Improved Convergence of Score-Based Diffusion Models via Prediction-Correction
2305.14164
0
0
💬
Abstract
Score-based generative models (SGMs) are powerful tools to sample from complex data distributions. Their underlying idea is to (i) run a forward process for time $T_1$ by adding noise to the data, (ii) estimate its score function, and (iii) use such estimate to run a reverse process. As the reverse process is initialized with the stationary distribution of the forward one, the existing analysis paradigm requires $T_1toinfty$. This is however problematic: from a theoretical viewpoint, for a given precision of the score approximation, the convergence guarantee fails as $T_1$ diverges; from a practical viewpoint, a large $T_1$ increases computational costs and leads to error propagation. This paper addresses the issue by considering a version of the popular predictor-corrector scheme: after running the forward process, we first estimate the final distribution via an inexact Langevin dynamics and then revert the process. Our key technical contribution is to provide convergence guarantees which require to run the forward process only for a fixed finite time $T_1$. Our bounds exhibit a mild logarithmic dependence on the input dimension and the subgaussian norm of the target distribution, have minimal assumptions on the data, and require only to control the $L^2$ loss on the score approximation, which is the quantity minimized in practice.
Create account to get full access
Overview
- Score-based generative models (SGMs) are powerful tools for generating samples from complex data distributions.
- The core idea is to (1) add noise to the data, (2) estimate the "score function" (a measure of how the data changes with noise), and (3) use the estimated score to reverse the process and generate new samples.
- Traditional analysis of SGMs requires the forward noise-adding process to run for an infinitely long time, which is problematic both theoretically and practically.
- This paper addresses this issue by proposing a "predictor-corrector" approach that only requires a fixed, finite time for the forward process.
Plain English Explanation
Score-based generative models are a type of machine learning model that can generate new data samples that look similar to a given dataset. The way they work is:
- They start with the original data and add random noise to it, a little bit at a time. This is the "forward process".
- They then estimate a "score function" - this tells them how the data is changing as the noise is added.
- They can then use this score function to reverse the process, starting with random noise and gradually removing it to generate new samples that look like the original data.
The key issue with the traditional approach is that the forward process needs to run for an infinitely long time to guarantee the process converges. This is both theoretically problematic and computationally expensive in practice.
This paper proposes a new approach that only requires the forward process to run for a fixed, finite amount of time. It does this by first estimating the final distribution using an "inexact Langevin dynamics" method, and then reverting the process from there. This provides theoretical guarantees while being much more efficient computationally.
Technical Explanation
The paper presents a new approach to training and using score-based generative models that addresses key issues with the traditional paradigm.
Traditionally, SGMs work by (1) running a "forward process" that gradually adds noise to the data over time T1, (2) estimating the "score function" that describes how the data changes with the added noise, and (3) using this score function to run a "reverse process" that generates new samples.
The key problem is that the existing analysis requires T1 to approach infinity, which is problematic. Theoretically, as T1 gets larger, the convergence guarantees become weaker. Practically, a large T1 increases computational costs and leads to error propagation.
The proposed approach: After the forward process, the paper first estimates the final data distribution using an "inexact Langevin dynamics" method. It then uses this estimate to run the reverse process, without needing T1 to approach infinity.
The key technical contribution is to provide convergence guarantees that only require a fixed, finite T1. These bounds exhibit only a mild logarithmic dependence on problem size, have minimal assumptions, and only require controlling the L2 loss on the score function estimate.
Critical Analysis
The paper makes an important contribution by addressing a key issue with the traditional SGM framework - the need for an infinitely long forward process. This is a significant practical limitation, so the proposed approach is an important advance.
That said, the paper does not explore the limitations or potential downsides of the new method in depth. For example, it would be helpful to understand:
- How the performance and sample quality of the new approach compares to traditional SGMs, especially as problem size increases.
- The sensitivity of the method to errors or approximations in estimating the final data distribution and score function.
- Whether there are any important applications or data regimes where the new method may not be suitable.
Additionally, the paper does not situate its work in the broader context of SGM research or discuss potential future directions. A more comprehensive discussion of the method's strengths, limitations, and research implications would strengthen the analysis.
Conclusion
This paper presents an important advance in score-based generative modeling by addressing a key practical and theoretical limitation of the traditional approach. The proposed "predictor-corrector" method can generate samples with strong theoretical guarantees while requiring significantly less computational resources.
While the technical details are complex, the core idea is intuitive and impactful - finding a way to avoid the need for an infinitely long forward process opens up new possibilities for deploying SGMs in real-world applications. Further research is needed to fully understand the strengths and limitations of this new approach, but it represents an important step forward for this influential class of generative models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
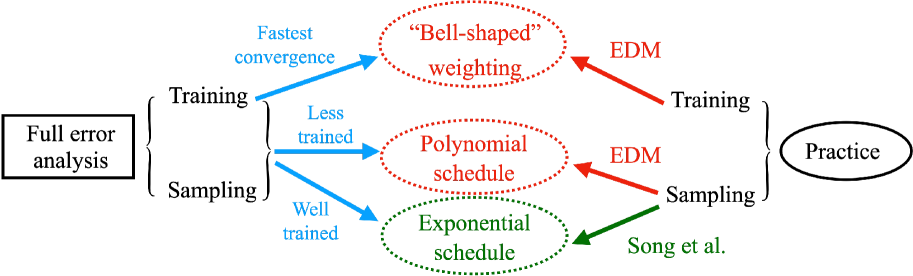
Evaluating the design space of diffusion-based generative models
Yuqing Wang, Ye He, Molei Tao
0
0
Most existing theoretical investigations of the accuracy of diffusion models, albeit significant, assume the score function has been approximated to a certain accuracy, and then use this a priori bound to control the error of generation. This article instead provides a first quantitative understanding of the whole generation process, i.e., both training and sampling. More precisely, it conducts a non-asymptotic convergence analysis of denoising score matching under gradient descent. In addition, a refined sampling error analysis for variance exploding models is also provided. The combination of these two results yields a full error analysis, which elucidates (again, but this time theoretically) how to design the training and sampling processes for effective generation. For instance, our theory implies a preference toward noise distribution and loss weighting that qualitatively agree with the ones used in [Karras et al. 2022]. It also provides some perspectives on why the time and variance schedule used in [Karras et al. 2022] could be better tuned than the pioneering version in [Song et al. 2020].
6/19/2024
🏋️
Score-based Generative Models with Adaptive Momentum
Ziqing Wen, Xiaoge Deng, Ping Luo, Tao Sun, Dongsheng Li
0
0
Score-based generative models have demonstrated significant practical success in data-generating tasks. The models establish a diffusion process that perturbs the ground truth data to Gaussian noise and then learn the reverse process to transform noise into data. However, existing denoising methods such as Langevin dynamic and numerical stochastic differential equation solvers enjoy randomness but generate data slowly with a large number of score function evaluations, and the ordinary differential equation solvers enjoy faster sampling speed but no randomness may influence the sample quality. To this end, motivated by the Stochastic Gradient Descent (SGD) optimization methods and the high connection between the model sampling process with the SGD, we propose adaptive momentum sampling to accelerate the transforming process without introducing additional hyperparameters. Theoretically, we proved our method promises convergence under given conditions. In addition, we empirically show that our sampler can produce more faithful images/graphs in small sampling steps with 2 to 5 times speed up and obtain competitive scores compared to the baselines on image and graph generation tasks.
5/24/2024
📊
Global Well-posedness and Convergence Analysis of Score-based Generative Models via Sharp Lipschitz Estimates
Connor Mooney, Zhongjian Wang, Jack Xin, Yifeng Yu
0
0
We establish global well-posedness and convergence of the score-based generative models (SGM) under minimal general assumptions of initial data for score estimation. For the smooth case, we start from a Lipschitz bound of the score function with optimal time length. The optimality is validated by an example whose Lipschitz constant of scores is bounded at initial but blows up in finite time. This necessitates the separation of time scales in conventional bounds for non-log-concave distributions. In contrast, our follow up analysis only relies on a local Lipschitz condition and is valid globally in time. This leads to the convergence of numerical scheme without time separation. For the non-smooth case, we show that the optimal Lipschitz bound is O(1/t) in the point-wise sense for distributions supported on a compact, smooth and low-dimensional manifold with boundary.
5/28/2024

Taming Score-Based Diffusion Priors for Infinite-Dimensional Nonlinear Inverse Problems
Lorenzo Baldassari, Ali Siahkoohi, Josselin Garnier, Knut Solna, Maarten V. de Hoop
0
0
This work introduces a sampling method capable of solving Bayesian inverse problems in function space. It does not assume the log-concavity of the likelihood, meaning that it is compatible with nonlinear inverse problems. The method leverages the recently defined infinite-dimensional score-based diffusion models as a learning-based prior, while enabling provable posterior sampling through a Langevin-type MCMC algorithm defined on function spaces. A novel convergence analysis is conducted, inspired by the fixed-point methods established for traditional regularization-by-denoising algorithms and compatible with weighted annealing. The obtained convergence bound explicitly depends on the approximation error of the score; a well-approximated score is essential to obtain a well-approximated posterior. Stylized and PDE-based examples are provided, demonstrating the validity of our convergence analysis. We conclude by presenting a discussion of the method's challenges related to learning the score and computational complexity.
5/27/2024