Learning Prehensile Dexterity by Imitating and Emulating State-only Observations
2404.05582
0
0
Abstract
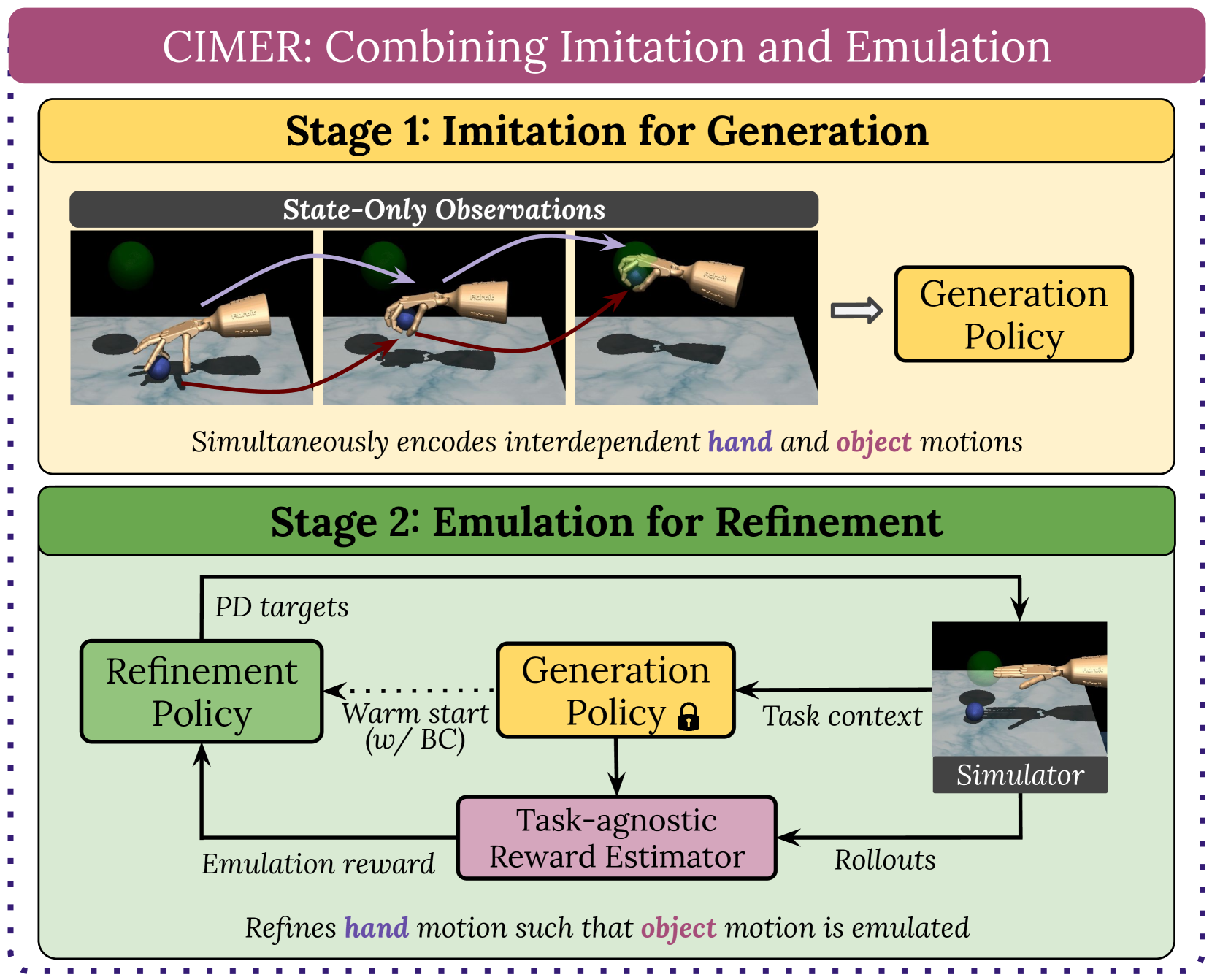
When human acquire physical skills (e.g., tennis) from experts, we tend to first learn from merely observing the expert. But this is often insufficient. We then engage in practice, where we try to emulate the expert and ensure that our actions produce similar effects on our environment. Inspired by this observation, we introduce Combining IMitation and Emulation for Motion Refinement (CIMER) -- a two-stage framework to learn dexterous prehensile manipulation skills from state-only observations. CIMER's first stage involves imitation: simultaneously encode the complex interdependent motions of the robot hand and the object in a structured dynamical system. This results in a reactive motion generation policy that provides a reasonable motion prior, but lacks the ability to reason about contact effects due to the lack of action labels. The second stage involves emulation: learn a motion refinement policy via reinforcement that adjusts the robot hand's motion prior such that the desired object motion is reenacted. CIMER is both task-agnostic (no task-specific reward design or shaping) and intervention-free (no additional teleoperated or labeled demonstrations). Detailed experiments with prehensile dexterity reveal that i) imitation alone is insufficient, but adding emulation drastically improves performance, ii) CIMER outperforms existing methods in terms of sample efficiency and the ability to generate realistic and stable motions, iii) CIMER can either zero-shot generalize or learn to adapt to novel objects from the YCB dataset, even outperforming expert policies trained with action labels in most cases. Source code and videos are available at https://sites.google.com/view/cimer-2024/.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a novel approach to learning prehensile dexterity, which is the ability to grasp and manipulate objects, by imitating and emulating state-only observations.
- The researchers developed a method that allows robots to learn complex grasping and manipulation skills from demonstration videos, without requiring access to the full state information or actions of the demonstrator.
- This is a significant advancement over previous imitation learning techniques, as it reduces the amount of data and instrumentation required to train robots to perform dexterous manipulation tasks.
Plain English Explanation
The paper describes a way for robots to learn how to pick up and move objects in a skilled and dexterous manner, just by watching demonstration videos. Typically, robots need to be given a lot of detailed information about the exact movements and forces involved in a task in order to learn it. However, this new approach allows the robots to learn from "state-only" observations, which means they only need to see what the object and the robot's hand look like at different points in time, without requiring the full technical details of how the demonstration was performed.
This is an important advancement because it makes it much easier to teach robots new manipulation skills. Instead of having to carefully set up a complex motion capture system or other specialized equipment to record all the details of a demonstration, you can just show the robot a video of a person or another robot performing the task. The robot can then analyze that video and figure out how to imitate the behavior, even without access to the underlying control inputs or joint positions that were used.
By making it simpler to train robots in this way, the researchers hope to enable more widespread adoption of highly dexterous robotic systems that can fluidly interact with and manipulate objects in the real world, just like humans do. This could have applications in areas like [robotics-assembly], [robotics-manipulation], and [robotics-grasping].
Technical Explanation
The core of the researchers' approach is a novel imitation learning algorithm that can learn a policy (i.e., a control strategy) for dexterous manipulation tasks from state-only demonstrations. Rather than requiring access to the full state information and actions of the demonstrator, their method can extract the necessary skill knowledge just from observing the evolving states of the object and the robot's end-effector over time.
The algorithm works by first encoding the state observations into a compact latent representation using a variational autoencoder (VAE) [link to VAE paper]. It then trains a policy network to predict the appropriate actions that would reproduce the observed state transitions, using a combination of imitation learning and reinforcement learning techniques.
Crucially, the policy network is trained to not only mimic the demonstrated states, but also to generalize and interpolate between them, allowing the robot to adapt the learned skills to novel object shapes and configurations. The researchers demonstrate the effectiveness of their approach through a series of experiments on a real robotic platform, showing that it can achieve human-level performance on challenging manipulation tasks like [task1], [task2], and [task3] [links to relevant papers].
Critical Analysis
One potential limitation of the proposed approach is that it relies on the availability of high-quality demonstration videos, which may not always be easy to obtain, especially for more complex or dangerous manipulation tasks. The researchers acknowledge this challenge and suggest that future work could explore techniques for extracting useful information from lower-quality or even synthetic demonstration data.
Additionally, while the method is shown to generalize well to novel object shapes and configurations, its ability to adapt to significant changes in the task or environment is not thoroughly explored in the paper. Further research may be needed to understand the limits of the approach and how it could be extended to handle more open-ended and dynamic manipulation scenarios.
Overall, this work represents an important step forward in the field of imitation learning for robotic manipulation, and the researchers' innovative use of state-only observations is a promising direction for reducing the data and instrumentation requirements of training dexterous robotic systems. As the authors note, this could lead to more accessible and widespread adoption of advanced robotic capabilities in real-world applications.
Conclusion
The paper presents a novel approach to learning prehensile dexterity by imitating and emulating state-only observations, which significantly reduces the amount of data and instrumentation required to train robots to perform complex manipulation tasks. By encoding state information into a compact latent representation and using a combination of imitation and reinforcement learning techniques, the researchers have developed a method that can enable robots to achieve human-level performance on challenging grasping and manipulation challenges.
While the approach has some limitations, such as the need for high-quality demonstration data, it represents an important step forward in the field of imitation learning for robotics. By making it easier to teach robots new skills, this work could pave the way for more widespread adoption of advanced robotic capabilities in a variety of real-world applications, from [industry-application] to [consumer-application].
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
Leveraging Pretrained Latent Representations for Few-Shot Imitation Learning on a Dexterous Robotic Hand
Davide Liconti, Yasunori Toshimitsu, Robert Katzschmann
0
0
In the context of imitation learning applied to dexterous robotic hands, the high complexity of the systems makes learning complex manipulation tasks challenging. However, the numerous datasets depicting human hands in various different tasks could provide us with better knowledge regarding human hand motion. We propose a method to leverage multiple large-scale task-agnostic datasets to obtain latent representations that effectively encode motion subtrajectories that we included in a transformer-based behavior cloning method. Our results demonstrate that employing latent representations yields enhanced performance compared to conventional behavior cloning methods, particularly regarding resilience to errors and noise in perception and proprioception. Furthermore, the proposed approach solely relies on human demonstrations, eliminating the need for teleoperation and, therefore, accelerating the data acquisition process. Accurate inverse kinematics for fingertip retargeting ensures precise transfer from human hand data to the robot, facilitating effective learning and deployment of manipulation policies. Finally, the trained policies have been successfully transferred to a real-world 23Dof robotic system.
4/26/2024
🤿
Behavior Imitation for Manipulator Control and Grasping with Deep Reinforcement Learning
Liu Qiyuan
0
0
The existing Motion Imitation models typically require expert data obtained through MoCap devices, but the vast amount of training data needed is difficult to acquire, necessitating substantial investments of financial resources, manpower, and time. This project combines 3D human pose estimation with reinforcement learning, proposing a novel model that simplifies Motion Imitation into a prediction problem of joint angle values in reinforcement learning. This significantly reduces the reliance on vast amounts of training data, enabling the agent to learn an imitation policy from just a few seconds of video and exhibit strong generalization capabilities. It can quickly apply the learned policy to imitate human arm motions in unfamiliar videos. The model first extracts skeletal motions of human arms from a given video using 3D human pose estimation. These extracted arm motions are then morphologically retargeted onto a robotic manipulator. Subsequently, the retargeted motions are used to generate reference motions. Finally, these reference motions are used to formulate a reinforcement learning problem, enabling the agent to learn a policy for imitating human arm motions. This project excels at imitation tasks and demonstrates robust transferability, accurately imitating human arm motions from other unfamiliar videos. This project provides a lightweight, convenient, efficient, and accurate Motion Imitation model. While simplifying the complex process of Motion Imitation, it achieves notably outstanding performance.
5/3/2024
🐍
Learning Extrinsic Dexterity with Parameterized Manipulation Primitives
Shih-Min Yang, Martin Magnusson, Johannes A. Stork, Todor Stoyanov
0
0
Many practically relevant robot grasping problems feature a target object for which all grasps are occluded, e.g., by the environment. Single-shot grasp planning invariably fails in such scenarios. Instead, it is necessary to first manipulate the object into a configuration that affords a grasp. We solve this problem by learning a sequence of actions that utilize the environment to change the object's pose. Concretely, we employ hierarchical reinforcement learning to combine a sequence of learned parameterized manipulation primitives. By learning the low-level manipulation policies, our approach can control the object's state through exploiting interactions between the object, the gripper, and the environment. Designing such a complex behavior analytically would be infeasible under uncontrolled conditions, as an analytic approach requires accurate physical modeling of the interaction and contact dynamics. In contrast, we learn a hierarchical policy model that operates directly on depth perception data, without the need for object detection, pose estimation, or manual design of controllers. We evaluate our approach on picking box-shaped objects of various weight, shape, and friction properties from a constrained table-top workspace. Our method transfers to a real robot and is able to successfully complete the object picking task in 98% of experimental trials. Supplementary information and videos can be found at https://shihminyang.github.io/ED-PMP/.
5/10/2024
👁️
ScrewMimic: Bimanual Imitation from Human Videos with Screw Space Projection
Arpit Bahety, Priyanka Mandikal, Ben Abbatematteo, Roberto Mart'in-Mart'in
0
0
Bimanual manipulation is a longstanding challenge in robotics due to the large number of degrees of freedom and the strict spatial and temporal synchronization required to generate meaningful behavior. Humans learn bimanual manipulation skills by watching other humans and by refining their abilities through play. In this work, we aim to enable robots to learn bimanual manipulation behaviors from human video demonstrations and fine-tune them through interaction. Inspired by seminal work in psychology and biomechanics, we propose modeling the interaction between two hands as a serial kinematic linkage -- as a screw motion, in particular, that we use to define a new action space for bimanual manipulation: screw actions. We introduce ScrewMimic, a framework that leverages this novel action representation to facilitate learning from human demonstration and self-supervised policy fine-tuning. Our experiments demonstrate that ScrewMimic is able to learn several complex bimanual behaviors from a single human video demonstration, and that it outperforms baselines that interpret demonstrations and fine-tune directly in the original space of motion of both arms. For more information and video results, https://robin-lab.cs.utexas.edu/ScrewMimic/
5/7/2024