Improving GFlowNets for Text-to-Image Diffusion Alignment
2406.00633
0
0

Abstract
Diffusion models have become the de-facto approach for generating visual data, which are trained to match the distribution of the training dataset. In addition, we also want to control generation to fulfill desired properties such as alignment to a text description, which can be specified with a black-box reward function. Prior works fine-tune pretrained diffusion models to achieve this goal through reinforcement learning-based algorithms. Nonetheless, they suffer from issues including slow credit assignment as well as low quality in their generated samples. In this work, we explore techniques that do not directly maximize the reward but rather generate high-reward images with relatively high probability -- a natural scenario for the framework of generative flow networks (GFlowNets). To this end, we propose the Diffusion Alignment with GFlowNet (DAG) algorithm to post-train diffusion models with black-box property functions. Extensive experiments on Stable Diffusion and various reward specifications corroborate that our method could effectively align large-scale text-to-image diffusion models with given reward information.
Create account to get full access
Overview
- This paper explores improvements to GFlowNets, a type of neural network, to better align text-to-image diffusion models.
- Diffusion models are a powerful class of machine learning models that can generate high-quality images from text descriptions.
- GFlowNets are a novel type of neural network that can learn to sample from complex distributions, making them useful for tasks like text-to-image generation.
Plain English Explanation
GFlowNets are a type of AI model that can learn to generate complex outputs, like images, from simpler inputs, like text descriptions. This paper looks at ways to make GFlowNets better at aligning the text and images they produce, so the images match the text more closely.
Diffusion models are another type of AI model that can also generate images from text, but they work in a different way. This paper explores how to combine the strengths of GFlowNets and diffusion models to get the best of both approaches.
The key idea is to use the diffusion model to guide the training of the GFlowNet, so it learns to generate images that are well-aligned with the input text. This helps the GFlowNet produce more realistic and coherent images that match the text description.
Technical Explanation
The paper proposes several improvements to GFlowNets to enhance their performance on text-to-image diffusion alignment tasks:
-
Guided Exploration: The authors introduce a "guided exploration" mechanism that uses the gradients from a pre-trained diffusion model to guide the GFlowNet's search for valid sequences of actions that produce high-quality images. This helps the GFlowNet focus on regions of the search space that are more likely to generate images that align well with the text.
-
Contrastive Objective: The paper also presents a novel contrastive objective function that encourages the GFlowNet to generate images that are more similar to the ground-truth images corresponding to the input text, while also being dissimilar to images generated for other text inputs.
-
Learned Transition Probabilities: Finally, the authors propose learning the transition probabilities in the GFlowNet instead of using fixed values, which can help the model better capture the complex dependencies between the successive actions it takes to generate an image.
The authors evaluate their proposed techniques on several text-to-image generation benchmarks and demonstrate significant improvements in alignment and image quality compared to previous GFlowNet approaches.
Critical Analysis
The paper provides a compelling approach for enhancing GFlowNets to better align the generated images with the input text. The use of guidance from a pre-trained diffusion model and the contrastive objective function are well-motivated and seem to yield tangible benefits.
One potential limitation is the reliance on a pre-trained diffusion model, which may limit the flexibility and end-to-end trainability of the overall system. It would be interesting to see if the techniques could be extended to a more tightly integrated approach where the diffusion model and GFlowNet are trained jointly.
Additionally, the paper does not discuss the computational complexity or training time of the proposed methods, which could be an important practical consideration, especially for real-world applications.
Conclusion
This paper presents a promising approach for improving the text-to-image alignment capabilities of GFlowNets, a powerful class of generative models. By leveraging insights from diffusion models and introducing novel training objectives and architectural choices, the authors demonstrate significant advancements in the quality and coherence of the images generated by GFlowNets.
These improvements have the potential to enhance the usefulness of GFlowNets for a wide range of applications, such as text-to-image generation, molecular optimization, and preference-based optimization. The techniques may also be applicable to improving the efficiency of training GANs and other generative models. Overall, this research represents an important step forward in the field of text-to-image alignment and generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
Aligning Text-to-Image Diffusion Models with Reward Backpropagation
Mihir Prabhudesai, Anirudh Goyal, Deepak Pathak, Katerina Fragkiadaki
0
0
Text-to-image diffusion models have recently emerged at the forefront of image generation, powered by very large-scale unsupervised or weakly supervised text-to-image training datasets. Due to their unsupervised training, controlling their behavior in downstream tasks, such as maximizing human-perceived image quality, image-text alignment, or ethical image generation, is difficult. Recent works finetune diffusion models to downstream reward functions using vanilla reinforcement learning, notorious for the high variance of the gradient estimators. In this paper, we propose AlignProp, a method that aligns diffusion models to downstream reward functions using end-to-end backpropagation of the reward gradient through the denoising process. While naive implementation of such backpropagation would require prohibitive memory resources for storing the partial derivatives of modern text-to-image models, AlignProp finetunes low-rank adapter weight modules and uses gradient checkpointing, to render its memory usage viable. We test AlignProp in finetuning diffusion models to various objectives, such as image-text semantic alignment, aesthetics, compressibility and controllability of the number of objects present, as well as their combinations. We show AlignProp achieves higher rewards in fewer training steps than alternatives, while being conceptually simpler, making it a straightforward choice for optimizing diffusion models for differentiable reward functions of interest. Code and Visualization results are available at https://align-prop.github.io/.
6/26/2024
🖼️
Enhancing Image Layout Control with Loss-Guided Diffusion Models
Zakaria Patel, Kirill Serkh
0
0
Diffusion models are a powerful class of generative models capable of producing high-quality images from pure noise. In particular, conditional diffusion models allow one to specify the contents of the desired image using a simple text prompt. Conditioning on a text prompt alone, however, does not allow for fine-grained control over the composition and layout of the final image, which instead depends closely on the initial noise distribution. While most methods which introduce spatial constraints (e.g., bounding boxes) require fine-tuning, a smaller and more recent subset of these methods are training-free. They are applicable whenever the prompt influences the model through an attention mechanism, and generally fall into one of two categories. The first entails modifying the cross-attention maps of specific tokens directly to enhance the signal in certain regions of the image. The second works by defining a loss function over the cross-attention maps, and using the gradient of this loss to guide the latent. While previous work explores these as alternative strategies, we provide an interpretation for these methods which highlights their complimentary features, and demonstrate that it is possible to obtain superior performance when both methods are used in concert.
5/24/2024
🔗
A Dense Reward View on Aligning Text-to-Image Diffusion with Preference
Shentao Yang, Tianqi Chen, Mingyuan Zhou
0
0
Aligning text-to-image diffusion model (T2I) with preference has been gaining increasing research attention. While prior works exist on directly optimizing T2I by preference data, these methods are developed under the bandit assumption of a latent reward on the entire diffusion reverse chain, while ignoring the sequential nature of the generation process. This may harm the efficacy and efficiency of preference alignment. In this paper, we take on a finer dense reward perspective and derive a tractable alignment objective that emphasizes the initial steps of the T2I reverse chain. In particular, we introduce temporal discounting into DPO-style explicit-reward-free objectives, to break the temporal symmetry therein and suit the T2I generation hierarchy. In experiments on single and multiple prompt generation, our method is competitive with strong relevant baselines, both quantitatively and qualitatively. Further investigations are conducted to illustrate the insight of our approach.
5/14/2024
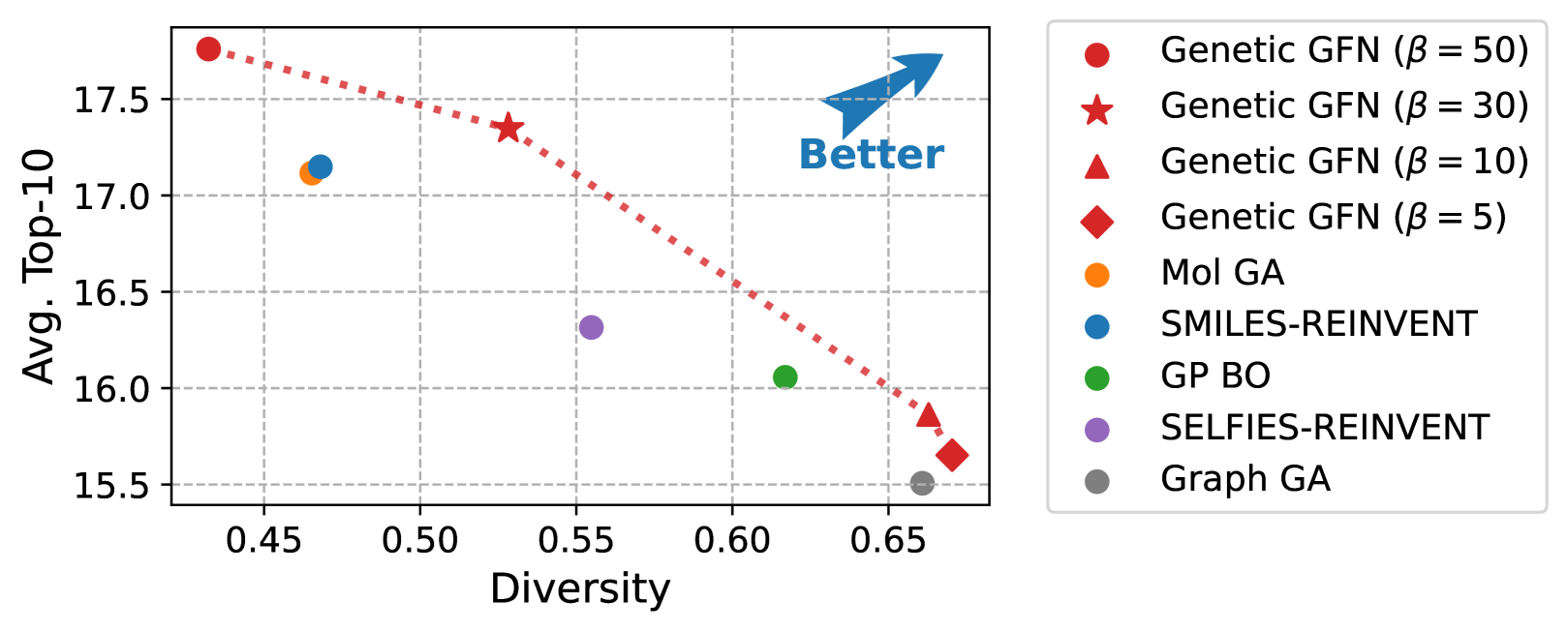
Genetic-guided GFlowNets for Sample Efficient Molecular Optimization
Hyeonah Kim, Minsu Kim, Sanghyeok Choi, Jinkyoo Park
0
0
The challenge of discovering new molecules with desired properties is crucial in domains like drug discovery and material design. Recent advances in deep learning-based generative methods have shown promise but face the issue of sample efficiency due to the computational expense of evaluating the reward function. This paper proposes a novel algorithm for sample-efficient molecular optimization by distilling a powerful genetic algorithm into deep generative policy using GFlowNets training, the off-policy method for amortized inference. This approach enables the deep generative policy to learn from domain knowledge, which has been explicitly integrated into the genetic algorithm. Our method achieves state-of-the-art performance in the official molecular optimization benchmark, significantly outperforming previous methods. It also demonstrates effectiveness in designing inhibitors against SARS-CoV-2 with substantially fewer reward calls.
5/28/2024