HOI-M3:Capture Multiple Humans and Objects Interaction within Contextual Environment
2404.00299
0
0

Abstract
Humans naturally interact with both others and the surrounding multiple objects, engaging in various social activities. However, recent advances in modeling human-object interactions mostly focus on perceiving isolated individuals and objects, due to fundamental data scarcity. In this paper, we introduce HOI-M3, a novel large-scale dataset for modeling the interactions of Multiple huMans and Multiple objects. Notably, it provides accurate 3D tracking for both humans and objects from dense RGB and object-mounted IMU inputs, covering 199 sequences and 181M frames of diverse humans and objects under rich activities. With the unique HOI-M3 dataset, we introduce two novel data-driven tasks with companion strong baselines: monocular capture and unstructured generation of multiple human-object interactions. Extensive experiments demonstrate that our dataset is challenging and worthy of further research about multiple human-object interactions and behavior analysis. Our HOI-M3 dataset, corresponding codes, and pre-trained models will be disseminated to the community for future research.
Create account to get full access
Overview
- The paper presents a new dataset called HOI-M³ that captures interactions between multiple humans and objects within a contextual environment.
- The dataset aims to advance research in human-object interaction (HOI) recognition by providing more realistic and complex scenarios.
- The authors also introduce a new deep learning architecture to tackle the challenges of this dataset.
Plain English Explanation
The paper describes a new dataset that could help computers better understand how people interact with objects in real-world settings. Most existing datasets for this type of research only show single people interacting with individual objects. However, in reality, people often interact with multiple objects at the same time, and their actions are influenced by the surrounding environment.
The new HOI-M³ dataset aims to capture these more complex, real-world scenarios. It contains images and videos of multiple people interacting with various objects within a contextual setting, such as a kitchen or an office. The goal is to provide a more realistic training ground for computer vision models that want to recognize and understand human-object interactions.
Along with the dataset, the researchers also developed a new deep learning approach to analyze the data. This architecture is designed to handle the added complexities of multiple people and objects within a scene, rather than just focusing on single person-object pairings.
By providing a more realistic dataset and a novel analysis technique, the hope is that this work can advance the state-of-the-art in human-object interaction recognition. This could have applications in areas like smart home assistants, autonomous vehicles, and augmented reality, where understanding how people manipulate their environments is crucial.
Technical Explanation
The HOI-M³ dataset contains over 100,000 images and 10,000 videos depicting multiple humans and objects interacting within contextual environments. This is a significant expansion over existing human-object interaction (HOI) datasets, which typically only include single-person, single-object scenarios.
To capture these more complex scenes, the authors developed a specialized data collection and annotation pipeline. This involved setting up realistic indoor and outdoor scenes, directing actors to perform scripted and spontaneous interactions, and then precisely labeling the positions, identities, and interactions of all humans and objects in each frame.
The resulting dataset provides a rich testbed for evaluating HOI recognition algorithms. It features a diverse range of object types, interaction types, and environmental contexts, making it more representative of real-world conditions compared to prior datasets.
To tackle the challenges posed by HOI-M³, the authors also introduce a new deep learning architecture called M³-HOI-Net. This model leverages graph neural networks to jointly reason about the relationships between multiple humans, objects, and the surrounding context. It outperforms existing approaches on the HOI-M³ benchmark, suggesting its potential for advancing the field of human-object interaction understanding.
Critical Analysis
The HOI-M³ dataset and M³-HOI-Net model represent a significant advancement in the state-of-the-art for human-object interaction recognition. By moving beyond simple, constrained scenarios, the authors have created a more realistic and challenging benchmark that better reflects the complexities of the real world.
However, the paper acknowledges several limitations and areas for future work. The dataset is still captured in a controlled setting, and may not fully capture the diversity of real-world environments and interactions. Additionally, the annotation process is labor-intensive, which could restrict the scalability of the dataset.
The M³-HOI-Net architecture, while promising, is also a relatively early step in tackling the complexities of multi-human, multi-object interaction understanding. There is likely significant room for improvement, both in terms of the model design and the training/inference techniques employed.
Overall, this work represents an important milestone in pushing the boundaries of human-object interaction recognition. While not without its limitations, the HOI-M³ dataset and M³-HOI-Net model provide a valuable new benchmark and tool for the computer vision community to build upon in the pursuit of more robust, generalizable, and human-centric scene understanding.
Conclusion
The HOI-M³ dataset and M³-HOI-Net model introduced in this paper mark a significant advancement in the field of human-object interaction recognition. By moving beyond simplistic, single-person, single-object scenarios, the researchers have created a more realistic and challenging benchmark that better reflects the complexities of real-world environments and interactions.
This work has the potential to drive progress in a variety of applications, from smart home assistants to autonomous vehicles, where understanding how people manipulate and interact with their surroundings is crucial. While the dataset and model still have room for improvement, they represent an important step forward in the pursuit of more robust and human-centric scene understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Open-World Human-Object Interaction Detection via Multi-modal Prompts
Jie Yang, Bingliang Li, Ailing Zeng, Lei Zhang, Ruimao Zhang
0
0
In this paper, we develop textbf{MP-HOI}, a powerful Multi-modal Prompt-based HOI detector designed to leverage both textual descriptions for open-set generalization and visual exemplars for handling high ambiguity in descriptions, realizing HOI detection in the open world. Specifically, it integrates visual prompts into existing language-guided-only HOI detectors to handle situations where textual descriptions face difficulties in generalization and to address complex scenarios with high interaction ambiguity. To facilitate MP-HOI training, we build a large-scale HOI dataset named Magic-HOI, which gathers six existing datasets into a unified label space, forming over 186K images with 2.4K objects, 1.2K actions, and 20K HOI interactions. Furthermore, to tackle the long-tail issue within the Magic-HOI dataset, we introduce an automated pipeline for generating realistically annotated HOI images and present SynHOI, a high-quality synthetic HOI dataset containing 100K images. Leveraging these two datasets, MP-HOI optimizes the HOI task as a similarity learning process between multi-modal prompts and objects/interactions via a unified contrastive loss, to learn generalizable and transferable objects/interactions representations from large-scale data. MP-HOI could serve as a generalist HOI detector, surpassing the HOI vocabulary of existing expert models by more than 30 times. Concurrently, our results demonstrate that MP-HOI exhibits remarkable zero-shot capability in real-world scenarios and consistently achieves a new state-of-the-art performance across various benchmarks.
6/12/2024

CooHOI: Learning Cooperative Human-Object Interaction with Manipulated Object Dynamics
Jiawei Gao, Ziqin Wang, Zeqi Xiao, Jingbo Wang, Tai Wang, Jinkun Cao, Xiaolin Hu, Si Liu, Jifeng Dai, Jiangmiao Pang
0
0
Recent years have seen significant advancements in humanoid control, largely due to the availability of large-scale motion capture data and the application of reinforcement learning methodologies. However, many real-world tasks, such as moving large and heavy furniture, require multi-character collaboration. Given the scarcity of data on multi-character collaboration and the efficiency challenges associated with multi-agent learning, these tasks cannot be straightforwardly addressed using training paradigms designed for single-agent scenarios. In this paper, we introduce Cooperative Human-Object Interaction (CooHOI), a novel framework that addresses multi-character objects transporting through a two-phase learning paradigm: individual skill acquisition and subsequent transfer. Initially, a single agent learns to perform tasks using the Adversarial Motion Priors (AMP) framework. Following this, the agent learns to collaborate with others by considering the shared dynamics of the manipulated object during parallel training using Multi Agent Proximal Policy Optimization (MAPPO). When one agent interacts with the object, resulting in specific object dynamics changes, the other agents learn to respond appropriately, thereby achieving implicit communication and coordination between teammates. Unlike previous approaches that relied on tracking-based methods for multi-character HOI, CooHOI is inherently efficient, does not depend on motion capture data of multi-character interactions, and can be seamlessly extended to include more participants and a wide range of object types
6/21/2024
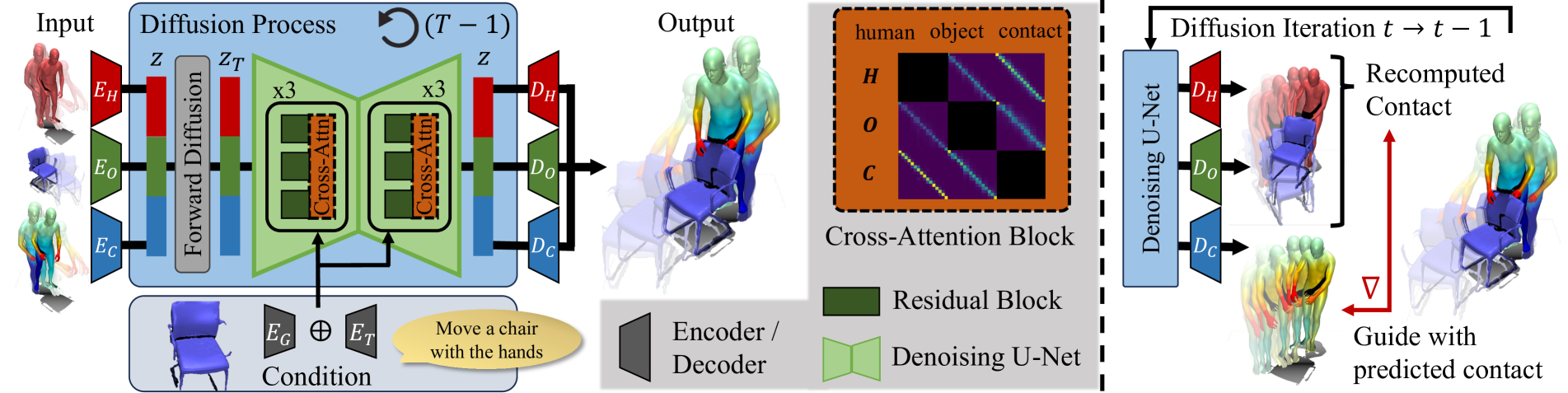
CG-HOI: Contact-Guided 3D Human-Object Interaction Generation
Christian Diller, Angela Dai
0
0
We propose CG-HOI, the first method to address the task of generating dynamic 3D human-object interactions (HOIs) from text. We model the motion of both human and object in an interdependent fashion, as semantically rich human motion rarely happens in isolation without any interactions. Our key insight is that explicitly modeling contact between the human body surface and object geometry can be used as strong proxy guidance, both during training and inference. Using this guidance to bridge human and object motion enables generating more realistic and physically plausible interaction sequences, where the human body and corresponding object move in a coherent manner. Our method first learns to model human motion, object motion, and contact in a joint diffusion process, inter-correlated through cross-attention. We then leverage this learned contact for guidance during inference to synthesize realistic and coherent HOIs. Extensive evaluation shows that our joint contact-based human-object interaction approach generates realistic and physically plausible sequences, and we show two applications highlighting the capabilities of our method. Conditioned on a given object trajectory, we can generate the corresponding human motion without re-training, demonstrating strong human-object interdependency learning. Our approach is also flexible, and can be applied to static real-world 3D scene scans.
5/20/2024
👀
HOI4ABOT: Human-Object Interaction Anticipation for Human Intention Reading Collaborative roBOTs
Esteve Valls Mascaro, Daniel Sliwowski, Dongheui Lee
0
0
Robots are becoming increasingly integrated into our lives, assisting us in various tasks. To ensure effective collaboration between humans and robots, it is essential that they understand our intentions and anticipate our actions. In this paper, we propose a Human-Object Interaction (HOI) anticipation framework for collaborative robots. We propose an efficient and robust transformer-based model to detect and anticipate HOIs from videos. This enhanced anticipation empowers robots to proactively assist humans, resulting in more efficient and intuitive collaborations. Our model outperforms state-of-the-art results in HOI detection and anticipation in VidHOI dataset with an increase of 1.76% and 1.04% in mAP respectively while being 15.4 times faster. We showcase the effectiveness of our approach through experimental results in a real robot, demonstrating that the robot's ability to anticipate HOIs is key for better Human-Robot Interaction. More information can be found on our project webpage: https://evm7.github.io/HOI4ABOT_page/
4/9/2024