HPC Alongside User-space Kubernetes
2406.06995
0
0

Abstract
High performance computing (HPC) and cloud have traditionally been separate, and presented in an adversarial light. The conflict arises from disparate beginnings that led to two drastically different cultures, incentive structures, and communities that are now in direct competition with one another for resources, talent, and speed of innovation. With the emergence of converged computing, a new paradigm of computing has entered the space that advocates for bringing together the best of both worlds from a technological and cultural standpoint. This movement has emerged due to economic and practical needs. Emerging heterogeneous, complex scientific workloads that require an orchestration of services, simulation, and reaction to state can no longer be served by traditional HPC paradigms. However, while cloud offers automation, portability, and orchestration, as it stands now it cannot deliver the network performance, fine-grained resource mapping, or scalability that these same simulations require. These novel requirements call for change not just in workflow software or design, but also in the underlying infrastructure to support them. This is one of the goals of converged computing. While the future of traditional HPC and commercial cloud cannot be entirely known, a reasonable approach to take is one that focuses on new models of convergence, and a collaborative mindset. In this paper, we introduce a new paradigm for compute -- a traditional HPC workload manager, Flux Framework, running seamlessly with a user-space Kubernetes Usernetes to bring a service-oriented, modular, and portable architecture directly to on-premises HPC clusters. We present experiments that assess HPC application performance and networking between the environments, and provide a reproducible setup for the larger community to do exactly that.
Create account to get full access
Overview
- Explores the integration of High Performance Computing (HPC) and user-space Kubernetes
- Aims to leverage the strengths of both HPC and cloud-native technologies
- Focuses on overcoming challenges in converging these disparate computing paradigms
Plain English Explanation
This paper investigates ways to effectively combine High Performance Computing (HPC) and user-space Kubernetes, two computing approaches that have traditionally been quite different. The goal is to take advantage of the benefits of each approach, creating a "converged computing" system that can handle a wider range of workloads.
HPC systems are optimized for running complex, resource-intensive scientific and engineering simulations, often using specialized hardware like GPUs. In contrast, Kubernetes is a popular platform for deploying and managing cloud-native applications, which tend to be more modular and scalable. By bringing these two worlds together, the researchers aim to enable more flexible and efficient computing that can tackle a broader set of problems, from high-performance scientific computing to distributed, cloud-based applications.
Technical Explanation
The paper proposes an architecture that allows HPC workloads to run alongside user-space Kubernetes clusters. This involves deploying a Kubernetes control plane within the HPC environment, enabling users to leverage Kubernetes' container-based deployment model and ecosystem of tools and services.
Key elements of the approach include:
- Hybrid HPC-Cloud Infrastructure: Combining traditional HPC resources (e.g., high-performance compute nodes, specialized accelerators) with cloud-based Kubernetes clusters running on the same physical infrastructure.
- User-space Kubernetes: Running Kubernetes in a user-space environment, without requiring privileged access or modifications to the underlying HPC system.
- Resource Disaggregation: Separating compute, storage, and networking resources to enable more flexible and efficient resource allocation.
- Heterogeneous Workload Support: Allowing a diverse range of workloads, from tightly-coupled HPC simulations to loosely-coupled, cloud-native applications, to coexist and utilize the same underlying infrastructure.
The researchers evaluate the performance and overhead of their approach through various benchmarks and use cases, demonstrating the feasibility and potential benefits of this converged computing model.
Critical Analysis
The paper acknowledges several challenges and limitations in integrating HPC and Kubernetes, such as ensuring high performance for HPC workloads, managing resource contention, and maintaining isolation between different types of workloads.
One potential concern is the overhead and complexity introduced by running Kubernetes alongside the existing HPC infrastructure. The researchers aim to mitigate this by using a user-space Kubernetes deployment, but the impact on overall system performance and resource utilization would need further investigation.
Additionally, the paper focuses primarily on the technical aspects of the integration, leaving room for deeper analysis of the practical and operational implications for HPC facilities and research teams. Factors like adoption barriers, training requirements, and the impact on existing workflows would be valuable to explore in future research.
Conclusion
This paper presents a compelling vision for converging HPC and cloud-native technologies, enabling more flexible and efficient computing by leveraging the strengths of both approaches. The proposed architecture demonstrates the feasibility of running Kubernetes alongside traditional HPC systems, paving the way for new types of hybrid computing environments that can support a wider range of scientific and engineering workloads.
As high-performance computing continues to play a crucial role in advancing scientific discovery and technological innovation, the ability to seamlessly integrate HPC resources with cloud-based, scalable computing platforms could have significant implications for the future of computational research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
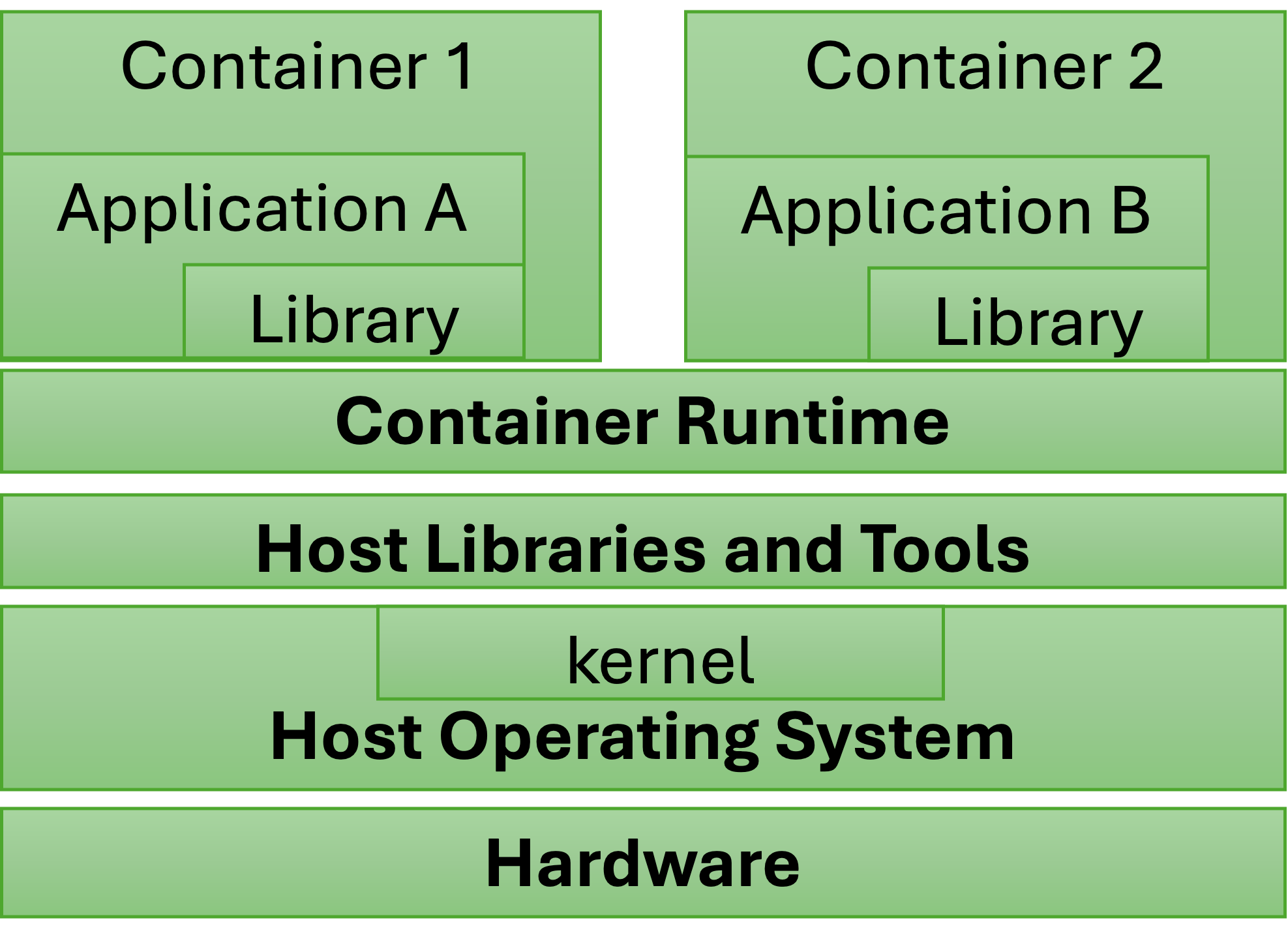
Understanding Layered Portability from HPC to Cloud in Containerized Environments
Daniel Medeiros, Gabin Schieffer, Jacob Wahlgren, Ivy Peng
0
0
Recent development in lightweight OS-level virtualization, containers, provides a potential solution for running HPC applications on the cloud platform. In this work, we focus on the impact of different layers in a containerized environment when migrating HPC containers from a dedicated HPC system to a cloud platform. On three ARM-based platforms, including the latest Nvidia Grace CPU, we use six representative HPC applications to characterize the impact of container virtualization, host OS and kernel, and rootless and privileged container execution. Our results indicate less than 4% container overhead in DGEMM, miniMD, and XSBench, but 8%-10% overhead in FFT, HPCG, and Hypre. We also show that changing between the container execution modes results in negligible performance differences in the six applications.
6/18/2024
🧪
HPX with Spack and Singularity Containers: Evaluating Overheads for HPX/Kokkos using an astrophysics application
Patrick Diehl, Steven R. Brandt, Gregor Dai{ss}, Hartmut Kaiser
0
0
Cloud computing for high performance computing resources is an emerging topic. This service is of interest to researchers who care about reproducible computing, for software packages with complex installations, and for companies or researchers who need the compute resources only occasionally or do not want to run and maintain a supercomputer on their own. The connection between HPC and containers is exemplified by the fact that Microsoft Azure's Eagle cloud service machine is number three on the November 23 Top 500 list. For cloud services, the HPC application and dependencies are installed in containers, e.g. Docker, Singularity, or something else, and these containers are executed on the physical hardware. Although containerization leverages the existing Linux kernel and should not impose overheads on the computation, there is the possibility that machine-specific optimizations might be lost, particularly machine-specific installs of commonly used packages. In this paper, we will use an astrophysics application using HPX-Kokkos and measure overheads on homogeneous resources, e.g. Supercomputer Fugaku, using CPUs only and on heterogenous resources, e.g. LSU's hybrid CPU and GPU system. We will report on challenges in compiling, running, and using the containers as well as performance performance differences.
5/8/2024

On the Convergence of Malleability and the HPC PowerStack: Exploiting Dynamism in Over-Provisioned and Power-Constrained HPC Systems
Eishi Arima, Isa'ias A. Compr'es, Martin Schulz
0
0
Recent High-Performance Computing (HPC) systems are facing important challenges, such as massive power consumption, while at the same time significantly under-utilized system resources. Given the power consumption trends, future systems will be deployed in an over-provisioned manner where more resources are installed than they can afford to power simultaneously. In such a scenario, maximizing resource utilization and energy efficiency, while keeping a given power constraint, is pivotal. Driven by this observation, in this position paper we first highlight the recent trends of resource management techniques, with a particular focus on malleability support (i.e., dynamically scaling resource allocations/requirements for a job), co-scheduling (i.e., co-locating multiple jobs within a node), and power management. Second, we consider putting them together, assess their relationships/synergies, and discuss the functionality requirements in each software component for future over-provisioned and power-constrained HPC systems. Third, we briefly introduce our ongoing efforts on the integration of software tools, which will ultimately lead to the convergence of malleability and power management, as it is designed in the HPC PowerStack initiative.
5/8/2024

Everywhere & Nowhere: Envisioning a Computing Continuum for Science
Manish Parashar
0
0
Emerging data-driven scientific workflows are seeking to leverage distributed data sources to understand end-to-end phenomena, drive experimentation, and facilitate important decision-making. Despite the exponential growth of available digital data sources at the edge, and the ubiquity of non trivial computational power for processing this data, realizing such science workflows remains challenging. This paper explores a computing continuum that is everywhere and nowhere -- one spanning resources at the edges, in the core and in between, and providing abstractions that can be harnessed to support science. It also introduces recent research in programming abstractions that can express what data should be processed and when and where it should be processed, and autonomic middleware services that automate the discovery of resources and the orchestration of computations across these resources.
6/10/2024