Improved Distribution Matching Distillation for Fast Image Synthesis
2405.14867
0
0
🖼️
Abstract
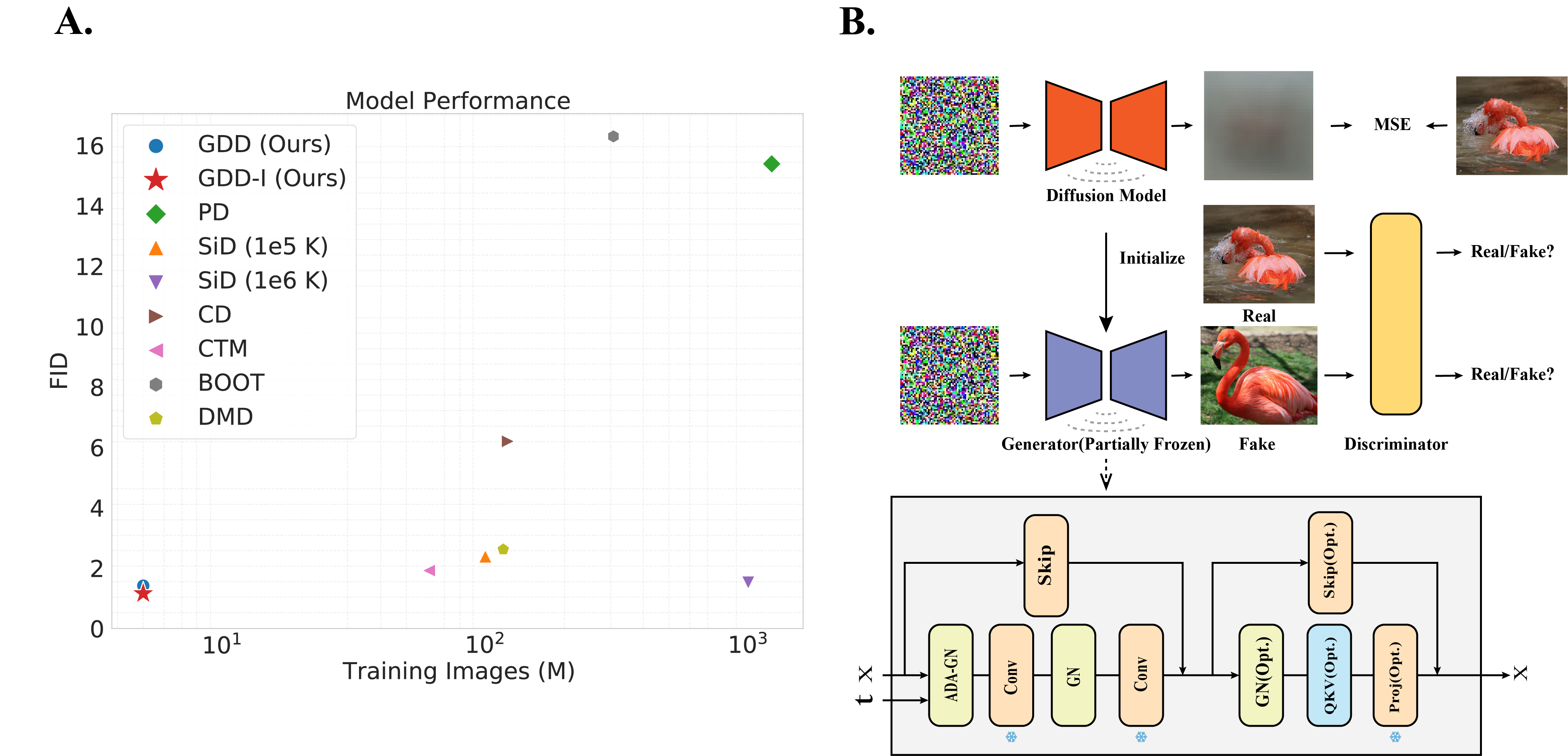
Recent approaches have shown promises distilling diffusion models into efficient one-step generators. Among them, Distribution Matching Distillation (DMD) produces one-step generators that match their teacher in distribution, without enforcing a one-to-one correspondence with the sampling trajectories of their teachers. However, to ensure stable training, DMD requires an additional regression loss computed using a large set of noise-image pairs generated by the teacher with many steps of a deterministic sampler. This is costly for large-scale text-to-image synthesis and limits the student's quality, tying it too closely to the teacher's original sampling paths. We introduce DMD2, a set of techniques that lift this limitation and improve DMD training. First, we eliminate the regression loss and the need for expensive dataset construction. We show that the resulting instability is due to the fake critic not estimating the distribution of generated samples accurately and propose a two time-scale update rule as a remedy. Second, we integrate a GAN loss into the distillation procedure, discriminating between generated samples and real images. This lets us train the student model on real data, mitigating the imperfect real score estimation from the teacher model, and enhancing quality. Lastly, we modify the training procedure to enable multi-step sampling. We identify and address the training-inference input mismatch problem in this setting, by simulating inference-time generator samples during training time. Taken together, our improvements set new benchmarks in one-step image generation, with FID scores of 1.28 on ImageNet-64x64 and 8.35 on zero-shot COCO 2014, surpassing the original teacher despite a 500X reduction in inference cost. Further, we show our approach can generate megapixel images by distilling SDXL, demonstrating exceptional visual quality among few-step methods.
Create account to get full access
Overview
- Recent research has shown promise in developing efficient one-step generators by distilling diffusion models.
- Distribution Matching Distillation (DMD) is one such approach, which produces one-step generators that match their teacher in distribution, without enforcing a one-to-one correspondence with the teacher's sampling trajectories.
- However, DMD requires an additional regression loss computed using a large set of noise-image pairs generated by the teacher, which is costly and limits the student's quality.
Plain English Explanation
Diffusion models are a powerful type of machine learning model that can generate high-quality images. However, they tend to be slow and computationally expensive, as they involve multiple steps to generate an image. Researchers have been exploring ways to "distill" these diffusion models into more efficient one-step generators, which can generate images in a single step.
One such approach is Distribution Matching Distillation (DMD). DMD tries to create a one-step generator that matches the distribution of the images generated by the original diffusion model, without exactly replicating the original model's step-by-step process. This can result in a more efficient generator that still produces high-quality images.
However, to ensure stable training, DMD requires an additional regression loss, which is computed using a large set of noise-image pairs generated by the original diffusion model. This is a time-consuming and costly process, and it can also limit the quality of the final one-step generator, as it ties the student model too closely to the original model's sampling paths.
Technical Explanation
The paper introduces DMD2, a set of techniques that aim to address the limitations of the original DMD approach.
First, the authors eliminate the regression loss and the need for the expensive dataset construction. They find that the instability in the training process is due to the "fake critic" (the discriminator network) not accurately estimating the distribution of the generated samples. To address this, they propose using a two time-scale update rule, which helps the discriminator learn to better distinguish between real and generated samples.
Second, the authors integrate a GAN (Generative Adversarial Network) loss into the distillation procedure. This allows the student model to be trained on real data, rather than relying solely on the imperfect scores from the teacher model. This helps to enhance the quality of the generated images.
Finally, the authors modify the training procedure to enable multi-step sampling, where the student model can generate images in multiple steps, rather than a single step. To address the "training-inference input mismatch" problem in this setting, they simulate the inference-time generator samples during training time.
These improvements allow the authors to set new benchmarks in one-step image generation, with significantly improved FID (Fréchet Inception Distance) scores compared to the original teacher models, despite a 500X reduction in inference cost. The authors also demonstrate that their approach can be used to generate high-quality megapixel images by distilling the SDXL diffusion model.
Critical Analysis
The paper presents a compelling set of techniques for distilling efficient one-step generators from diffusion models. The elimination of the costly regression loss and the integration of the GAN loss are particularly interesting approaches that help to address the limitations of the original DMD method.
However, the paper does not fully address the potential issue of the student model being overly reliant on the teacher model's sampling paths, even with the reduced regression loss. There may still be a risk of the student model inheriting some of the biases or limitations of the teacher model, which could impact its long-term performance and generalization capabilities.
Additionally, the authors do not provide a thorough analysis of the computational and memory requirements of the DMD2 approach, which could be an important consideration for real-world applications, especially on resource-constrained devices.
Further research could explore ways to more effectively decouple the student model from the teacher model's specific sampling trajectories, potentially through the use of curriculum dataset distillation or other techniques. Investigating the scalability and robustness of the DMD2 approach on larger and more diverse datasets would also be valuable.
Conclusion
The DMD2 approach presented in this paper represents a significant advancement in the field of efficient one-step image generation from diffusion models. By eliminating the costly regression loss, integrating a GAN loss, and enabling multi-step sampling, the authors have developed a set of techniques that can produce high-quality images at a fraction of the computational cost of the original diffusion models.
This work has important implications for real-world applications, where computational efficiency and inference speed are critical, such as on mobile devices or in resource-constrained environments. The authors' ability to distill the powerful SDXL diffusion model into a fast, one-step generator is particularly impressive and demonstrates the potential of this approach.
Overall, the DMD2 paper represents a significant step forward in the development of efficient image generation models, and the techniques presented could have far-reaching impacts on a wide range of applications, from creative tools to autonomous systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Regularized Distribution Matching Distillation for One-step Unpaired Image-to-Image Translation
Denis Rakitin, Ivan Shchekotov, Dmitry Vetrov
0
0
Diffusion distillation methods aim to compress the diffusion models into efficient one-step generators while trying to preserve quality. Among them, Distribution Matching Distillation (DMD) offers a suitable framework for training general-form one-step generators, applicable beyond unconditional generation. In this work, we introduce its modification, called Regularized Distribution Matching Distillation, applicable to unpaired image-to-image (I2I) problems. We demonstrate its empirical performance in application to several translation tasks, including 2D examples and I2I between different image datasets, where it performs on par or better than multi-step diffusion baselines.
6/24/2024
Diffusion Models Are Innate One-Step Generators
Bowen Zheng, Tianming Yang
0
0
Diffusion Models (DMs) have achieved great success in image generation and other fields. By fine sampling through the trajectory defined by the SDE/ODE solver based on a well-trained score model, DMs can generate remarkable high-quality results. However, this precise sampling often requires multiple steps and is computationally demanding. To address this problem, instance-based distillation methods have been proposed to distill a one-step generator from a DM by having a simpler student model mimic a more complex teacher model. Yet, our research reveals an inherent limitations in these methods: the teacher model, with more steps and more parameters, occupies different local minima compared to the student model, leading to suboptimal performance when the student model attempts to replicate the teacher. To avoid this problem, we introduce a novel distributional distillation method, which uses an exclusive distributional loss. This method exceeds state-of-the-art (SOTA) results while requiring significantly fewer training images. Additionally, we show that DMs' layers are differentially activated at different time steps, leading to an inherent capability to generate images in a single step. Freezing most of the convolutional layers in a DM during distributional distillation enables this innate capability and leads to further performance improvements. Our method achieves the SOTA results on CIFAR-10 (FID 1.54), AFHQv2 64x64 (FID 1.23), FFHQ 64x64 (FID 0.85) and ImageNet 64x64 (FID 1.16) with great efficiency. Most of those results are obtained with only 5 million training images within 6 hours on 8 A100 GPUs.
6/10/2024

SFDDM: Single-fold Distillation for Diffusion models
Chi Hong, Jiyue Huang, Robert Birke, Dick Epema, Stefanie Roos, Lydia Y. Chen
0
0
While diffusion models effectively generate remarkable synthetic images, a key limitation is the inference inefficiency, requiring numerous sampling steps. To accelerate inference and maintain high-quality synthesis, teacher-student distillation is applied to compress the diffusion models in a progressive and binary manner by retraining, e.g., reducing the 1024-step model to a 128-step model in 3 folds. In this paper, we propose a single-fold distillation algorithm, SFDDM, which can flexibly compress the teacher diffusion model into a student model of any desired step, based on reparameterization of the intermediate inputs from the teacher model. To train the student diffusion, we minimize not only the output distance but also the distribution of the hidden variables between the teacher and student model. Extensive experiments on four datasets demonstrate that our student model trained by the proposed SFDDM is able to sample high-quality data with steps reduced to as little as approximately 1%, thus, trading off inference time. Our remarkable performance highlights that SFDDM effectively transfers knowledge in single-fold distillation, achieving semantic consistency and meaningful image interpolation.
5/27/2024
📉
Distilling Diffusion Models into Conditional GANs
Minguk Kang, Richard Zhang, Connelly Barnes, Sylvain Paris, Suha Kwak, Jaesik Park, Eli Shechtman, Jun-Yan Zhu, Taesung Park
0
0
We propose a method to distill a complex multistep diffusion model into a single-step conditional GAN student model, dramatically accelerating inference, while preserving image quality. Our approach interprets diffusion distillation as a paired image-to-image translation task, using noise-to-image pairs of the diffusion model's ODE trajectory. For efficient regression loss computation, we propose E-LatentLPIPS, a perceptual loss operating directly in diffusion model's latent space, utilizing an ensemble of augmentations. Furthermore, we adapt a diffusion model to construct a multi-scale discriminator with a text alignment loss to build an effective conditional GAN-based formulation. E-LatentLPIPS converges more efficiently than many existing distillation methods, even accounting for dataset construction costs. We demonstrate that our one-step generator outperforms cutting-edge one-step diffusion distillation models -- DMD, SDXL-Turbo, and SDXL-Lightning -- on the zero-shot COCO benchmark.
6/17/2024