Learning to solve Bayesian inverse problems: An amortized variational inference approach using Gaussian and Flow guides
2305.20004
0
0
🤯
Abstract
Inverse problems, i.e., estimating parameters of physical models from experimental data, are ubiquitous in science and engineering. The Bayesian formulation is the gold standard because it alleviates ill-posedness issues and quantifies epistemic uncertainty. Since analytical posteriors are not typically available, one resorts to Markov chain Monte Carlo sampling or approximate variational inference. However, inference needs to be rerun from scratch for each new set of data. This drawback limits the applicability of the Bayesian formulation to real-time settings, e.g., health monitoring of engineered systems, and medical diagnosis. The objective of this paper is to develop a methodology that enables real-time inference by learning the Bayesian inverse map, i.e., the map from data to posteriors. Our approach is as follows. We parameterize the posterior distribution as a function of data. This work outlines two distinct approaches to do this. The first method involves parameterizing the posterior using an amortized full-rank Gaussian guide, implemented through neural networks. The second method utilizes a Conditional Normalizing Flow guide, employing conditional invertible neural networks for cases where the target posterior is arbitrarily complex. In both approaches, we learn the network parameters by amortized variational inference which involves maximizing the expectation of evidence lower bound over all possible datasets compatible with the model. We demonstrate our approach by solving a set of benchmark problems from science and engineering. Our results show that the posterior estimates of our approach are in agreement with the corresponding ground truth obtained by Markov chain Monte Carlo. Once trained, our approach provides the posterior distribution for a given observation just at the cost of a forward pass of the neural network.
Create account to get full access
Overview
- Inverse problems involve estimating parameters of physical models from experimental data, which is a common challenge in science and engineering.
- The Bayesian formulation is the standard approach, as it addresses issues with ill-posedness and quantifies uncertainty.
- However, traditional Bayesian inference methods like Markov chain Monte Carlo or variational inference require rerunning the entire process for each new dataset, limiting their usefulness in real-time settings.
- This paper proposes a methodology to enable real-time Bayesian inference by learning the mapping from data to posterior distributions.
Plain English Explanation
In many areas of science and engineering, researchers need to estimate the parameters of physical models based on experimental data. This type of problem is known as an "inverse problem." The gold standard approach for solving inverse problems is the Bayesian formulation, which helps address issues with ill-posedness and quantifies the uncertainty in the estimates.
However, the traditional methods for implementing Bayesian inference, such as Markov chain Monte Carlo or variational inference, have a major drawback: they need to be run from scratch for each new set of data. This makes them impractical for real-time applications, like monitoring the health of engineered systems or medical diagnosis.
The goal of this paper is to develop a new methodology that allows for real-time Bayesian inference. The key idea is to learn the mapping from data to the posterior distribution, so that once the mapping is learned, the posterior can be obtained instantly for any new data, without needing to rerun the full inference process.
Technical Explanation
The paper proposes two distinct approaches for learning this "Bayesian inverse map":
-
Amortized Full-Rank Gaussian: The posterior distribution is parameterized as a full-rank Gaussian, with the parameters (mean and covariance) being learned as functions of the input data using neural networks.
-
Conditional Normalizing Flow: For cases where the target posterior distribution is more complex, a conditional normalizing flow model is used. This employs conditional invertible neural networks to learn a flexible mapping from data to the posterior.
In both approaches, the network parameters are learned through amortized variational inference, which involves maximizing the expected evidence lower bound over all possible datasets compatible with the model.
The paper demonstrates the effectiveness of these approaches on a variety of benchmark problems from science and engineering. The results show that the posterior estimates closely match those obtained from traditional Markov chain Monte Carlo methods, but can be computed orders of magnitude faster once the neural networks are trained.
Critical Analysis
The paper presents a promising approach for enabling real-time Bayesian inference, which could have significant practical implications in fields like engineering, healthcare, and beyond. However, a few potential limitations and areas for further research are worth noting:
- The paper focuses on relatively low-dimensional problems; scaling the approach to high-dimensional settings may require additional innovations.
- The training process for the neural networks can be computationally expensive, though the inference time is fast once the networks are trained.
- The paper does not explore the robustness of the approach to model misspecification or outliers in the data, which are common challenges in real-world applications.
Overall, this research represents an important step forward in making Bayesian inference more practical and accessible for real-time applications. Further work is needed to fully understand the limitations and potential extensions of this approach.
Conclusion
This paper proposes a novel methodology for enabling real-time Bayesian inference by learning the mapping from data to posterior distributions. The key idea is to parameterize the posterior using neural networks, which can then be used to quickly compute the posterior for any new data, without needing to rerun the full inference process.
The paper demonstrates the effectiveness of this approach on a variety of benchmark problems, showing that the posterior estimates are in close agreement with traditional Markov chain Monte Carlo methods, but can be computed orders of magnitude faster once the neural networks are trained.
This research has the potential to significantly expand the practical applicability of Bayesian methods, enabling their use in real-time settings like health monitoring, medical diagnosis, and beyond. Further work is needed to fully understand the limitations and potential extensions of this approach, but it represents an important step forward in the field of inverse problems and Bayesian inference.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
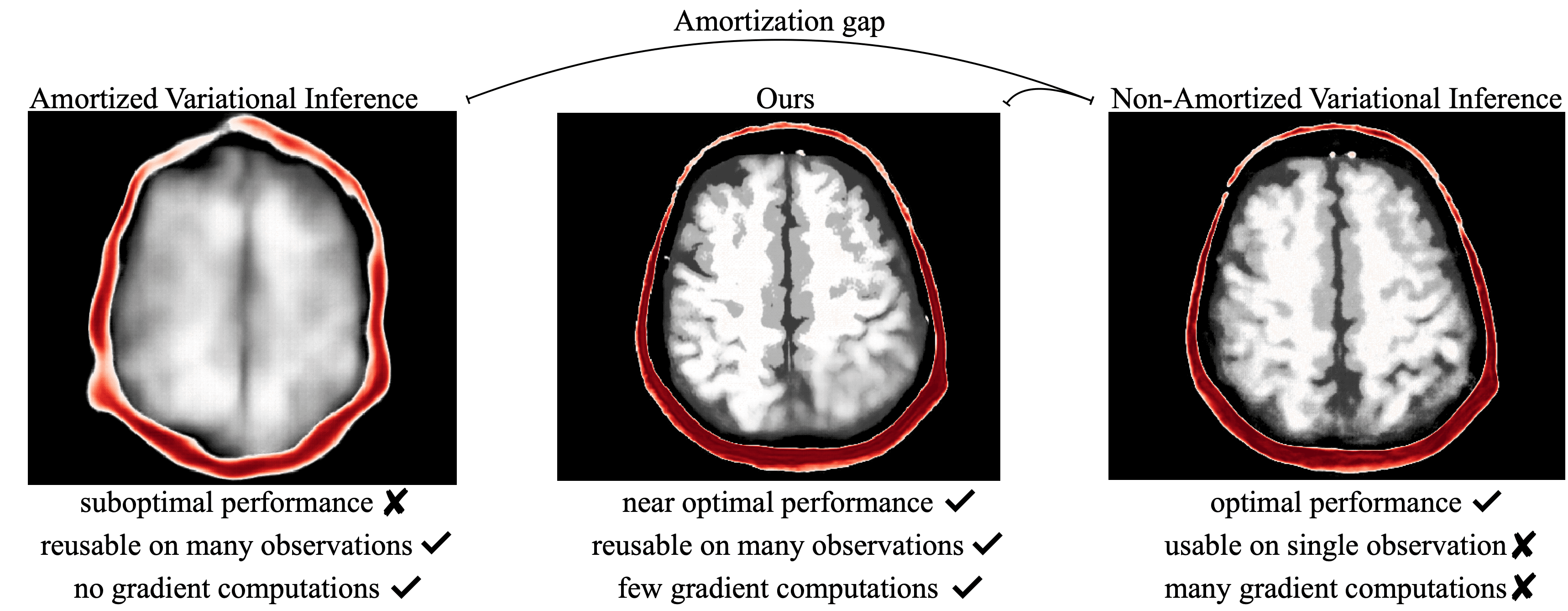
ASPIRE: Iterative Amortized Posterior Inference for Bayesian Inverse Problems
Rafael Orozco, Ali Siahkoohi, Mathias Louboutin, Felix J. Herrmann
0
0
Due to their uncertainty quantification, Bayesian solutions to inverse problems are the framework of choice in applications that are risk averse. These benefits come at the cost of computations that are in general, intractable. New advances in machine learning and variational inference (VI) have lowered the computational barrier by learning from examples. Two VI paradigms have emerged that represent different tradeoffs: amortized and non-amortized. Amortized VI can produce fast results but due to generalizing to many observed datasets it produces suboptimal inference results. Non-amortized VI is slower at inference but finds better posterior approximations since it is specialized towards a single observed dataset. Current amortized VI techniques run into a sub-optimality wall that can not be improved without more expressive neural networks or extra training data. We present a solution that enables iterative improvement of amortized posteriors that uses the same networks architectures and training data. The benefits of our method requires extra computations but these remain frugal since they are based on physics-hybrid methods and summary statistics. Importantly, these computations remain mostly offline thus our method maintains cheap and reusable online evaluation while bridging the approximation gap these two paradigms. We denote our proposed method ASPIRE - Amortized posteriors with Summaries that are Physics-based and Iteratively REfined. We first validate our method on a stylized problem with a known posterior then demonstrate its practical use on a high-dimensional and nonlinear transcranial medical imaging problem with ultrasound. Compared with the baseline and previous methods from the literature our method stands out as an computationally efficient and high-fidelity method for posterior inference.
5/10/2024
Efficient Prior Calibration From Indirect Data
O. Deniz Akyildiz, Mark Girolami, Andrew M. Stuart, Arnaud Vadeboncoeur
0
0
Bayesian inversion is central to the quantification of uncertainty within problems arising from numerous applications in science and engineering. To formulate the approach, four ingredients are required: a forward model mapping the unknown parameter to an element of a solution space, often the solution space for a differential equation; an observation operator mapping an element of the solution space to the data space; a noise model describing how noise pollutes the observations; and a prior model describing knowledge about the unknown parameter before the data is acquired. This paper is concerned with learning the prior model from data; in particular, learning the prior from multiple realizations of indirect data obtained through the noisy observation process. The prior is represented, using a generative model, as the pushforward of a Gaussian in a latent space; the pushforward map is learned by minimizing an appropriate loss function. A metric that is well-defined under empirical approximation is used to define the loss function for the pushforward map to make an implementable methodology. Furthermore, an efficient residual-based neural operator approximation of the forward model is proposed and it is shown that this may be learned concurrently with the pushforward map, using a bilevel optimization formulation of the problem; this use of neural operator approximation has the potential to make prior learning from indirect data more computationally efficient, especially when the observation process is expensive, non-smooth or not known. The ideas are illustrated with the Darcy flow inverse problem of finding permeability from piezometric head measurements.
5/29/2024
🧠
Neural Methods for Amortised Parameter Inference
Andrew Zammit-Mangion, Matthew Sainsbury-Dale, Raphael Huser
0
0
Simulation-based methods for statistical inference have evolved dramatically over the past 50 years, keeping pace with technological advancements. The field is undergoing a new revolution as it embraces the representational capacity of neural networks, optimisation libraries and graphics processing units for learning complex mappings between data and inferential targets. The resulting tools are amortised, in the sense that they allow rapid inference through fast feedforward operations. In this article we review recent progress in the context of point estimation, approximate Bayesian inference, summary-statistic construction, and likelihood approximation. We also cover software, and include a simple illustration to showcase the wide array of tools available for amortised inference and the benefits they offer over Markov chain Monte Carlo methods. The article concludes with an overview of relevant topics and an outlook on future research directions.
6/27/2024
✨
Amortized Variational Inference: When and Why?
Charles C. Margossian, David M. Blei
0
0
In a probabilistic latent variable model, factorized (or mean-field) variational inference (F-VI) fits a separate parametric distribution for each latent variable. Amortized variational inference (A-VI) instead learns a common inference function, which maps each observation to its corresponding latent variable's approximate posterior. Typically, A-VI is used as a step in the training of variational autoencoders, however it stands to reason that A-VI could also be used as a general alternative to F-VI. In this paper we study when and why A-VI can be used for approximate Bayesian inference. We derive conditions on a latent variable model which are necessary, sufficient, and verifiable under which A-VI can attain F-VI's optimal solution, thereby closing the amortization gap. We prove these conditions are uniquely verified by simple hierarchical models, a broad class that encompasses many models in machine learning. We then show, on a broader class of models, how to expand the domain of AVI's inference function to improve its solution, and we provide examples, e.g. hidden Markov models, where the amortization gap cannot be closed.
5/27/2024