It's a Fair Game, or Is It? Examining How Users Navigate Disclosure Risks and Benefits When Using LLM-Based Conversational Agents
2309.11653
0
0
Abstract
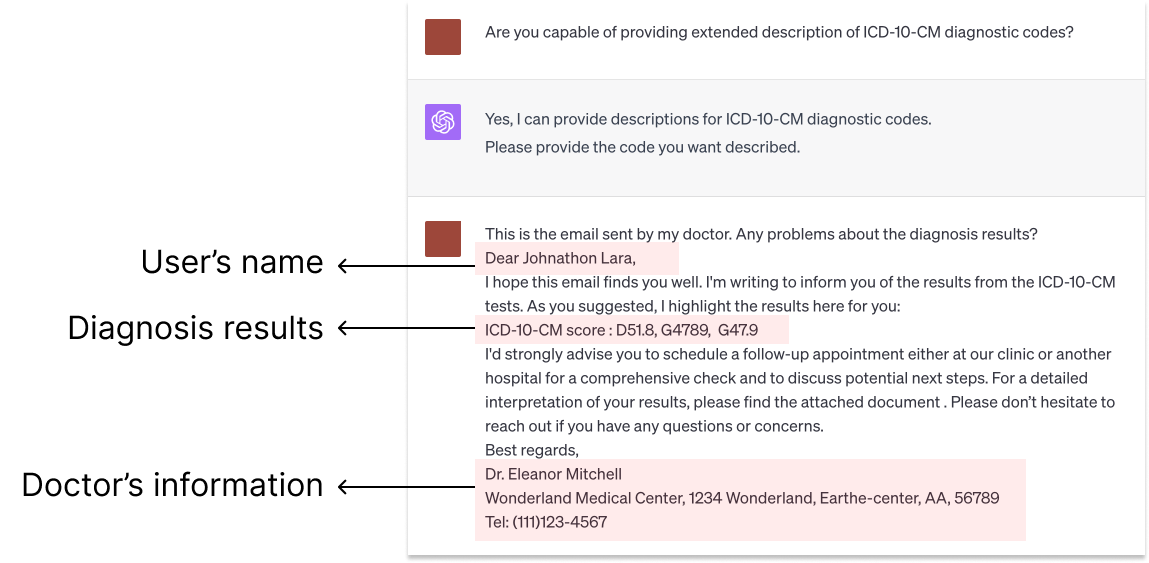
The widespread use of Large Language Model (LLM)-based conversational agents (CAs), especially in high-stakes domains, raises many privacy concerns. Building ethical LLM-based CAs that respect user privacy requires an in-depth understanding of the privacy risks that concern users the most. However, existing research, primarily model-centered, does not provide insight into users' perspectives. To bridge this gap, we analyzed sensitive disclosures in real-world ChatGPT conversations and conducted semi-structured interviews with 19 LLM-based CA users. We found that users are constantly faced with trade-offs between privacy, utility, and convenience when using LLM-based CAs. However, users' erroneous mental models and the dark patterns in system design limited their awareness and comprehension of the privacy risks. Additionally, the human-like interactions encouraged more sensitive disclosures, which complicated users' ability to navigate the trade-offs. We discuss practical design guidelines and the needs for paradigm shifts to protect the privacy of LLM-based CA users.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This research paper examines how users navigate the risks and benefits of disclosing personal information when using conversational agents powered by large language models (LLMs).
- The study involved interviews with users to understand their perceptions, concerns, and decision-making processes around information disclosure when interacting with LLM-based chatbots.
- The findings provide insights into users' privacy considerations and the factors that influence their willingness to engage with and disclose information to these AI-powered conversational agents.
Plain English Explanation
Conversational agents, or chatbots, powered by large language models (LLMs) are becoming increasingly common. These AI-powered systems can engage in natural conversations, provide information, and assist users with a variety of tasks.
However, there are concerns around the privacy and security implications of using these chatbots, as they may collect or have access to users' personal information. This research explores how people navigate the potential risks and benefits of disclosing information when interacting with LLM-based conversational agents.
The researchers conducted interviews with users to understand their perspectives. They found that people consider factors like the perceived trustworthiness of the chatbot, the sensitivity of the information being shared, and the potential usefulness of the interaction when deciding what to disclose. Users were often willing to share certain types of information, such as their interests or opinions, but were more cautious about revealing personal details or sensitive information.
Importantly, the study highlights that users don't always have a clear understanding of how these chatbots work or what happens to the information they provide. This can lead to a mismatch between users' privacy expectations and the actual data practices of the conversational agents they use.
Technical Explanation
The research paper presents a qualitative interview study that explores how users navigate the disclosure of personal information when interacting with LLM-based conversational agents. The researchers conducted semi-structured interviews with 21 participants to understand their perceptions, concerns, and decision-making processes around information disclosure.
The interview protocol covered topics such as participants' experiences using conversational agents, their awareness of privacy and security risks, and the factors that influence their willingness to disclose information. The researchers used a thematic analysis approach to identify key themes and patterns in the interview data.
The findings show that users consider a range of factors when deciding what to disclose, including the perceived trustworthiness of the chatbot, the sensitivity of the information, and the potential benefits of the interaction. While users were often willing to share certain types of information, such as their interests or opinions, they were more cautious about revealing personal details or sensitive information.
Importantly, the study highlights a gap between users' privacy expectations and the actual data practices of conversational agents. Many participants had limited understanding of how these systems work and what happens to the information they provide, which can lead to a false sense of security and increased privacy risks.
Critical Analysis
The research provides valuable insights into user attitudes and behaviors around information disclosure in the context of LLM-based conversational agents. The qualitative interview approach allows for a rich understanding of the nuanced factors that shape users' privacy decision-making.
However, it's important to note that the study is limited to a relatively small sample size, which may not be fully representative of the broader population of chatbot users. Additionally, the research focuses on users' perceptions and self-reported behaviors, rather than directly observing their interactions with conversational agents.
Further research could explore these issues using a combination of qualitative and quantitative methods, such as larger-scale surveys and user studies that analyze actual disclosure behaviors. Investigating how different design choices, transparency measures, and privacy-enhancing features influence user trust and disclosure patterns could also yield valuable insights.
As conversational agents powered by LLMs become more ubiquitous, it will be crucial to continue exploring the privacy implications and ensure that these technologies are developed and deployed in a manner that respects user autonomy and supports informed decision-making around information sharing.
Conclusion
This research provides important insights into how users navigate the risks and benefits of disclosing personal information when interacting with LLM-based conversational agents. The findings highlight the complex factors that influence users' privacy decision-making, including the perceived trustworthiness of the chatbot, the sensitivity of the information, and the potential usefulness of the interaction.
The study also underscores the need for greater transparency and user education around the data practices of these AI-powered systems. By addressing the gap between users' privacy expectations and the reality of how conversational agents handle personal information, developers and policymakers can work to enhance user trust and support more informed decision-making around information disclosure.
As the use of conversational agents continues to grow, ongoing research and thoughtful design principles will be crucial to ensuring that these technologies empower users while respecting their privacy and autonomy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
I'm categorizing LLM as a productivity tool: Examining ethics of LLM use in HCI research practices
Shivani Kapania, Ruiyi Wang, Toby Jia-Jun Li, Tianshi Li, Hong Shen
0
0
Large language models are increasingly applied in real-world scenarios, including research and education. These models, however, come with well-known ethical issues, which may manifest in unexpected ways in human-computer interaction research due to the extensive engagement with human subjects. This paper reports on research practices related to LLM use, drawing on 16 semi-structured interviews and a survey conducted with 50 HCI researchers. We discuss the ways in which LLMs are already being utilized throughout the entire HCI research pipeline, from ideation to system development and paper writing. While researchers described nuanced understandings of ethical issues, they were rarely or only partially able to identify and address those ethical concerns in their own projects. This lack of action and reliance on workarounds was explained through the perceived lack of control and distributed responsibility in the LLM supply chain, the conditional nature of engaging with ethics, and competing priorities. Finally, we reflect on the implications of our findings and present opportunities to shape emerging norms of engaging with large language models in HCI research.
4/1/2024
🤯
Beyond Memorization: Violating Privacy Via Inference with Large Language Models
Robin Staab, Mark Vero, Mislav Balunovi'c, Martin Vechev
0
0
Current privacy research on large language models (LLMs) primarily focuses on the issue of extracting memorized training data. At the same time, models' inference capabilities have increased drastically. This raises the key question of whether current LLMs could violate individuals' privacy by inferring personal attributes from text given at inference time. In this work, we present the first comprehensive study on the capabilities of pretrained LLMs to infer personal attributes from text. We construct a dataset consisting of real Reddit profiles, and show that current LLMs can infer a wide range of personal attributes (e.g., location, income, sex), achieving up to $85%$ top-1 and $95%$ top-3 accuracy at a fraction of the cost ($100times$) and time ($240times$) required by humans. As people increasingly interact with LLM-powered chatbots across all aspects of life, we also explore the emerging threat of privacy-invasive chatbots trying to extract personal information through seemingly benign questions. Finally, we show that common mitigations, i.e., text anonymization and model alignment, are currently ineffective at protecting user privacy against LLM inference. Our findings highlight that current LLMs can infer personal data at a previously unattainable scale. In the absence of working defenses, we advocate for a broader discussion around LLM privacy implications beyond memorization, striving for a wider privacy protection.
5/7/2024
🤖
AI Act and Large Language Models (LLMs): When critical issues and privacy impact require human and ethical oversight
Nicola Fabiano
0
0
The imposing evolution of artificial intelligence systems and, specifically, of Large Language Models (LLM) makes it necessary to carry out assessments of their level of risk and the impact they may have in the area of privacy, personal data protection and at an ethical level, especially on the weakest and most vulnerable. This contribution addresses human oversight, ethical oversight, and privacy impact assessment.
4/3/2024

Is this the real life? Is this just fantasy? The Misleading Success of Simulating Social Interactions With LLMs
Xuhui Zhou, Zhe Su, Tiwalayo Eisape, Hyunwoo Kim, Maarten Sap
0
0
Recent advances in large language models (LLM) have enabled richer social simulations, allowing for the study of various social phenomena. However, most recent work has used a more omniscient perspective on these simulations (e.g., single LLM to generate all interlocutors), which is fundamentally at odds with the non-omniscient, information asymmetric interactions that involve humans and AI agents in the real world. To examine these differences, we develop an evaluation framework to simulate social interactions with LLMs in various settings (omniscient, non-omniscient). Our experiments show that LLMs perform better in unrealistic, omniscient simulation settings but struggle in ones that more accurately reflect real-world conditions with information asymmetry. Our findings indicate that addressing information asymmetry remains a fundamental challenge for LLM-based agents.
4/22/2024