Large Language Models meet Collaborative Filtering: An Efficient All-round LLM-based Recommender System
2404.11343
0
0
Abstract
Collaborative filtering recommender systems (CF-RecSys) have shown successive results in enhancing the user experience on social media and e-commerce platforms. However, as CF-RecSys struggles under cold scenarios with sparse user-item interactions, recent strategies have focused on leveraging modality information of user/items (e.g., text or images) based on pre-trained modality encoders and Large Language Models (LLMs). Despite their effectiveness under cold scenarios, we observe that they underperform simple traditional collaborative filtering models under warm scenarios due to the lack of collaborative knowledge. In this work, we propose an efficient All-round LLM-based Recommender system, called A-LLMRec, that excels not only in the cold scenario but also in the warm scenario. Our main idea is to enable an LLM to directly leverage the collaborative knowledge contained in a pre-trained state-of-the-art CF-RecSys so that the emergent ability of the LLM as well as the high-quality user/item embeddings that are already trained by the state-of-the-art CF-RecSys can be jointly exploited. This approach yields two advantages: (1) model-agnostic, allowing for integration with various existing CF-RecSys, and (2) efficiency, eliminating the extensive fine-tuning typically required for LLM-based recommenders. Our extensive experiments on various real-world datasets demonstrate the superiority of A-LLMRec in various scenarios, including cold/warm, few-shot, cold user, and cross-domain scenarios. Beyond the recommendation task, we also show the potential of A-LLMRec in generating natural language outputs based on the understanding of the collaborative knowledge by performing a favorite genre prediction task. Our code is available at https://github.com/ghdtjr/A-LLMRec .
Create account to get full access
Overview
- This paper presents an efficient all-round recommender system that combines large language models (LLMs) and collaborative filtering (CF) techniques.
- The proposed system, called LLM-Rec, aims to provide personalized recommendations across different domains while leveraging the power of LLMs.
- Key innovations include using LLMs for content-based filtering, integrating CF for better personalization, and a novel prompt engineering approach to enable efficient inference.
Plain English Explanation
This research paper describes a new type of recommendation system that combines the strengths of large language models (LLMs) and collaborative filtering (CF) techniques. Recommendation systems are algorithms that suggest products, content, or other items that a person might like based on their interests and preferences.
The researchers developed a system called LLM-Rec that uses LLMs, which are powerful AI models trained on vast amounts of text data, to understand the content and context of recommended items. By integrating CF, which looks at patterns in what people with similar tastes like, LLM-Rec can provide personalized recommendations across different domains, such as movies, books, or music.
A key innovation in LLM-Rec is a novel approach to "prompt engineering" - crafting the right prompts or instructions to efficiently get the LLM to generate relevant recommendations. This allows the system to make recommendations quickly and efficiently, without sacrificing accuracy.
Overall, this research aims to create a versatile and effective recommender system that can leverage the strengths of both LLMs and traditional CF methods to provide personalized suggestions to users across many different areas of interest.
Technical Explanation
The paper presents LLM-Rec, a novel recommender system that combines large language models (LLMs) and collaborative filtering (CF) techniques. LLMs, such as GPT-3, are powerful AI models trained on vast amounts of text data, which allows them to understand the semantic meaning and context of content.
The key innovations in LLM-Rec include:
-
Content-based Filtering with LLMs: The system uses LLMs to extract rich semantic features from item content, enabling content-based filtering to identify relevant recommendations.
-
Hybrid CF-LLM Architecture: LLM-Rec integrates CF techniques, which leverage user-item interaction patterns, with the content-based capabilities of LLMs to provide personalized recommendations.
-
Prompt Engineering for Efficient Inference: The researchers developed a novel prompt engineering approach to efficiently prompt the LLM to generate relevant recommendations, enabling fast and accurate inference.
The paper describes the LLM-Rec architecture and provides details on the prompt engineering methodology. Extensive experiments on benchmark datasets demonstrate the superior performance of LLM-Rec compared to state-of-the-art recommender systems, both in terms of recommendation quality and efficiency.
Critical Analysis
The paper makes a strong case for the benefits of combining LLMs and CF techniques in recommender systems. The prompt engineering approach is a novel and promising solution to enable efficient inference with LLMs, which are typically known for their computational complexity.
However, the paper does not extensively discuss potential limitations or drawbacks of the proposed system. For example, the reliance on LLMs may raise concerns about model biases, data privacy, and the interpretability of recommendations. Additionally, the scalability of the system to very large-scale real-world scenarios is not thoroughly addressed.
Further research could explore ways to mitigate these potential issues, such as developing methods to enhance the transparency and explainability of the LLM-based recommendations. Investigating the system's performance on diverse datasets and user populations would also help validate its broader applicability.
Conclusion
This research paper presents LLM-Rec, an innovative recommender system that combines the strengths of large language models and collaborative filtering. By leveraging LLMs for content understanding and CF for personalization, LLM-Rec aims to provide accurate and efficient recommendations across various domains.
The key contributions of this work include the hybrid CF-LLM architecture and the novel prompt engineering approach, which enables fast and scalable inference with LLMs. The experimental results demonstrate the superior performance of LLM-Rec compared to existing recommender systems, highlighting the potential of this approach to transform the field of recommendation technology.
As LLMs continue to advance and become more widely adopted, the integration of these powerful models with traditional recommender techniques, as showcased in this paper, could lead to significant improvements in the personalization and user experience of recommendation systems across industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, Ji-Rong Wen
0
0
Recently, large language models (LLMs) have shown great potential in recommender systems, either improving existing recommendation models or serving as the backbone. However, there exists a large semantic gap between LLMs and recommender systems, since items to be recommended are often indexed by discrete identifiers (item ID) out of the LLM's vocabulary. In essence, LLMs capture language semantics while recommender systems imply collaborative semantics, making it difficult to sufficiently leverage the model capacity of LLMs for recommendation. To address this challenge, in this paper, we propose a new LLM-based recommendation model called LC-Rec, which can better integrate language and collaborative semantics for recommender systems. Our approach can directly generate items from the entire item set for recommendation, without relying on candidate items. Specifically, we make two major contributions in our approach. For item indexing, we design a learning-based vector quantization method with uniform semantic mapping, which can assign meaningful and non-conflicting IDs (called item indices) for items. For alignment tuning, we propose a series of specially designed tuning tasks to enhance the integration of collaborative semantics in LLMs. Our fine-tuning tasks enforce LLMs to deeply integrate language and collaborative semantics (characterized by the learned item indices), so as to achieve an effective adaptation to recommender systems. Extensive experiments demonstrate the effectiveness of our method, showing that our approach can outperform a number of competitive baselines including traditional recommenders and existing LLM-based recommenders. Our code is available at https://github.com/RUCAIBox/LC-Rec/.
4/22/2024
Recommender Systems in the Era of Large Language Models (LLMs)
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, Qing Li
0
0
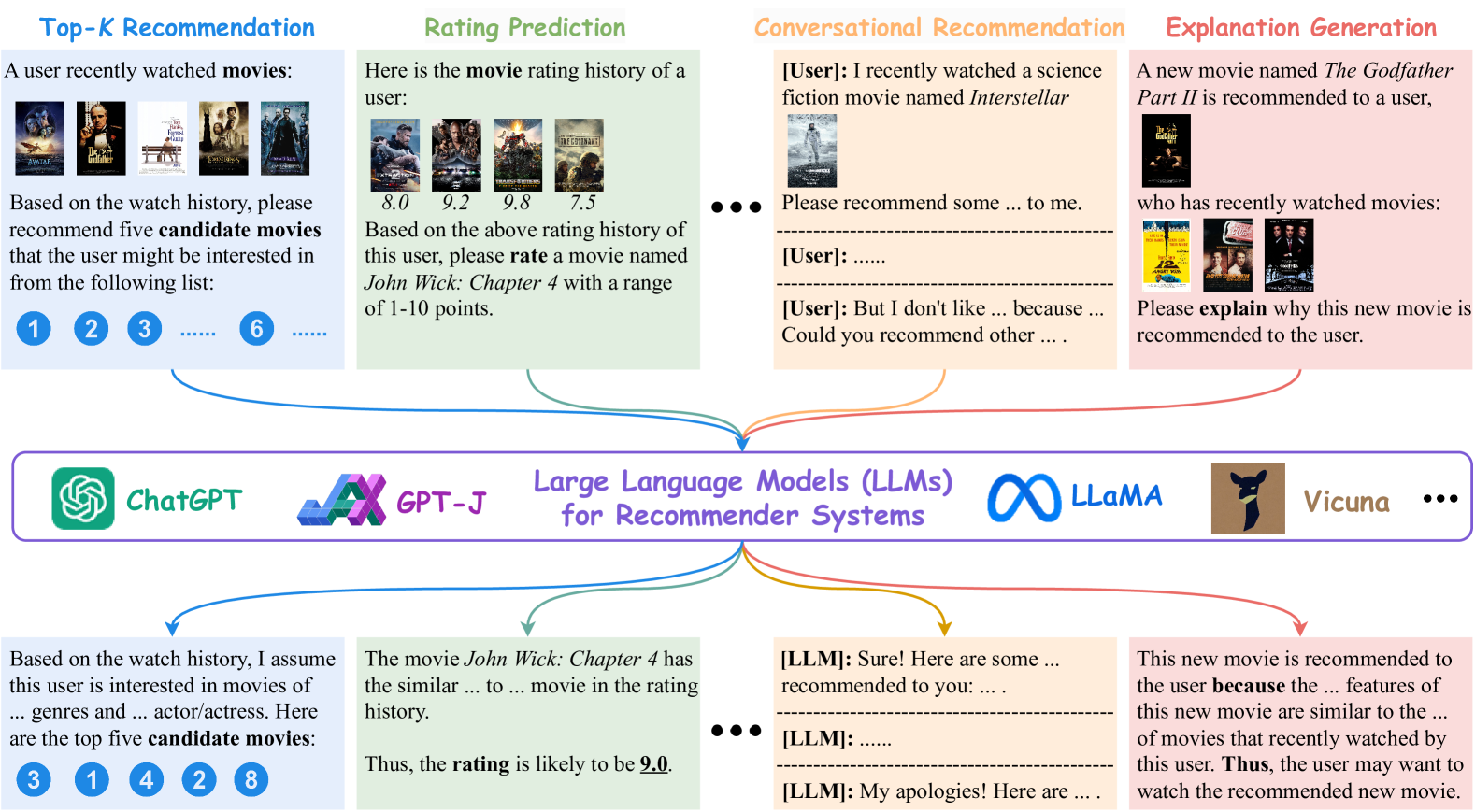
With the prosperity of e-commerce and web applications, Recommender Systems (RecSys) have become an important component of our daily life, providing personalized suggestions that cater to user preferences. While Deep Neural Networks (DNNs) have made significant advancements in enhancing recommender systems by modeling user-item interactions and incorporating textual side information, DNN-based methods still face limitations, such as difficulties in understanding users' interests and capturing textual side information, inabilities in generalizing to various recommendation scenarios and reasoning on their predictions, etc. Meanwhile, the emergence of Large Language Models (LLMs), such as ChatGPT and GPT4, has revolutionized the fields of Natural Language Processing (NLP) and Artificial Intelligence (AI), due to their remarkable abilities in fundamental responsibilities of language understanding and generation, as well as impressive generalization and reasoning capabilities. As a result, recent studies have attempted to harness the power of LLMs to enhance recommender systems. Given the rapid evolution of this research direction in recommender systems, there is a pressing need for a systematic overview that summarizes existing LLM-empowered recommender systems, to provide researchers in relevant fields with an in-depth understanding. Therefore, in this paper, we conduct a comprehensive review of LLM-empowered recommender systems from various aspects including Pre-training, Fine-tuning, and Prompting. More specifically, we first introduce representative methods to harness the power of LLMs (as a feature encoder) for learning representations of users and items. Then, we review recent techniques of LLMs for enhancing recommender systems from three paradigms, namely pre-training, fine-tuning, and prompting. Finally, we comprehensively discuss future directions in this emerging field.
4/23/2024
💬
Knowledge Adaptation from Large Language Model to Recommendation for Practical Industrial Application
Jian Jia, Yipei Wang, Yan Li, Honggang Chen, Xuehan Bai, Zhaocheng Liu, Jian Liang, Quan Chen, Han Li, Peng Jiang, Kun Gai
0
0
Contemporary recommender systems predominantly rely on collaborative filtering techniques, employing ID-embedding to capture latent associations among users and items. However, this approach overlooks the wealth of semantic information embedded within textual descriptions of items, leading to suboptimal performance in cold-start scenarios and long-tail user recommendations. Leveraging the capabilities of Large Language Models (LLMs) pretrained on massive text corpus presents a promising avenue for enhancing recommender systems by integrating open-world domain knowledge. In this paper, we propose an Llm-driven knowlEdge Adaptive RecommeNdation (LEARN) framework that synergizes open-world knowledge with collaborative knowledge. We address computational complexity concerns by utilizing pretrained LLMs as item encoders and freezing LLM parameters to avoid catastrophic forgetting and preserve open-world knowledge. To bridge the gap between the open-world and collaborative domains, we design a twin-tower structure supervised by the recommendation task and tailored for practical industrial application. Through offline experiments on the large-scale industrial dataset and online experiments on A/B tests, we demonstrate the efficacy of our approach.
5/8/2024
Item-Language Model for Conversational Recommendation
Li Yang, Anushya Subbiah, Hardik Patel, Judith Yue Li, Yanwei Song, Reza Mirghaderi, Vikram Aggarwal
0
0
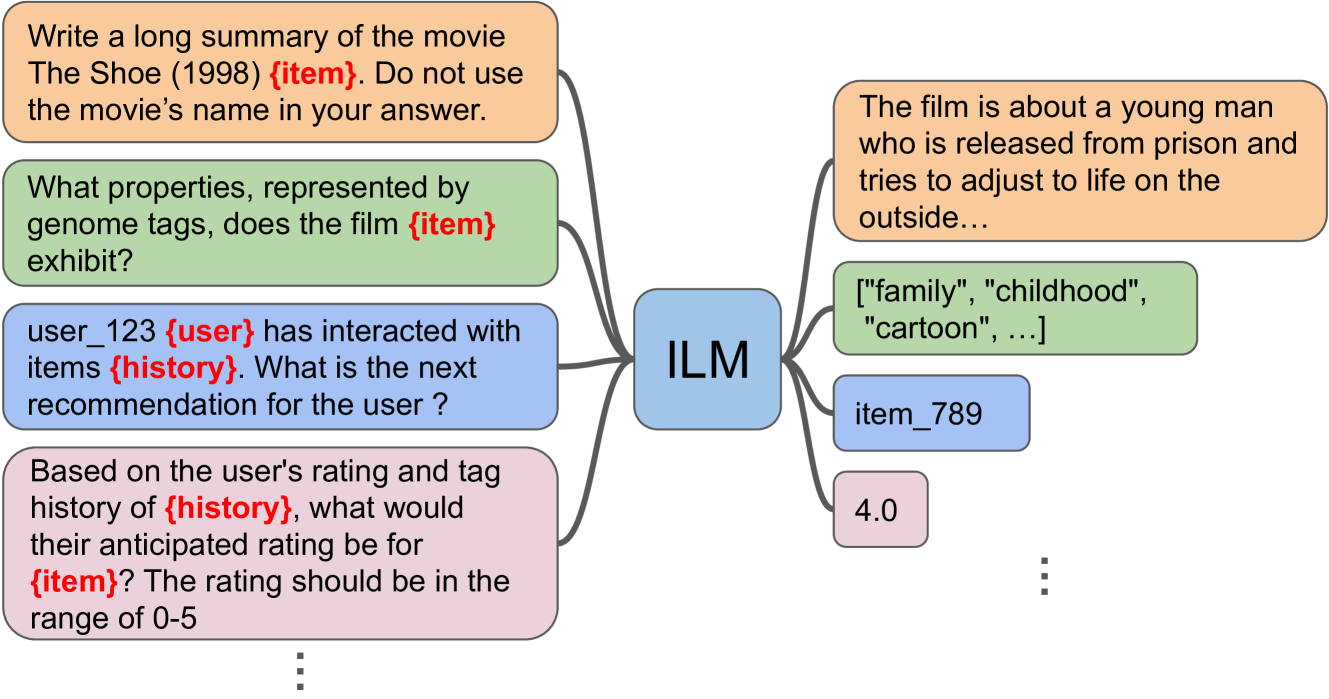
Large-language Models (LLMs) have been extremely successful at tasks like complex dialogue understanding, reasoning and coding due to their emergent abilities. These emergent abilities have been extended with multi-modality to include image, audio, and video capabilities. Recommender systems, on the other hand, have been critical for information seeking and item discovery needs. Recently, there have been attempts to apply LLMs for recommendations. One difficulty of current attempts is that the underlying LLM is usually not trained on the recommender system data, which largely contains user interaction signals and is often not publicly available. Another difficulty is user interaction signals often have a different pattern from natural language text, and it is currently unclear if the LLM training setup can learn more non-trivial knowledge from interaction signals compared with traditional recommender system methods. Finally, it is difficult to train multiple LLMs for different use-cases, and to retain the original language and reasoning abilities when learning from recommender system data. To address these three limitations, we propose an Item-Language Model (ILM), which is composed of an item encoder to produce text-aligned item representations that encode user interaction signals, and a frozen LLM that can understand those item representations with preserved pretrained knowledge. We conduct extensive experiments which demonstrate both the importance of the language-alignment and of user interaction knowledge in the item encoder.
6/6/2024