A Literature Review and Framework for Human Evaluation of Generative Large Language Models in Healthcare
2405.02559
0
0
💬
Abstract
As generative artificial intelligence (AI), particularly Large Language Models (LLMs), continues to permeate healthcare, it remains crucial to supplement traditional automated evaluations with human expert evaluation. Understanding and evaluating the generated texts is vital for ensuring safety, reliability, and effectiveness. However, the cumbersome, time-consuming, and non-standardized nature of human evaluation presents significant obstacles to the widespread adoption of LLMs in practice. This study reviews existing literature on human evaluation methodologies for LLMs within healthcare. We highlight a notable need for a standardized and consistent human evaluation approach. Our extensive literature search, adhering to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines, spans publications from January 2018 to February 2024. This review provides a comprehensive overview of the human evaluation approaches used in diverse healthcare applications.This analysis examines the human evaluation of LLMs across various medical specialties, addressing factors such as evaluation dimensions, sample types, and sizes, the selection and recruitment of evaluators, frameworks and metrics, the evaluation process, and statistical analysis of the results. Drawing from diverse evaluation strategies highlighted in these studies, we propose a comprehensive and practical framework for human evaluation of generative LLMs, named QUEST: Quality of Information, Understanding and Reasoning, Expression Style and Persona, Safety and Harm, and Trust and Confidence. This framework aims to improve the reliability, generalizability, and applicability of human evaluation of generative LLMs in different healthcare applications by defining clear evaluation dimensions and offering detailed guidelines.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper reviews the existing literature on human evaluation methodologies for large language models (LLMs) in healthcare applications.
- The authors highlight the need for a standardized and consistent approach to human evaluation, as the current methods are often cumbersome, time-consuming, and non-standardized.
- The review covers various aspects of human evaluation, including evaluation dimensions, sample types and sizes, evaluator selection and recruitment, frameworks and metrics, the evaluation process, and statistical analysis.
- The authors propose a comprehensive framework called QUEST (Quality of Information, Understanding and Reasoning, Expression Style and Persona, Safety and Harm, and Trust and Confidence) to improve the reliability, generalizability, and applicability of human evaluation of generative LLMs in healthcare.
Plain English Explanation
As generative AI and LLMs become more widely used in healthcare, it's crucial to have human experts evaluate the generated texts in addition to automated evaluations. This helps ensure the safety, reliability, and effectiveness of these AI systems. However, the current human evaluation methods can be time-consuming and inconsistent, which makes it difficult to widely adopt LLMs in healthcare.
This study reviews the existing research on how humans evaluate LLMs in healthcare. The authors found that there is a need for a standardized and consistent approach to human evaluation. They looked at studies published from 2018 to 2024 and examined how these evaluations were conducted, including factors like the types of medical specialties, the dimensions used to evaluate the LLMs, the selection of evaluators, and the statistical analysis of the results.
Based on the diverse evaluation strategies used in these studies, the authors propose a new framework called QUEST. This framework covers five key areas: Quality of Information, Understanding and Reasoning, Expression Style and Persona, Safety and Harm, and Trust and Confidence. The goal is to make human evaluation of generative LLMs in healthcare more reliable, consistent, and applicable across different medical applications.
Technical Explanation
The paper reviews the existing literature on human evaluation methodologies for large language models (LLMs) in healthcare applications. The authors conducted an extensive literature search, following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines, to identify relevant studies published from January 2018 to February 2024.
The review examines the human evaluation of LLMs across various medical specialties, addressing factors such as:
- Evaluation dimensions: The specific aspects of the LLMs that are evaluated, such as the quality of information, understanding and reasoning, expression style and persona, safety and harm, and trust and confidence.
- Sample types and sizes: The types of medical texts or tasks used for evaluation and the number of samples evaluated.
- Evaluator selection and recruitment: How the human evaluators were chosen and their expertise or background.
- Frameworks and metrics: The evaluation frameworks and metrics used to assess the LLM performance.
- Evaluation process: The specific steps and procedures involved in the human evaluation.
- Statistical analysis: The methods used to analyze the results of the human evaluation.
Drawing from the diverse evaluation strategies highlighted in these studies, the authors propose the QUEST framework as a comprehensive and practical approach for human evaluation of generative LLMs in healthcare. This framework aims to improve the reliability, generalizability, and applicability of human evaluation by defining clear evaluation dimensions and offering detailed guidelines.
Critical Analysis
The paper's strength lies in its comprehensive review of the existing literature on human evaluation methodologies for LLMs in healthcare. The authors have identified a significant need for a standardized and consistent approach, which is a crucial step in ensuring the safe and effective deployment of these AI systems in the healthcare domain.
One potential limitation of the study is the relatively short time frame of the literature review, which only covers publications from 2018 to 2024. While this is understandable given the rapid pace of development in this field, it may have overlooked earlier or relevant works that could have provided additional insights.
Additionally, the authors do not delve into the potential biases or limitations inherent in human evaluation, which could be an area for further exploration. The proposed QUEST framework, while comprehensive, may also benefit from empirical validation and refinement based on real-world deployments and feedback from healthcare practitioners.
Moreover, the paper does not address the potential challenges in implementing a standardized human evaluation approach, such as the resources and expertise required, the integration with existing healthcare workflows, and the potential resistance to change from healthcare professionals.
Despite these minor limitations, the paper provides a valuable contribution to the field by highlighting the importance of human evaluation in the context of LLMs in healthcare and proposing a promising framework to address the current challenges.
Conclusion
This paper reviews the existing literature on human evaluation methodologies for large language models (LLMs) in healthcare applications. The authors identify a significant need for a standardized and consistent approach to human evaluation, as the current methods are often cumbersome, time-consuming, and non-standardized.
The proposed QUEST framework aims to improve the reliability, generalizability, and applicability of human evaluation of generative LLMs in healthcare. By defining clear evaluation dimensions and offering detailed guidelines, the QUEST framework has the potential to facilitate the safe and effective deployment of LLMs in various medical specialties.
Overall, this study provides a valuable contribution to the field by highlighting the importance of human evaluation in the context of LLMs in healthcare and proposing a comprehensive framework to address the current challenges in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Evaluating large language models in medical applications: a survey
Xiaolan Chen, Jiayang Xiang, Shanfu Lu, Yexin Liu, Mingguang He, Danli Shi
0
0
Large language models (LLMs) have emerged as powerful tools with transformative potential across numerous domains, including healthcare and medicine. In the medical domain, LLMs hold promise for tasks ranging from clinical decision support to patient education. However, evaluating the performance of LLMs in medical contexts presents unique challenges due to the complex and critical nature of medical information. This paper provides a comprehensive overview of the landscape of medical LLM evaluation, synthesizing insights from existing studies and highlighting evaluation data sources, task scenarios, and evaluation methods. Additionally, it identifies key challenges and opportunities in medical LLM evaluation, emphasizing the need for continued research and innovation to ensure the responsible integration of LLMs into clinical practice.
5/14/2024
💬
A Comprehensive Survey on Evaluating Large Language Model Applications in the Medical Industry
Yining Huang, Keke Tang, Meilian Chen
0
0
Since the inception of the Transformer architecture in 2017, Large Language Models (LLMs) such as GPT and BERT have evolved significantly, impacting various industries with their advanced capabilities in language understanding and generation. These models have shown potential to transform the medical field, highlighting the necessity for specialized evaluation frameworks to ensure their effective and ethical deployment. This comprehensive survey delineates the extensive application and requisite evaluation of LLMs within healthcare, emphasizing the critical need for empirical validation to fully exploit their capabilities in enhancing healthcare outcomes. Our survey is structured to provide an in-depth analysis of LLM applications across clinical settings, medical text data processing, research, education, and public health awareness. We begin by exploring the roles of LLMs in different medical applications, detailing how they are evaluated based on their performance in tasks such as clinical application, medical text data processing, information retrieval, data analysis, medical scientific writing, educational content generation etc. The subsequent sections delve into the methodologies employed in these evaluations, discussing the benchmarks and metrics used to assess the models' effectiveness, accuracy, and ethical alignment. Through this survey, we aim to equip healthcare professionals, researchers, and policymakers with a comprehensive understanding of the potential strengths and limitations of LLMs in medical applications. By providing detailed insights into the evaluation processes and the challenges faced in integrating LLMs into healthcare, this survey seeks to guide the responsible development and deployment of these powerful models, ensuring they are harnessed to their full potential while maintaining stringent ethical standards.
5/7/2024
💬
A scoping review of using Large Language Models (LLMs) to investigate Electronic Health Records (EHRs)
Lingyao Li, Jiayan Zhou, Zhenxiang Gao, Wenyue Hua, Lizhou Fan, Huizi Yu, Loni Hagen, Yonfeng Zhang, Themistocles L. Assimes, Libby Hemphill, Siyuan Ma
0
0
Electronic Health Records (EHRs) play an important role in the healthcare system. However, their complexity and vast volume pose significant challenges to data interpretation and analysis. Recent advancements in Artificial Intelligence (AI), particularly the development of Large Language Models (LLMs), open up new opportunities for researchers in this domain. Although prior studies have demonstrated their potential in language understanding and processing in the context of EHRs, a comprehensive scoping review is lacking. This study aims to bridge this research gap by conducting a scoping review based on 329 related papers collected from OpenAlex. We first performed a bibliometric analysis to examine paper trends, model applications, and collaboration networks. Next, we manually reviewed and categorized each paper into one of the seven identified topics: named entity recognition, information extraction, text similarity, text summarization, text classification, dialogue system, and diagnosis and prediction. For each topic, we discussed the unique capabilities of LLMs, such as their ability to understand context, capture semantic relations, and generate human-like text. Finally, we highlighted several implications for researchers from the perspectives of data resources, prompt engineering, fine-tuning, performance measures, and ethical concerns. In conclusion, this study provides valuable insights into the potential of LLMs to transform EHR research and discusses their applications and ethical considerations.
5/7/2024
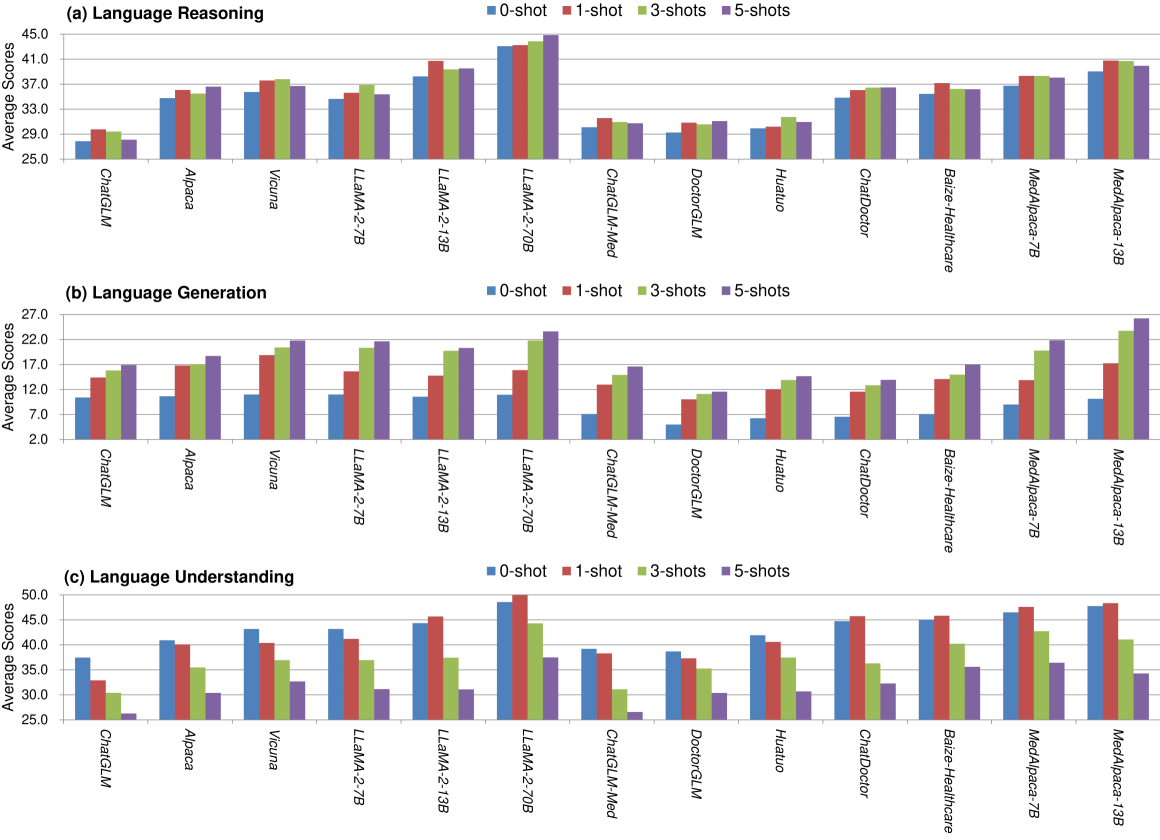
Large Language Models in Healthcare: A Comprehensive Benchmark
Andrew Liu, Hongjian Zhou, Yining Hua, Omid Rohanian, Lei Clifton, David A. Clifton
0
0
The adoption of large language models (LLMs) to assist clinicians has attracted remarkable attention. Existing works mainly adopt the close-ended question-answering task with answer options for evaluation. However, in real clinical settings, many clinical decisions, such as treatment recommendations, involve answering open-ended questions without pre-set options. Meanwhile, existing studies mainly use accuracy to assess model performance. In this paper, we comprehensively benchmark diverse LLMs in healthcare, to clearly understand their strengths and weaknesses. Our benchmark contains seven tasks and thirteen datasets across medical language generation, understanding, and reasoning. We conduct a detailed evaluation of the existing sixteen LLMs in healthcare under both zero-shot and few-shot (i.e., 1,3,5-shot) learning settings. We report the results on five metrics (i.e. matching, faithfulness, comprehensiveness, generalizability, and robustness) that are critical in achieving trust from clinical users. We further invite medical experts to conduct human evaluation.
5/3/2024