An Invisible Backdoor Attack Based On Semantic Feature
2405.11551
0
0

Abstract
Backdoor attacks have severely threatened deep neural network (DNN) models in the past several years. These attacks can occur in almost every stage of the deep learning pipeline. Although the attacked model behaves normally on benign samples, it makes wrong predictions for samples containing triggers. However, most existing attacks use visible patterns (e.g., a patch or image transformations) as triggers, which are vulnerable to human inspection. In this paper, we propose a novel backdoor attack, making imperceptible changes. Concretely, our attack first utilizes the pre-trained victim model to extract low-level and high-level semantic features from clean images and generates trigger pattern associated with high-level features based on channel attention. Then, the encoder model generates poisoned images based on the trigger and extracted low-level semantic features without causing noticeable feature loss. We evaluate our attack on three prominent image classification DNN across three standard datasets. The results demonstrate that our attack achieves high attack success rates while maintaining robustness against backdoor defenses. Furthermore, we conduct extensive image similarity experiments to emphasize the stealthiness of our attack strategy.
Create account to get full access
Overview
- Introduces a new type of backdoor attack on deep neural networks based on manipulating semantic features
- Demonstrates the attack on object detection and semantic segmentation models
- Proposes a defense mechanism to detect and mitigate such attacks
Plain English Explanation
Backdoor attacks are a type of security vulnerability in machine learning models where an attacker can cause the model to make specific mistakes, even on benign inputs. This paper describes a new kind of backdoor attack that focuses on manipulating the model's understanding of semantic features, rather than just adding visually noticeable triggers.
The key idea is that the attacker can subtly alter the semantic features - the high-level concepts and meanings learned by the model - in a way that doesn't change the actual appearance of the input. This makes the attack very hard to detect, since there are no obvious signs that something has been tampered with. The attacker can then cause the model to make mistakes on certain targeted inputs by exploiting this backdoor.
The researchers demonstrate this attack on both object detection and semantic segmentation models, showing how it can be used to, for example, make a model fail to correctly identify stop signs or misclassify buildings. They also propose a defense mechanism that can help detect and mitigate these semantic feature-based backdoor attacks.
Overall, this work highlights a new and concerning type of security vulnerability in modern AI systems, and the importance of developing robust defenses against increasingly sophisticated attacks.
Technical Explanation
The paper introduces a new type of backdoor attack called a "semantic feature-based backdoor attack," which manipulates the high-level semantic features learned by deep neural networks instead of just adding visually noticeable triggers. The key idea is to craft a specially crafted "semantic backdoor" that can cause the model to make targeted mistakes, even on benign inputs.
The researchers first propose a general framework for this type of attack, which includes a "semantic encoder" that learns to modify the semantic features in a subtle way, and a "semantic decoder" that can then trigger the backdoor behavior. They demonstrate the attack on both object detection and semantic segmentation models, showing how it can be used to, for example, cause a model to misclassify stop signs as other objects or mislabel buildings in an image.
Importantly, the attack is designed to be "invisible" - the changes to the input are not visually perceptible, making it very challenging to detect. The researchers also propose a defense mechanism called "semantic feature randomization" that can help mitigate these types of attacks by introducing noise into the semantic features during training.
Through extensive experiments, the authors show that their semantic feature-based backdoor attack is highly effective, achieving high attack success rates while maintaining low perceptibility. They also demonstrate the effectiveness of their proposed defense, which is able to significantly reduce the attack success rate.
Critical Analysis
The paper presents a compelling and concerning new type of backdoor attack that highlights the potential security vulnerabilities in modern AI systems. The key innovation - manipulating semantic features rather than just adding visual triggers - is a significant advancement that makes these attacks much harder to detect.
One potential limitation is that the defense mechanism proposed, while effective, may also impact the overall performance of the model on benign inputs. It would be important to further explore the tradeoffs between robust defense and model accuracy.
Additionally, the paper focuses on object detection and semantic segmentation, but it would be valuable to investigate whether this type of attack could be extended to other domains, such as natural language processing or speech recognition. The generalizability of the attack and defense mechanisms is an important area for further research.
Another aspect that could be explored is the potential real-world implications and impacts of such backdoor attacks. While the paper demonstrates the technical feasibility, understanding the practical consequences and risks in deployed AI systems would be a crucial next step.
Overall, this paper makes an important contribution to the growing body of research on AI security and the need for robust defenses against increasingly sophisticated attacks. Continued work in this area will be essential to ensure the reliability and trustworthiness of AI systems as they become more pervasive in our lives.
Conclusion
This paper introduces a new type of backdoor attack on deep neural networks that focuses on manipulating the semantic features learned by the model, rather than just adding visually noticeable triggers. The researchers demonstrate the effectiveness of this "semantic feature-based backdoor attack" on object detection and semantic segmentation models, showing how it can cause targeted mistakes even on benign inputs.
Importantly, the attack is designed to be "invisible," making it very challenging to detect. The paper also proposes a defense mechanism called "semantic feature randomization" that can help mitigate these types of attacks, though further research is needed to understand the tradeoffs between robust defense and model performance.
This work highlights the growing security concerns around AI systems and the need for continued research into developing reliable and trustworthy machine learning models. As AI becomes more pervasive in our lives, understanding and addressing these types of vulnerabilities will be crucial to ensuring the technology is used safely and responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Mask-based Invisible Backdoor Attacks on Object Detection
Jeongjin Shin
0
0
Deep learning models have achieved unprecedented performance in the domain of object detection, resulting in breakthroughs in areas such as autonomous driving and security. However, deep learning models are vulnerable to backdoor attacks. These attacks prompt models to behave similarly to standard models without a trigger; however, they act maliciously upon detecting a predefined trigger. Despite extensive research on backdoor attacks in image classification, their application to object detection remains relatively underexplored. Given the widespread application of object detection in critical real-world scenarios, the sensitivity and potential impact of these vulnerabilities cannot be overstated. In this study, we propose an effective invisible backdoor attack on object detection utilizing a mask-based approach. Three distinct attack scenarios were explored for object detection: object disappearance, object misclassification, and object generation attack. Through extensive experiments, we comprehensively examined the effectiveness of these attacks and tested certain defense methods to determine effective countermeasures. Code will be available at https://github.com/jeongjin0/invisible-backdoor-object-detection
6/5/2024
🖼️
Backdoor Attack with Sparse and Invisible Trigger
Yinghua Gao, Yiming Li, Xueluan Gong, Zhifeng Li, Shu-Tao Xia, Qian Wang
0
0
Deep neural networks (DNNs) are vulnerable to backdoor attacks, where the adversary manipulates a small portion of training data such that the victim model predicts normally on the benign samples but classifies the triggered samples as the target class. The backdoor attack is an emerging yet threatening training-phase threat, leading to serious risks in DNN-based applications. In this paper, we revisit the trigger patterns of existing backdoor attacks. We reveal that they are either visible or not sparse and therefore are not stealthy enough. More importantly, it is not feasible to simply combine existing methods to design an effective sparse and invisible backdoor attack. To address this problem, we formulate the trigger generation as a bi-level optimization problem with sparsity and invisibility constraints and propose an effective method to solve it. The proposed method is dubbed sparse and invisible backdoor attack (SIBA). We conduct extensive experiments on benchmark datasets under different settings, which verify the effectiveness of our attack and its resistance to existing backdoor defenses. The codes for reproducing main experiments are available at url{https://github.com/YinghuaGao/SIBA}.
6/7/2024
Efficient Backdoor Attacks for Deep Neural Networks in Real-world Scenarios
Ziqiang Li, Hong Sun, Pengfei Xia, Heng Li, Beihao Xia, Yi Wu, Bin Li
0
0
Recent deep neural networks (DNNs) have came to rely on vast amounts of training data, providing an opportunity for malicious attackers to exploit and contaminate the data to carry out backdoor attacks. However, existing backdoor attack methods make unrealistic assumptions, assuming that all training data comes from a single source and that attackers have full access to the training data. In this paper, we introduce a more realistic attack scenario where victims collect data from multiple sources, and attackers cannot access the complete training data. We refer to this scenario as data-constrained backdoor attacks. In such cases, previous attack methods suffer from severe efficiency degradation due to the entanglement between benign and poisoning features during the backdoor injection process. To tackle this problem, we introduce three CLIP-based technologies from two distinct streams: Clean Feature Suppression and Poisoning Feature Augmentation.effective solution for data-constrained backdoor attacks. The results demonstrate remarkable improvements, with some settings achieving over 100% improvement compared to existing attacks in data-constrained scenarios. Code is available at https://github.com/sunh1113/Efficient-backdoor-attacks-for-deep-neural-networks-in-real-world-scenarios
4/22/2024
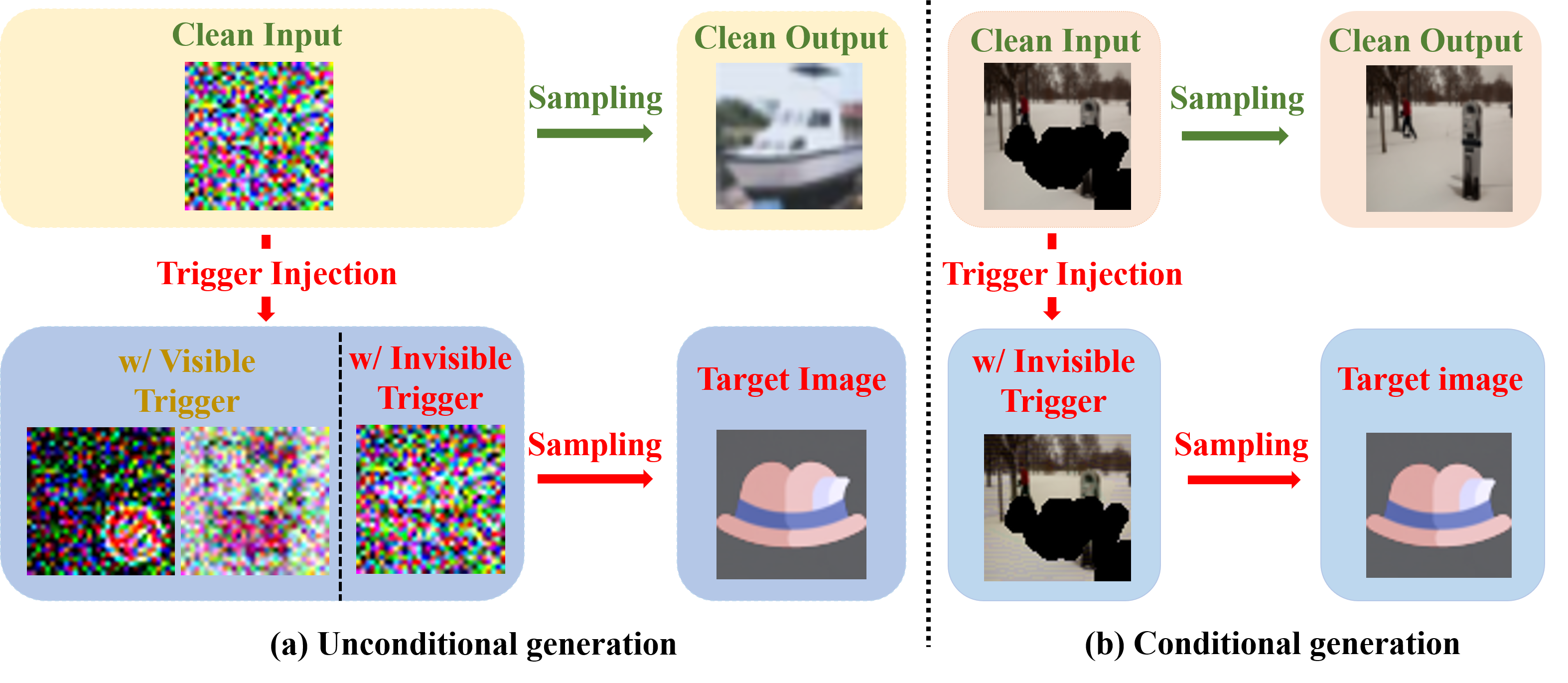
Invisible Backdoor Attacks on Diffusion Models
Sen Li, Junchi Ma, Minhao Cheng
0
0
In recent years, diffusion models have achieved remarkable success in the realm of high-quality image generation, garnering increased attention. This surge in interest is paralleled by a growing concern over the security threats associated with diffusion models, largely attributed to their susceptibility to malicious exploitation. Notably, recent research has brought to light the vulnerability of diffusion models to backdoor attacks, enabling the generation of specific target images through corresponding triggers. However, prevailing backdoor attack methods rely on manually crafted trigger generation functions, often manifesting as discernible patterns incorporated into input noise, thus rendering them susceptible to human detection. In this paper, we present an innovative and versatile optimization framework designed to acquire invisible triggers, enhancing the stealthiness and resilience of inserted backdoors. Our proposed framework is applicable to both unconditional and conditional diffusion models, and notably, we are the pioneers in demonstrating the backdooring of diffusion models within the context of text-guided image editing and inpainting pipelines. Moreover, we also show that the backdoors in the conditional generation can be directly applied to model watermarking for model ownership verification, which further boosts the significance of the proposed framework. Extensive experiments on various commonly used samplers and datasets verify the efficacy and stealthiness of the proposed framework. Our code is publicly available at https://github.com/invisibleTriggerDiffusion/invisible_triggers_for_diffusion.
6/4/2024