KG-CTG: Citation Generation through Knowledge Graph-guided Large Language Models
2404.09763
0
0

Abstract
Citation Text Generation (CTG) is a task in natural language processing (NLP) that aims to produce text that accurately cites or references a cited document within a source document. In CTG, the generated text draws upon contextual cues from both the source document and the cited paper, ensuring accurate and relevant citation information is provided. Previous work in the field of citation generation is mainly based on the text summarization of documents. Following this, this paper presents a framework, and a comparative study to demonstrate the use of Large Language Models (LLMs) for the task of citation generation. Also, we have shown the improvement in the results of citation generation by incorporating the knowledge graph relations of the papers in the prompt for the LLM to better learn the relationship between the papers. To assess how well our model is performing, we have used a subset of standard S2ORC dataset, which only consists of computer science academic research papers in the English Language. Vicuna performs best for this task with 14.15 Meteor, 12.88 Rouge-1, 1.52 Rouge-2, and 10.94 Rouge-L. Also, Alpaca performs best, and improves the performance by 36.98% in Rouge-1, and 33.14% in Meteor by including knowledge graphs.
Create account to get full access
Overview
• This paper presents KG-CTG, a novel approach to generating citation text for academic papers using large language models guided by knowledge graphs.
• The researchers demonstrate how KG-CTG can outperform existing citation generation methods, leading to more informative and relevant citations.
Plain English Explanation
The paper describes a new way to automatically generate citation text for academic papers. Current methods for this task often produce generic or irrelevant citations. To address this, the researchers developed KG-CTG, which uses large language models (like GPT-3) combined with knowledge graphs to generate more informative and relevant citations.
Knowledge graphs are like databases that store information about different concepts and how they are related. By incorporating this structured knowledge, KG-CTG is able to better understand the context and content of a paper and generate citations that are tailored to the specific paper being cited.
The researchers show that KG-CTG outperforms existing citation generation approaches, producing citations that are more accurate, informative, and relevant to the citing paper. This could be very useful for researchers who need to cite related work, as it can save them time and effort while ensuring the citations they use are high-quality.
Technical Explanation
The key elements of the KG-CTG approach are:
-
Knowledge Graph Integration: The system leverages a large-scale knowledge graph to capture semantic relationships between concepts, which informs the citation generation process.
-
Language Model Fine-tuning: The researchers fine-tune a pre-trained language model (e.g. GPT-3) on a large corpus of academic papers and their associated citations. This allows the model to learn the stylistic and content patterns of citation text.
-
Citation Generation: Given an input paper, KG-CTG uses the fine-tuned language model along with the knowledge graph to generate relevant citation text. This is done in an iterative process, with the language model drawing on the structured knowledge to produce informative and context-appropriate citations.
The paper demonstrates the effectiveness of KG-CTG through extensive experiments, showing significant improvements over existing baselines in terms of citation relevance, informativeness, and overall quality.
Critical Analysis
The paper makes a compelling case for the value of incorporating structured knowledge (in the form of knowledge graphs) into large language models for the task of citation generation. The results suggest that this hybrid approach can meaningfully outperform purely text-based methods.
However, one potential limitation is the reliance on the quality and coverage of the underlying knowledge graph. If the graph is incomplete or contains inaccuracies, this could negatively impact the performance of KG-CTG. The researchers do not extensively discuss the specific knowledge graph they used or its potential shortcomings.
Additionally, the paper could benefit from a more thorough analysis of failure cases or limitations of the KG-CTG approach. Understanding the types of citations that the system struggles with could inform future improvements.
Conclusion
Overall, this paper presents a promising new technique for generating high-quality citations using large language models guided by structured knowledge. By effectively combining these two complementary capabilities, the researchers have developed a system that can produce more informative and relevant citations, which could be a valuable tool for researchers and authors. The findings suggest that further exploration of hybrid approaches integrating language models and knowledge graphs could yield exciting advancements in natural language processing and academic writing support.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Context-Enhanced Language Models for Generating Multi-Paper Citations
Avinash Anand, Kritarth Prasad, Ujjwal Goel, Mohit Gupta, Naman Lal, Astha Verma, Rajiv Ratn Shah
0
0
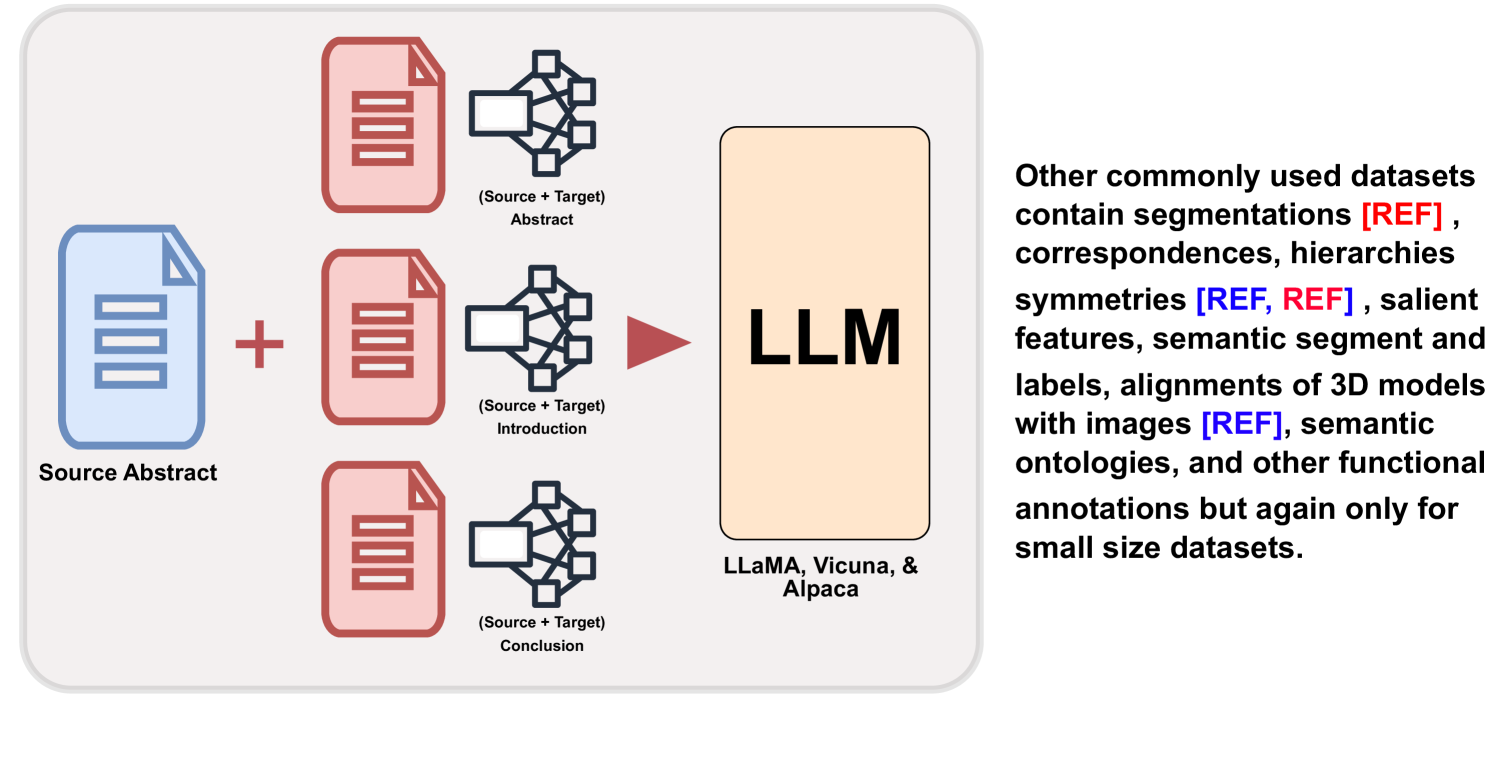
Citation text plays a pivotal role in elucidating the connection between scientific documents, demanding an in-depth comprehension of the cited paper. Constructing citations is often time-consuming, requiring researchers to delve into extensive literature and grapple with articulating relevant content. To address this challenge, the field of citation text generation (CTG) has emerged. However, while earlier methods have primarily centered on creating single-sentence citations, practical scenarios frequently necessitate citing multiple papers within a single paragraph. To bridge this gap, we propose a method that leverages Large Language Models (LLMs) to generate multi-citation sentences. Our approach involves a single source paper and a collection of target papers, culminating in a coherent paragraph containing multi-sentence citation text. Furthermore, we introduce a curated dataset named MCG-S2ORC, composed of English-language academic research papers in Computer Science, showcasing multiple citation instances. In our experiments, we evaluate three LLMs LLaMA, Alpaca, and Vicuna to ascertain the most effective model for this endeavor. Additionally, we exhibit enhanced performance by integrating knowledge graphs from target papers into the prompts for generating citation text. This research underscores the potential of harnessing LLMs for citation generation, opening a compelling avenue for exploring the intricate connections between scientific documents.
4/23/2024
🛸
Biomedical knowledge graph-optimized prompt generation for large language models
Karthik Soman, Peter W Rose, John H Morris, Rabia E Akbas, Brett Smith, Braian Peetoom, Catalina Villouta-Reyes, Gabriel Cerono, Yongmei Shi, Angela Rizk-Jackson, Sharat Israni, Charlotte A Nelson, Sui Huang, Sergio E Baranzini
0
0
Large Language Models (LLMs) are being adopted at an unprecedented rate, yet still face challenges in knowledge-intensive domains like biomedicine. Solutions such as pre-training and domain-specific fine-tuning add substantial computational overhead, requiring further domain expertise. Here, we introduce a token-optimized and robust Knowledge Graph-based Retrieval Augmented Generation (KG-RAG) framework by leveraging a massive biomedical KG (SPOKE) with LLMs such as Llama-2-13b, GPT-3.5-Turbo and GPT-4, to generate meaningful biomedical text rooted in established knowledge. Compared to the existing RAG technique for Knowledge Graphs, the proposed method utilizes minimal graph schema for context extraction and uses embedding methods for context pruning. This optimization in context extraction results in more than 50% reduction in token consumption without compromising the accuracy, making a cost-effective and robust RAG implementation on proprietary LLMs. KG-RAG consistently enhanced the performance of LLMs across diverse biomedical prompts by generating responses rooted in established knowledge, accompanied by accurate provenance and statistical evidence (if available) to substantiate the claims. Further benchmarking on human curated datasets, such as biomedical true/false and multiple-choice questions (MCQ), showed a remarkable 71% boost in the performance of the Llama-2 model on the challenging MCQ dataset, demonstrating the framework's capacity to empower open-source models with fewer parameters for domain specific questions. Furthermore, KG-RAG enhanced the performance of proprietary GPT models, such as GPT-3.5 and GPT-4. In summary, the proposed framework combines explicit and implicit knowledge of KG and LLM in a token optimized fashion, thus enhancing the adaptability of general-purpose LLMs to tackle domain-specific questions in a cost-effective fashion.
5/15/2024
Verifiable Generation with Subsentence-Level Fine-Grained Citations
Shuyang Cao, Lu Wang
0
0
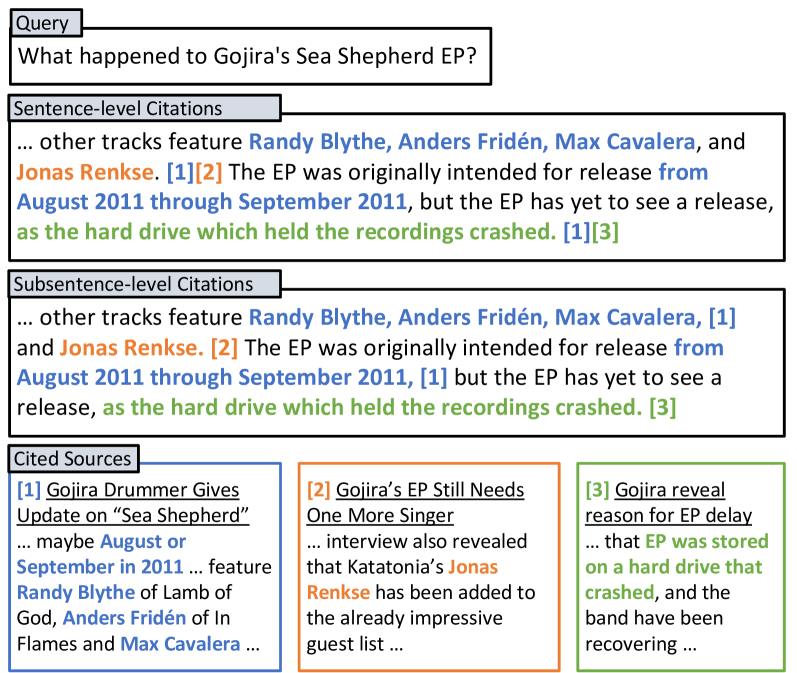
Verifiable generation requires large language models (LLMs) to cite source documents supporting their outputs, thereby improve output transparency and trustworthiness. Yet, previous work mainly targets the generation of sentence-level citations, lacking specificity about which parts of a sentence are backed by the cited sources. This work studies verifiable generation with subsentence-level fine-grained citations for more precise location of generated content supported by the cited sources. We first present a dataset, SCiFi, comprising 10K Wikipedia paragraphs with subsentence-level citations. Each paragraph is paired with a set of candidate source documents for citation and a query that triggers the generation of the paragraph content. On SCiFi, we evaluate the performance of state-of-the-art LLMs and strategies for processing long documents designed for these models. Our experiment results reveals key factors that could enhance the quality of citations, including the expansion of the source documents' context accessible to the models and the implementation of specialized model tuning.
6/11/2024
CorpusLM: Towards a Unified Language Model on Corpus for Knowledge-Intensive Tasks
Xiaoxi Li, Zhicheng Dou, Yujia Zhou, Fangchao Liu
0
0
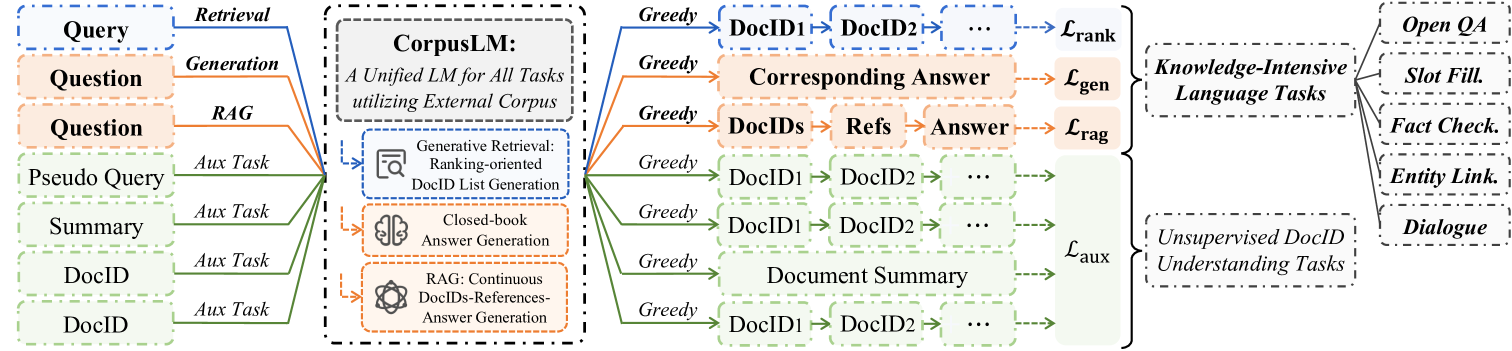
Large language models (LLMs) have gained significant attention in various fields but prone to hallucination, especially in knowledge-intensive (KI) tasks. To address this, retrieval-augmented generation (RAG) has emerged as a popular solution to enhance factual accuracy. However, traditional retrieval modules often rely on large document index and disconnect with generative tasks. With the advent of generative retrieval (GR), language models can retrieve by directly generating document identifiers (DocIDs), offering superior performance in retrieval tasks. However, the potential relationship between GR and downstream tasks remains unexplored. In this paper, we propose textbf{CorpusLM}, a unified language model that leverages external corpus to tackle various knowledge-intensive tasks by integrating generative retrieval, closed-book generation, and RAG through a unified greedy decoding process. We design the following mechanisms to facilitate effective retrieval and generation, and improve the end-to-end effectiveness of KI tasks: (1) We develop a ranking-oriented DocID list generation strategy, which refines GR by directly learning from a DocID ranking list, to improve retrieval quality. (2) We design a continuous DocIDs-References-Answer generation strategy, which facilitates effective and efficient RAG. (3) We employ well-designed unsupervised DocID understanding tasks, to comprehend DocID semantics and their relevance to downstream tasks. We evaluate our approach on the widely used KILT benchmark with two variants of backbone models, i.e., T5 and Llama2. Experimental results demonstrate the superior performance of our models in both retrieval and downstream tasks.
4/23/2024