds that of the existing approaches.
5/22/2024