Improving Detection in Aerial Images by Capturing Inter-Object Relationships
2404.04140
0
0

Abstract
In many image domains, the spatial distribution of objects in a scene exhibits meaningful patterns governed by their semantic relationships. In most modern detection pipelines, however, the detection proposals are processed independently, overlooking the underlying relationships between objects. In this work, we introduce a transformer-based approach to capture these inter-object relationships to refine classification and regression outcomes for detected objects. Building on two-stage detectors, we tokenize the region of interest (RoI) proposals to be processed by a transformer encoder. Specific spatial and geometric relations are incorporated into the attention weights and adaptively modulated and regularized. Experimental results demonstrate that the proposed method achieves consistent performance improvement on three benchmarks including DOTA-v1.0, DOTA-v1.5, and HRSC 2016, especially ranking first on both DOTA-v1.5 and HRSC 2016. Specifically, our new method has an increase of 1.59 mAP on DOTA-v1.0, 4.88 mAP on DOTA-v1.5, and 2.1 mAP on HRSC 2016, respectively, compared to the baselines.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a method for improving object detection in aerial images by leveraging the relationships between objects.
- The researchers develop a novel neural network architecture that can capture and utilize the spatial and semantic inter-object relationships to enhance detection performance.
- Experiments on several aerial image datasets demonstrate the effectiveness of the proposed approach compared to state-of-the-art object detection methods.
Plain English Explanation
When analyzing aerial images, such as those taken from drones or satellites, accurately detecting and identifying the objects within the scene is a crucial task. This paper presents a new technique to improve the performance of object detection in these types of images.
The key insight is that the relationships between different objects in the image can provide valuable information to aid the detection process. For example, if the system knows that a car is typically located near a road, this contextual knowledge can help confirm the presence of the car and improve the overall detection accuracy.
The researchers develop a specialized neural network architecture that is designed to capture these inter-object relationships, both in terms of the spatial arrangement of the objects as well as the semantic connections between them. By incorporating this relational information, the detection model can make more informed and accurate predictions about the objects present in the image.
Through experiments on several benchmark aerial image datasets, the authors demonstrate that their proposed approach outperforms other state-of-the-art object detection methods. This suggests that leveraging the inherent relationships between objects in an image can be a powerful technique for enhancing computer vision tasks, especially in complex environments like aerial scenes.
Technical Explanation
The paper proposes a novel neural network architecture, called the Relation-Aware Object Detector (RAOD), to improve object detection in aerial images. The key innovation is the incorporation of inter-object relationships into the detection process.
The RAOD model consists of several main components:
- Feature Extraction: A backbone convolutional neural network (CNN) extracts visual features from the input aerial image.
- Region Proposal Network: This module generates candidate bounding boxes that may contain objects of interest.
- Relation Modeling: A specialized relation modeling network learns to capture the spatial and semantic relationships between the proposed object regions.
- Relation-Aware Classification and Regression: The final detection outputs (class labels and bounding box coordinates) are predicted using the relational information in addition to the visual features.
The relation modeling network uses a Graph Convolutional Network (GCN) to encode the connections between object proposals. This allows the model to reason about how the objects are arranged and related to each other, which complements the individual object appearance features.
The authors evaluate the RAOD model on several aerial image datasets, including DIOR and HRSC2016. The results demonstrate consistent improvements in object detection performance compared to baseline methods that do not consider inter-object relationships.
Critical Analysis
The proposed RAOD approach represents a promising direction for enhancing object detection in aerial imagery by leveraging the contextual cues provided by inter-object relationships. However, the paper does not extensively discuss the limitations of the technique or potential challenges that may arise in real-world deployment.
One area that could be explored further is the robustness of the RAOD model to variations in the aerial scene, such as changes in viewpoint, occlusions, or differences in object density and distribution. The authors only evaluate their method on a few selected benchmark datasets, and it would be valuable to understand how well it generalizes to more diverse and challenging aerial image scenarios.
Additionally, the computational complexity of the relation modeling component may be a concern, especially for real-time applications that require fast inference. The authors do not provide detailed analysis of the model's runtime performance or discuss potential optimization strategies.
Another aspect that could be investigated is the transferability of the learned relational representations to other aerial image understanding tasks beyond object detection, such as scene understanding or activity recognition. Exploring these broader applications could further highlight the value of the proposed relational modeling approach.
Conclusion
This paper introduces a novel object detection method for aerial images that effectively captures and utilizes the spatial and semantic relationships between objects in the scene. The proposed Relation-Aware Object Detector (RAOD) architecture demonstrates superior performance compared to state-of-the-art techniques on several benchmark datasets.
The key contribution of this work is the insight that incorporating inter-object relationships can significantly improve the accuracy of object detection in complex aerial environments. By modeling these contextual cues, the RAOD model is able to make more informed predictions about the presence and location of objects of interest.
The findings of this research highlight the potential of leveraging relational reasoning for advancing computer vision tasks, particularly in domains where the spatial and semantic connections between objects play a crucial role. As aerial imagery continues to be an essential tool for various applications, such as urban planning, disaster response, and environmental monitoring, techniques like RAOD could have a significant impact on improving the reliability and effectiveness of object detection in these critical real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

GraphRelate3D: Context-Dependent 3D Object Detection with Inter-Object Relationship Graphs
Mingyu Liu, Ekim Yurtsever, Marc Brede, Jun Meng, Walter Zimmer, Xingcheng Zhou, Bare Luka Zagar, Yuning Cui, Alois Knoll
0
0
Accurate and effective 3D object detection is critical for ensuring the driving safety of autonomous vehicles. Recently, state-of-the-art two-stage 3D object detectors have exhibited promising performance. However, these methods refine proposals individually, ignoring the rich contextual information in the object relationships between the neighbor proposals. In this study, we introduce an object relation module, consisting of a graph generator and a graph neural network (GNN), to learn the spatial information from certain patterns to improve 3D object detection. Specifically, we create an inter-object relationship graph based on proposals in a frame via the graph generator to connect each proposal with its neighbor proposals. Afterward, the GNN module extracts edge features from the generated graph and iteratively refines proposal features with the captured edge features. Ultimately, we leverage the refined features as input to the detection head to obtain detection results. Our approach improves upon the baseline PV-RCNN on the KITTI validation set for the car class across easy, moderate, and hard difficulty levels by 0.82%, 0.74%, and 0.58%, respectively. Additionally, our method outperforms the baseline by more than 1% under the moderate and hard levels BEV AP on the test server.
5/14/2024
🔎
Hierarchical Point Attention for Indoor 3D Object Detection
Manli Shu, Le Xue, Ning Yu, Roberto Mart'in-Mart'in, Caiming Xiong, Tom Goldstein, Juan Carlos Niebles, Ran Xu
0
0
3D object detection is an essential vision technique for various robotic systems, such as augmented reality and domestic robots. Transformers as versatile network architectures have recently seen great success in 3D point cloud object detection. However, the lack of hierarchy in a plain transformer restrains its ability to learn features at different scales. Such limitation makes transformer detectors perform worse on smaller objects and affects their reliability in indoor environments where small objects are the majority. This work proposes two novel attention operations as generic hierarchical designs for point-based transformer detectors. First, we propose Aggregated Multi-Scale Attention (MS-A) that builds multi-scale tokens from a single-scale input feature to enable more fine-grained feature learning. Second, we propose Size-Adaptive Local Attention (Local-A) with adaptive attention regions for localized feature aggregation within bounding box proposals. Both attention operations are model-agnostic network modules that can be plugged into existing point cloud transformers for end-to-end training. We evaluate our method on two widely used indoor detection benchmarks. By plugging our proposed modules into the state-of-the-art transformer-based 3D detectors, we improve the previous best results on both benchmarks, with more significant improvements on smaller objects.
5/10/2024
Representation Alignment Contrastive Regularization for Multi-Object Tracking
Shujie Chen, Zhonglin Liu, Jianfeng Dong, Di Zhou
0
0
Achieving high-performance in multi-object tracking algorithms heavily relies on modeling spatio-temporal relationships during the data association stage. Mainstream approaches encompass rule-based and deep learning-based methods for spatio-temporal relationship modeling. While the former relies on physical motion laws, offering wider applicability but yielding suboptimal results for complex object movements, the latter, though achieving high-performance, lacks interpretability and involves complex module designs. This work aims to simplify deep learning-based spatio-temporal relationship models and introduce interpretability into features for data association. Specifically, a lightweight single-layer transformer encoder is utilized to model spatio-temporal relationships. To make features more interpretative, two contrastive regularization losses based on representation alignment are proposed, derived from spatio-temporal consistency rules. By applying weighted summation to affinity matrices, the aligned features can seamlessly integrate into the data association stage of the original tracking workflow. Experimental results showcase that our model enhances the majority of existing tracking networks' performance without excessive complexity, with minimal increase in training overhead and nearly negligible computational and storage costs.
4/4/2024
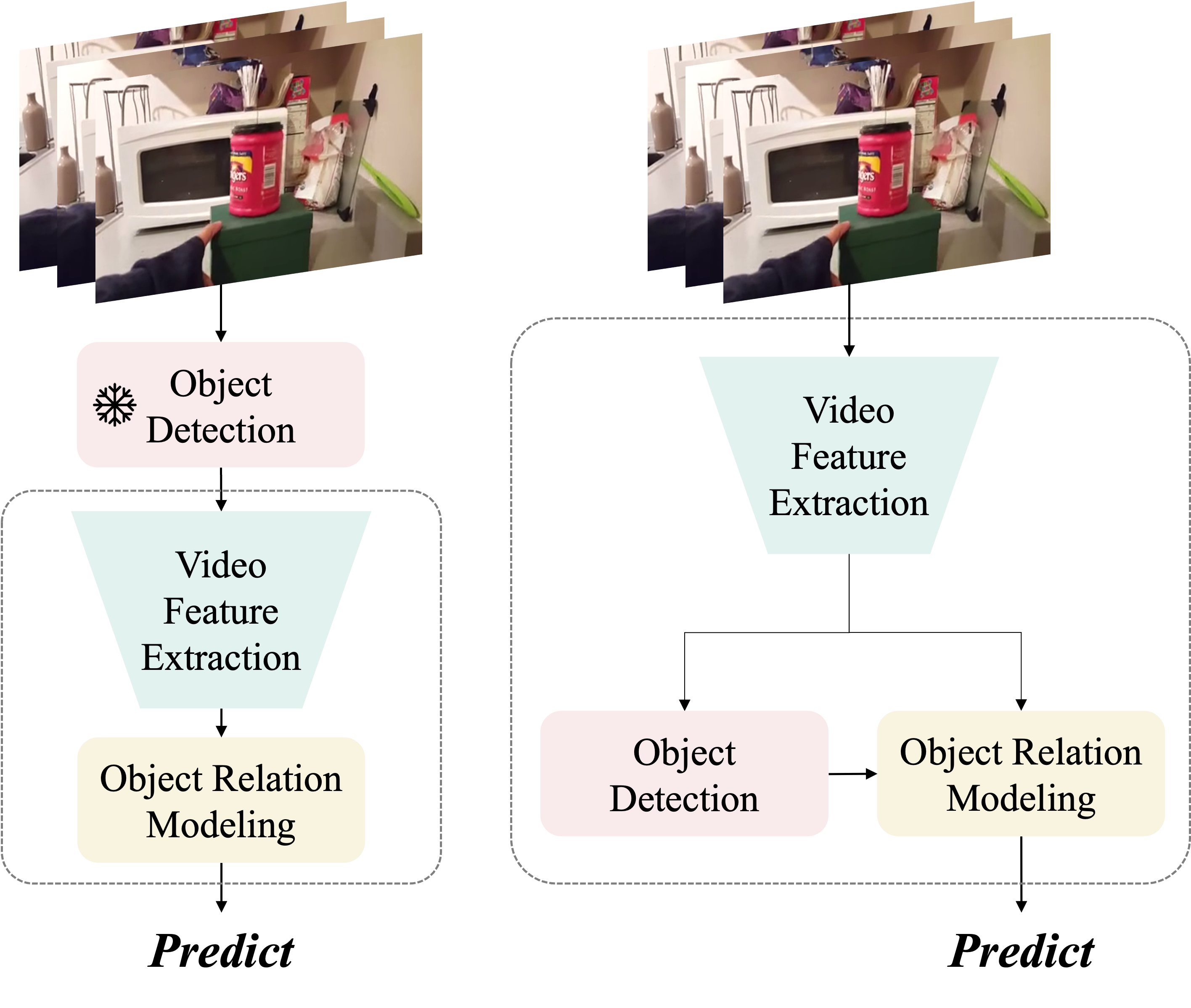
Simultaneous Detection and Interaction Reasoning for Object-Centric Action Recognition
Xunsong Li, Pengzhan Sun, Yangcen Liu, Lixin Duan, Wen Li
0
0
The interactions between human and objects are important for recognizing object-centric actions. Existing methods usually adopt a two-stage pipeline, where object proposals are first detected using a pretrained detector, and then are fed to an action recognition model for extracting video features and learning the object relations for action recognition. However, since the action prior is unknown in the object detection stage, important objects could be easily overlooked, leading to inferior action recognition performance. In this paper, we propose an end-to-end object-centric action recognition framework that simultaneously performs Detection And Interaction Reasoning in one stage. Particularly, after extracting video features with a base network, we create three modules for concurrent object detection and interaction reasoning. First, a Patch-based Object Decoder generates proposals from video patch tokens. Then, an Interactive Object Refining and Aggregation identifies important objects for action recognition, adjusts proposal scores based on position and appearance, and aggregates object-level info into a global video representation. Lastly, an Object Relation Modeling module encodes object relations. These three modules together with the video feature extractor can be trained jointly in an end-to-end fashion, thus avoiding the heavy reliance on an off-the-shelf object detector, and reducing the multi-stage training burden. We conduct experiments on two datasets, Something-Else and Ikea-Assembly, to evaluate the performance of our proposed approach on conventional, compositional, and few-shot action recognition tasks. Through in-depth experimental analysis, we show the crucial role of interactive objects in learning for action recognition, and we can outperform state-of-the-art methods on both datasets.
4/19/2024