On Improving the Algorithm-, Model-, and Data- Efficiency of Self-Supervised Learning
2404.19289
0
0
🔮
Abstract
Self-supervised learning (SSL) has developed rapidly in recent years. However, most of the mainstream methods are computationally expensive and rely on two (or more) augmentations for each image to construct positive pairs. Moreover, they mainly focus on large models and large-scale datasets, which lack flexibility and feasibility in many practical applications. In this paper, we propose an efficient single-branch SSL method based on non-parametric instance discrimination, aiming to improve the algorithm, model, and data efficiency of SSL. By analyzing the gradient formula, we correct the update rule of the memory bank with improved performance. We further propose a novel self-distillation loss that minimizes the KL divergence between the probability distribution and its square root version. We show that this alleviates the infrequent updating problem in instance discrimination and greatly accelerates convergence. We systematically compare the training overhead and performance of different methods in different scales of data, and under different backbones. Experimental results show that our method outperforms various baselines with significantly less overhead, and is especially effective for limited amounts of data and small models.
Create account to get full access
Overview
- This paper proposes an efficient single-branch self-supervised learning (SSL) method based on non-parametric instance discrimination, aiming to improve the algorithm, model, and data efficiency of SSL.
- The method corrects the update rule of the memory bank and introduces a novel self-distillation loss that minimizes the KL divergence between the probability distribution and its square root version.
- The authors systematically compare the training overhead and performance of their method against various baselines across different data scales and model backbones.
Plain English Explanation
Self-supervised learning (SSL) is a powerful technique for training machine learning models without the need for labeled data. However, many popular SSL methods can be computationally expensive and rely on complex data augmentation strategies. This paper presents a more efficient SSL approach that addresses these challenges.
At the core of the proposed method is a technique called "non-parametric instance discrimination." This means the model learns to distinguish between individual data samples (e.g., images) without using any trainable parameters to do so. The authors make two key improvements to this approach:
-
Corrected Memory Bank Update: They analyze the mathematical formulas behind the training process and modify the way the model updates its "memory bank" of past representations, which leads to better performance.
-
Self-Distillation Loss: They introduce a novel loss function that encourages the model to learn a "square root" version of the probability distribution over data samples. This helps address a problem called "infrequent updating" that can slow down the learning process.
The authors show that their method outperforms various baseline SSL approaches, particularly when working with limited data or smaller models. This makes it a promising technique for self-supervised learning featuring small-scale image datasets and can we break free from strong data dependencies.
Technical Explanation
The core of the proposed method is a non-parametric instance discrimination approach, where the model learns to distinguish between individual data samples without using any trainable parameters. This is achieved by maintaining a "memory bank" that stores representations of past data samples.
The authors analyze the gradient formula used to update the memory bank and identify an issue that can lead to suboptimal performance. They correct this by modifying the update rule, which improves the method's overall effectiveness.
To further enhance the learning process, the authors introduce a novel "self-distillation" loss function. This loss minimizes the Kullback-Leibler (KL) divergence between the probability distribution over data samples and its square root version. This helps address a problem called "infrequent updating," where certain data samples are not updated as frequently during training, by encouraging the model to learn a more balanced representation of the data.
The authors conduct a systematic evaluation of their method, comparing its training overhead and performance against various baselines across different data scales and model backbones. They demonstrate that their approach outperforms the alternatives, especially when working with limited data or smaller models, making it a promising technique for self-supervised dataset distillation transfer learning, hypergraph self-supervised learning sampling efficient signals, and semantic positive pairs enhancing visual representation learning.
Critical Analysis
The authors provide a thorough evaluation of their method, demonstrating its effectiveness across a range of data scales and model sizes. However, the paper does not address certain limitations or potential issues that could be explored in future research.
For example, the authors do not discuss the scalability of their approach to very large-scale datasets or the potential impact of the memory bank size on performance. Additionally, while the self-distillation loss is shown to be beneficial, the underlying reasons for its efficacy could be further explored.
It would also be interesting to see how the proposed method compares to other state-of-the-art SSL techniques, such as those based on contrastive learning or generative models, in terms of both performance and computational efficiency.
Overall, the paper presents a promising approach to improving the efficiency and effectiveness of self-supervised learning, and it encourages readers to think critically about the trade-offs and potential avenues for further research in this rapidly evolving field.
Conclusion
This paper introduces an efficient single-branch self-supervised learning method that addresses some of the key challenges in mainstream SSL approaches. By correcting the memory bank update rule and introducing a novel self-distillation loss, the authors demonstrate significant improvements in both training overhead and performance, especially when working with limited data or smaller models.
The proposed technique is a valuable contribution to the ongoing efforts to make self-supervised learning more accessible and practical for a wider range of applications, beyond the usual focus on large-scale datasets and models. As the field of self-supervised learning continues to evolve, this work highlights the importance of exploring efficient and flexible approaches that can unlock the potential of SSL in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
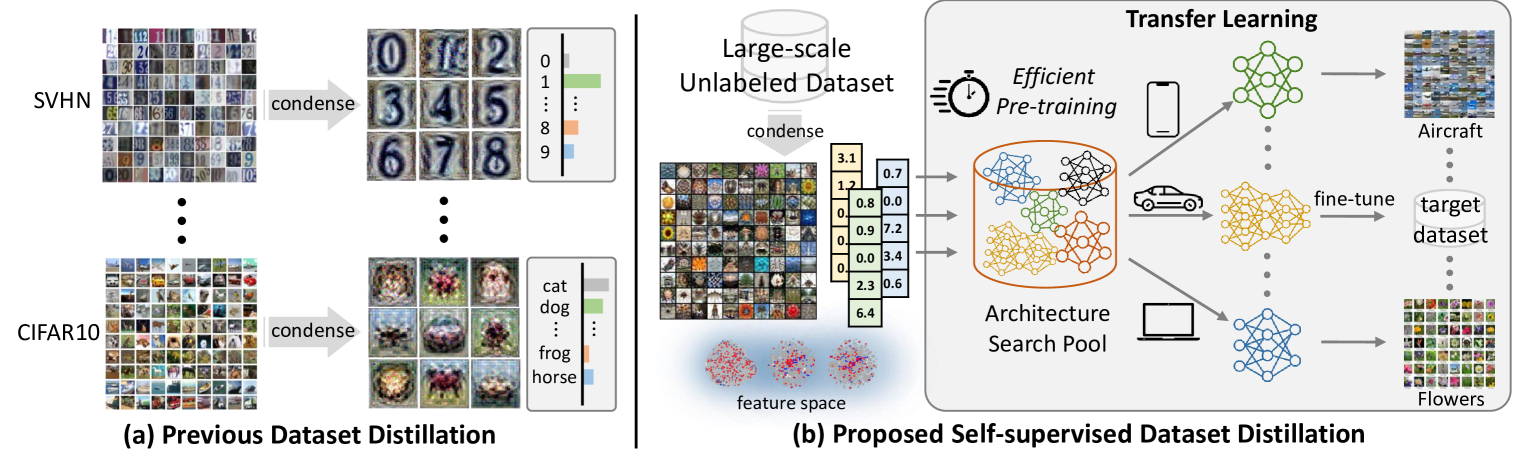
Self-Supervised Dataset Distillation for Transfer Learning
Dong Bok Lee, Seanie Lee, Joonho Ko, Kenji Kawaguchi, Juho Lee, Sung Ju Hwang
0
0
Dataset distillation methods have achieved remarkable success in distilling a large dataset into a small set of representative samples. However, they are not designed to produce a distilled dataset that can be effectively used for facilitating self-supervised pre-training. To this end, we propose a novel problem of distilling an unlabeled dataset into a set of small synthetic samples for efficient self-supervised learning (SSL). We first prove that a gradient of synthetic samples with respect to a SSL objective in naive bilevel optimization is textit{biased} due to the randomness originating from data augmentations or masking. To address this issue, we propose to minimize the mean squared error (MSE) between a model's representations of the synthetic examples and their corresponding learnable target feature representations for the inner objective, which does not introduce any randomness. Our primary motivation is that the model obtained by the proposed inner optimization can mimic the textit{self-supervised target model}. To achieve this, we also introduce the MSE between representations of the inner model and the self-supervised target model on the original full dataset for outer optimization. Lastly, assuming that a feature extractor is fixed, we only optimize a linear head on top of the feature extractor, which allows us to reduce the computational cost and obtain a closed-form solution of the head with kernel ridge regression. We empirically validate the effectiveness of our method on various applications involving transfer learning.
4/15/2024
Can We Break Free from Strong Data Augmentations in Self-Supervised Learning?
Shruthi Gowda, Elahe Arani, Bahram Zonooz
0
0
Self-supervised learning (SSL) has emerged as a promising solution for addressing the challenge of limited labeled data in deep neural networks (DNNs), offering scalability potential. However, the impact of design dependencies within the SSL framework remains insufficiently investigated. In this study, we comprehensively explore SSL behavior across a spectrum of augmentations, revealing their crucial role in shaping SSL model performance and learning mechanisms. Leveraging these insights, we propose a novel learning approach that integrates prior knowledge, with the aim of curtailing the need for extensive data augmentations and thereby amplifying the efficacy of learned representations. Notably, our findings underscore that SSL models imbued with prior knowledge exhibit reduced texture bias, diminished reliance on shortcuts and augmentations, and improved robustness against both natural and adversarial corruptions. These findings not only illuminate a new direction in SSL research, but also pave the way for enhancing DNN performance while concurrently alleviating the imperative for intensive data augmentation, thereby enhancing scalability and real-world problem-solving capabilities.
4/16/2024
👀
Weak Augmentation Guided Relational Self-Supervised Learning
Mingkai Zheng, Shan You, Fei Wang, Chen Qian, Changshui Zhang, Xiaogang Wang, Chang Xu
0
0
Self-supervised Learning (SSL) including the mainstream contrastive learning has achieved great success in learning visual representations without data annotations. However, most methods mainly focus on the instance level information (ie, the different augmented images of the same instance should have the same feature or cluster into the same class), but there is a lack of attention on the relationships between different instances. In this paper, we introduce a novel SSL paradigm, which we term as relational self-supervised learning (ReSSL) framework that learns representations by modeling the relationship between different instances. Specifically, our proposed method employs sharpened distribution of pairwise similarities among different instances as textit{relation} metric, which is thus utilized to match the feature embeddings of different augmentations. To boost the performance, we argue that weak augmentations matter to represent a more reliable relation, and leverage momentum strategy for practical efficiency. The designed asymmetric predictor head and an InfoNCE warm-up strategy enhance the robustness to hyper-parameters and benefit the resulting performance. Experimental results show that our proposed ReSSL substantially outperforms the state-of-the-art methods across different network architectures, including various lightweight networks (eg, EfficientNet and MobileNet).
6/4/2024

Hypergraph Self-supervised Learning with Sampling-efficient Signals
Fan Li, Xiaoyang Wang, Dawei Cheng, Wenjie Zhang, Ying Zhang, Xuemin Lin
0
0
Self-supervised learning (SSL) provides a promising alternative for representation learning on hypergraphs without costly labels. However, existing hypergraph SSL models are mostly based on contrastive methods with the instance-level discrimination strategy, suffering from two significant limitations: (1) They select negative samples arbitrarily, which is unreliable in deciding similar and dissimilar pairs, causing training bias. (2) They often require a large number of negative samples, resulting in expensive computational costs. To address the above issues, we propose SE-HSSL, a hypergraph SSL framework with three sampling-efficient self-supervised signals. Specifically, we introduce two sampling-free objectives leveraging the canonical correlation analysis as the node-level and group-level self-supervised signals. Additionally, we develop a novel hierarchical membership-level contrast objective motivated by the cascading overlap relationship in hypergraphs, which can further reduce membership sampling bias and improve the efficiency of sample utilization. Through comprehensive experiments on 7 real-world hypergraphs, we demonstrate the superiority of our approach over the state-of-the-art method in terms of both effectiveness and efficiency.
4/19/2024