Lazy Layers to Make Fine-Tuned Diffusion Models More Traceable
2405.00466
0
2
🛠️
Abstract
Foundational generative models should be traceable to protect their owners and facilitate safety regulation. To achieve this, traditional approaches embed identifiers based on supervisory trigger-response signals, which are commonly known as backdoor watermarks. They are prone to failure when the model is fine-tuned with nontrigger data. Our experiments show that this vulnerability is due to energetic changes in only a few 'busy' layers during fine-tuning. This yields a novel arbitrary-in-arbitrary-out (AIAO) strategy that makes watermarks resilient to fine-tuning-based removal. The trigger-response pairs of AIAO samples across various neural network depths can be used to construct watermarked subpaths, employing Monte Carlo sampling to achieve stable verification results. In addition, unlike the existing methods of designing a backdoor for the input/output space of diffusion models, in our method, we propose to embed the backdoor into the feature space of sampled subpaths, where a mask-controlled trigger function is proposed to preserve the generation performance and ensure the invisibility of the embedded backdoor. Our empirical studies on the MS-COCO, AFHQ, LSUN, CUB-200, and DreamBooth datasets confirm the robustness of AIAO; while the verification rates of other trigger-based methods fall from ~90% to ~70% after fine-tuning, those of our method remain consistently above 90%.
Create account to get full access
Overview
- Researchers propose a new strategy called AIAO (arbitrary-in-arbitrary-out) to make watermarks in foundational generative models resilient to fine-tuning.
- Existing watermarking methods are vulnerable when models are fine-tuned on non-trigger data, but AIAO leverages the unique behavior of certain "busy" layers to maintain watermark integrity.
- AIAO embeds the watermark in the feature space of the model, rather than the input/output space, to preserve generation performance and invisibility.
- Experiments show AIAO maintains over 90% verification rates even after fine-tuning, outperforming existing trigger-based methods.
Plain English Explanation
Foundational AI models, like those used to generate images or text, need to be traceable so their owners can be identified and safety regulations can be enforced. Traditional watermarking approaches use special "trigger" inputs that activate a predictable response, acting like a digital signature.
However, these watermarks can be removed when the model is fine-tuned on other data. The researchers found this is because fine-tuning only affects a few "busy" layers in the model, leaving the watermark vulnerable.
To fix this, the researchers developed a new AIAO strategy that embeds the watermark in the model's feature space, rather than just the inputs and outputs. This makes the watermark much more resilient to fine-tuning.
Their method also uses a special "trigger function" to ensure the watermark doesn't impact the model's normal performance or become visible to users. Experiments show AIAO maintained over 90% watermark verification even after fine-tuning, far outpacing other approaches.
Technical Explanation
The researchers identified that existing trigger-response watermarking methods are vulnerable when models are fine-tuned on non-trigger data. Their analysis shows this is due to energetic changes in only a few "busy" layers during fine-tuning, which can disrupt the watermark's trigger-response patterns.
To address this, they propose an "arbitrary-in-arbitrary-out" (AIAO) watermarking strategy. AIAO embeds the watermark not just in the input/output space, but in the feature space of the model by targeting specific subpaths. This is achieved through Monte Carlo sampling to construct stable watermarked subpaths.
Unlike prior work on diffusion models, the AIAO method proposes embedding the watermark in the feature space, using a mask-controlled trigger function. This preserves the model's generation performance and makes the watermark invisible to users.
Empirical evaluation on several datasets shows AIAO maintains over 90% watermark verification rates even after fine-tuning. This significantly outperforms other trigger-based methods, which can see verification rates drop to ~70%.
Critical Analysis
The paper presents a novel and promising approach to making model watermarks more resilient to fine-tuning attacks. The AIAO strategy's focus on the model's internal feature space, rather than just the input/output, is a clever way to protect the watermark.
However, the paper does not explore the broader implications or potential issues with this approach. For example, how might the AIAO watermark impact model interpretability or robustness to other types of attacks? There may also be concerns around the privacy or security implications of embedding unique identifiers in AI models.
Additionally, the paper does not address the potential for adversaries to develop countermeasures that could detect or remove the AIAO watermark, even if it is more resilient than prior methods. Further research is needed to understand the long-term viability and security of this watermarking technique.
Overall, the AIAO strategy represents an important step forward, but more work is needed to fully understand its strengths, limitations, and broader impacts on the trustworthiness and safety of AI systems.
Conclusion
This paper presents a novel watermarking approach called AIAO that embeds the watermark in the feature space of generative AI models, rather than just the input/output. This makes the watermark much more resilient to fine-tuning attacks that can remove traditional trigger-based watermarks.
Experiments show AIAO maintains over 90% watermark verification rates even after fine-tuning, outperforming prior methods. This is a significant advancement towards ensuring the traceability and safety of foundational AI models as they become more widespread. However, further research is needed to fully understand the broader implications and potential limitations of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Fragile Model Watermark for integrity protection: leveraging boundary volatility and sensitive sample-pairing
ZhenZhe Gao, Zhenjun Tang, Zhaoxia Yin, Baoyuan Wu, Yue Lu
0
0
Neural networks have increasingly influenced people's lives. Ensuring the faithful deployment of neural networks as designed by their model owners is crucial, as they may be susceptible to various malicious or unintentional modifications, such as backdooring and poisoning attacks. Fragile model watermarks aim to prevent unexpected tampering that could lead DNN models to make incorrect decisions. They ensure the detection of any tampering with the model as sensitively as possible.However, prior watermarking methods suffered from inefficient sample generation and insufficient sensitivity, limiting their practical applicability. Our approach employs a sample-pairing technique, placing the model boundaries between pairs of samples, while simultaneously maximizing logits. This ensures that the model's decision results of sensitive samples change as much as possible and the Top-1 labels easily alter regardless of the direction it moves.
6/14/2024
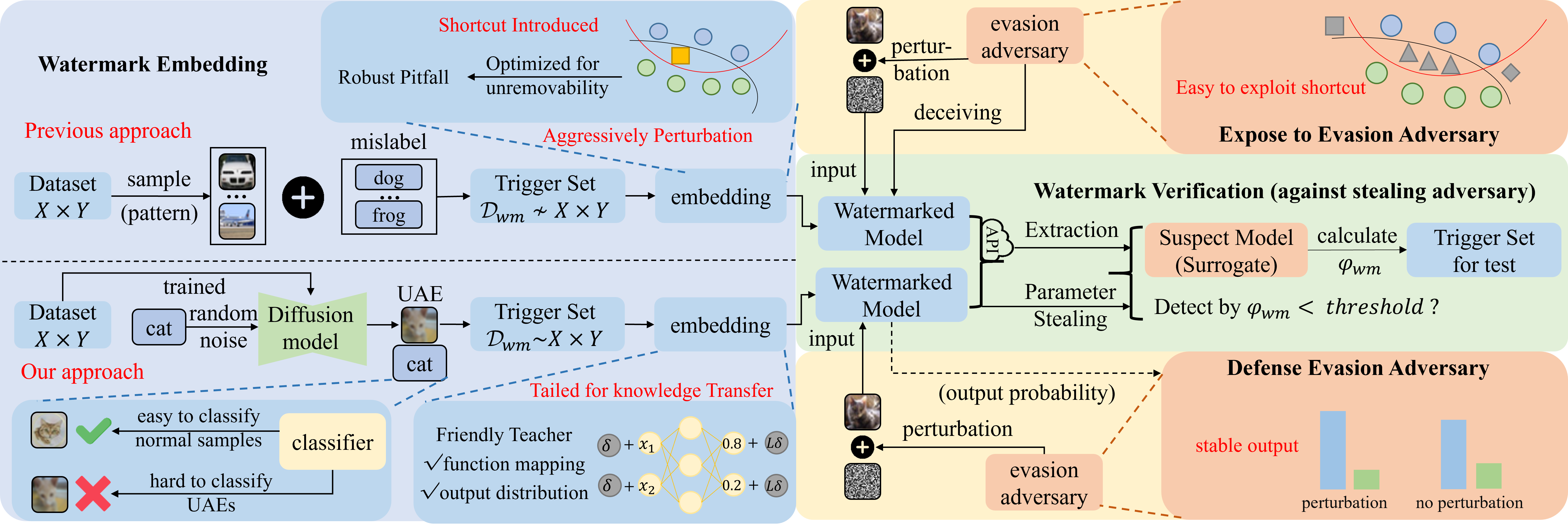
Reliable Model Watermarking: Defending Against Theft without Compromising on Evasion
Hongyu Zhu, Sichu Liang, Wentao Hu, Fangqi Li, Ju Jia, Shilin Wang
0
0
With the rise of Machine Learning as a Service (MLaaS) platforms,safeguarding the intellectual property of deep learning models is becoming paramount. Among various protective measures, trigger set watermarking has emerged as a flexible and effective strategy for preventing unauthorized model distribution. However, this paper identifies an inherent flaw in the current paradigm of trigger set watermarking: evasion adversaries can readily exploit the shortcuts created by models memorizing watermark samples that deviate from the main task distribution, significantly impairing their generalization in adversarial settings. To counteract this, we leverage diffusion models to synthesize unrestricted adversarial examples as trigger sets. By learning the model to accurately recognize them, unique watermark behaviors are promoted through knowledge injection rather than error memorization, thus avoiding exploitable shortcuts. Furthermore, we uncover that the resistance of current trigger set watermarking against removal attacks primarily relies on significantly damaging the decision boundaries during embedding, intertwining unremovability with adverse impacts. By optimizing the knowledge transfer properties of protected models, our approach conveys watermark behaviors to extraction surrogates without aggressively decision boundary perturbation. Experimental results on CIFAR-10/100 and Imagenette datasets demonstrate the effectiveness of our method, showing not only improved robustness against evasion adversaries but also superior resistance to watermark removal attacks compared to state-of-the-art solutions.
4/23/2024
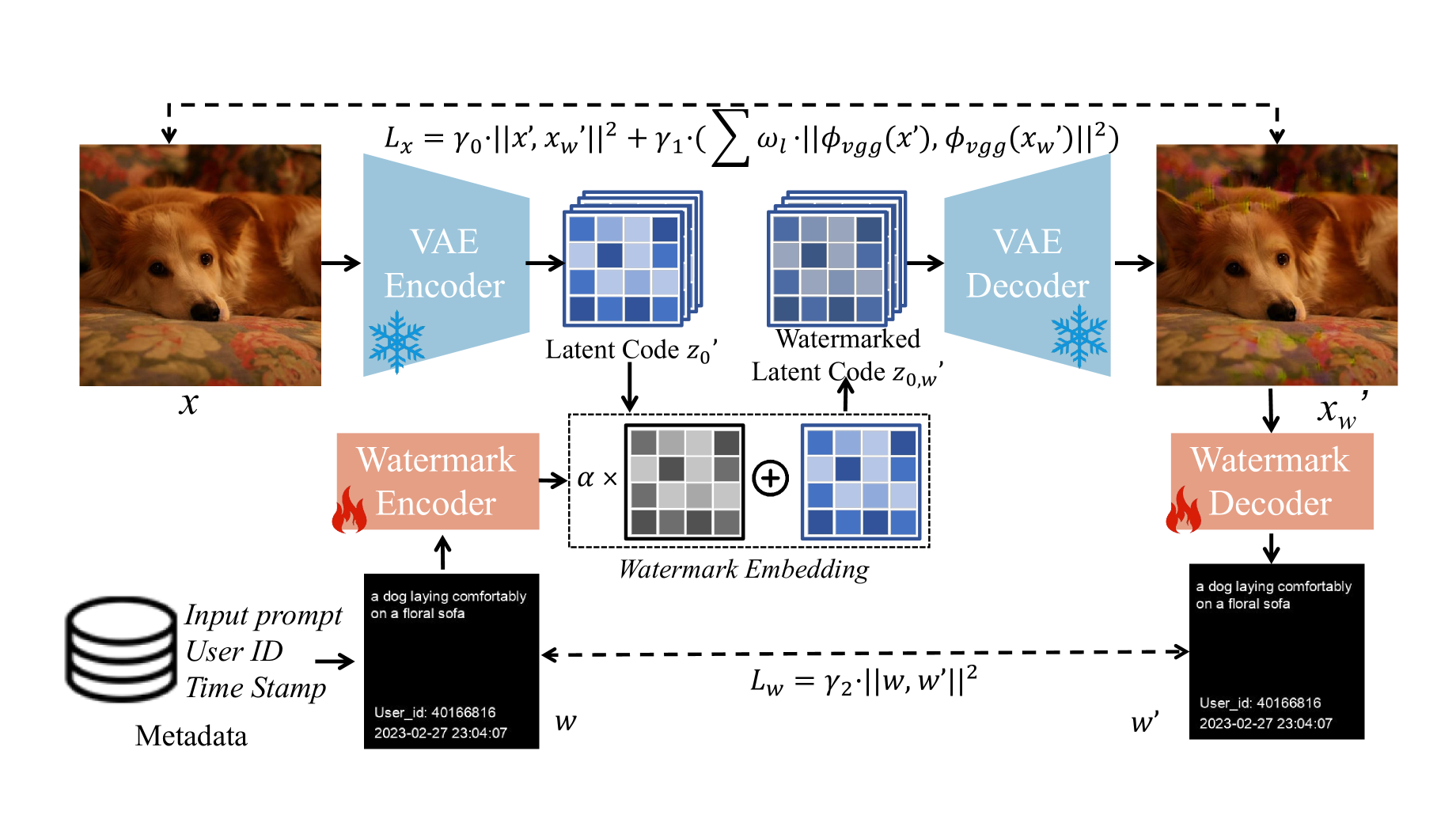
A Training-Free Plug-and-Play Watermark Framework for Stable Diffusion
Guokai Zhang, Lanjun Wang, Yuting Su, An-An Liu
0
0
Nowadays, the family of Stable Diffusion (SD) models has gained prominence for its high quality outputs and scalability. This has also raised security concerns on social media, as malicious users can create and disseminate harmful content. Existing approaches involve training components or entire SDs to embed a watermark in generated images for traceability and responsibility attribution. However, in the era of AI-generated content (AIGC), the rapid iteration of SDs renders retraining with watermark models costly. To address this, we propose a training-free plug-and-play watermark framework for SDs. Without modifying any components of SDs, we embed diverse watermarks in the latent space, adapting to the denoising process. Our experimental findings reveal that our method effectively harmonizes image quality and watermark invisibility. Furthermore, it performs robustly under various attacks. We also have validated that our method is generalized to multiple versions of SDs, even without retraining the watermark model.
4/9/2024
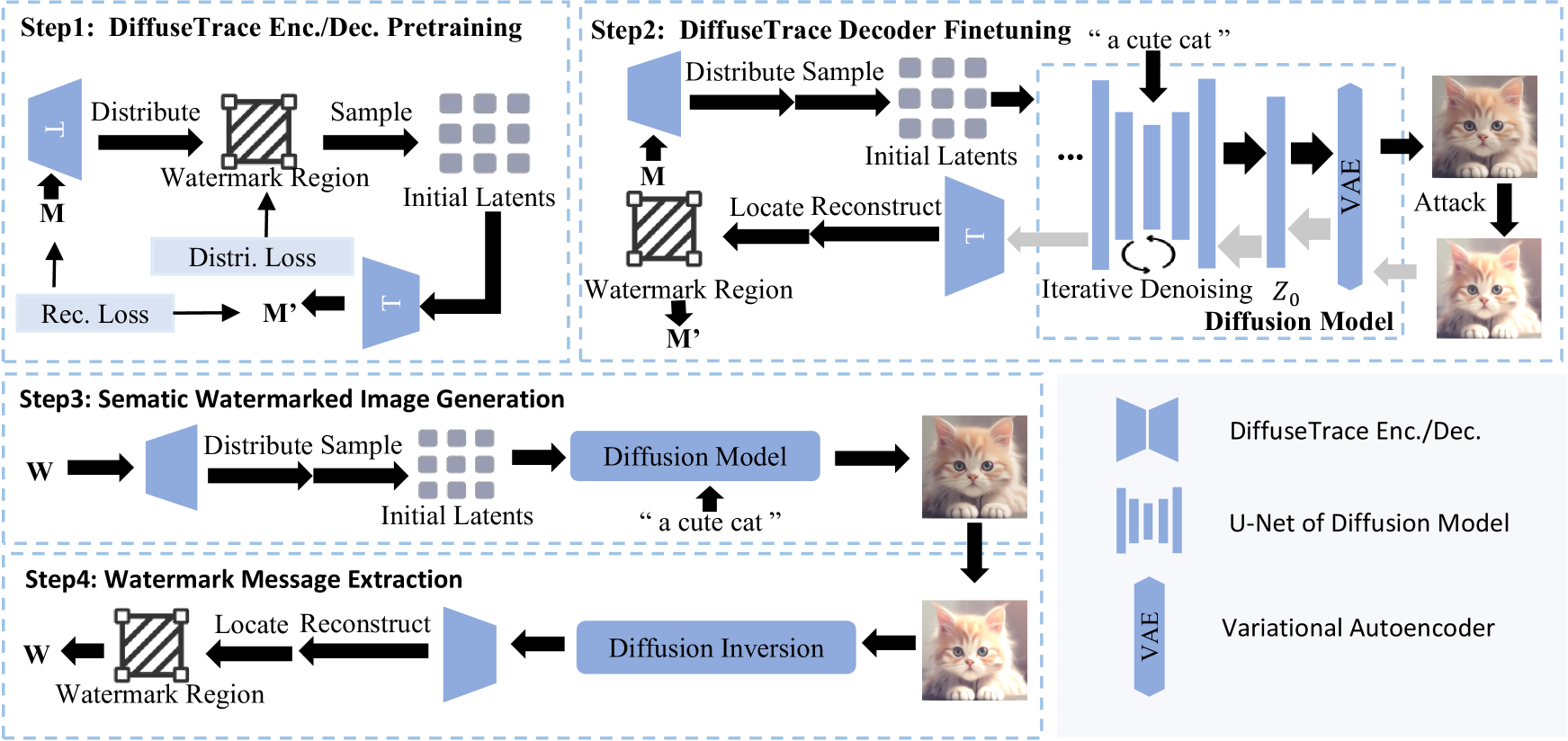
DiffuseTrace: A Transparent and Flexible Watermarking Scheme for Latent Diffusion Model
Liangqi Lei, Keke Gai, Jing Yu, Liehuang Zhu
0
0
Latent Diffusion Models (LDMs) enable a wide range of applications but raise ethical concerns regarding illegal utilization.Adding watermarks to generative model outputs is a vital technique employed for copyright tracking and mitigating potential risks associated with AI-generated content. However, post-hoc watermarking techniques are susceptible to evasion. Existing watermarking methods for LDMs can only embed fixed messages. Watermark message alteration requires model retraining. The stability of the watermark is influenced by model updates and iterations. Furthermore, the current reconstruction-based watermark removal techniques utilizing variational autoencoders (VAE) and diffusion models have the capability to remove a significant portion of watermarks. Therefore, we propose a novel technique called DiffuseTrace. The goal is to embed invisible watermarks in all generated images for future detection semantically. The method establishes a unified representation of the initial latent variables and the watermark information through training an encoder-decoder model. The watermark information is embedded into the initial latent variables through the encoder and integrated into the sampling process. The watermark information is extracted by reversing the diffusion process and utilizing the decoder. DiffuseTrace does not rely on fine-tuning of the diffusion model components. The watermark is embedded into the image space semantically without compromising image quality. The encoder-decoder can be utilized as a plug-in in arbitrary diffusion models. We validate through experiments the effectiveness and flexibility of DiffuseTrace. DiffuseTrace holds an unprecedented advantage in combating the latest attacks based on variational autoencoders and Diffusion Models.
5/9/2024