LyS at SemEval-2024 Task 3: An Early Prototype for End-to-End Multimodal Emotion Linking as Graph-Based Parsing
2405.06483
0
0
🔄
Abstract
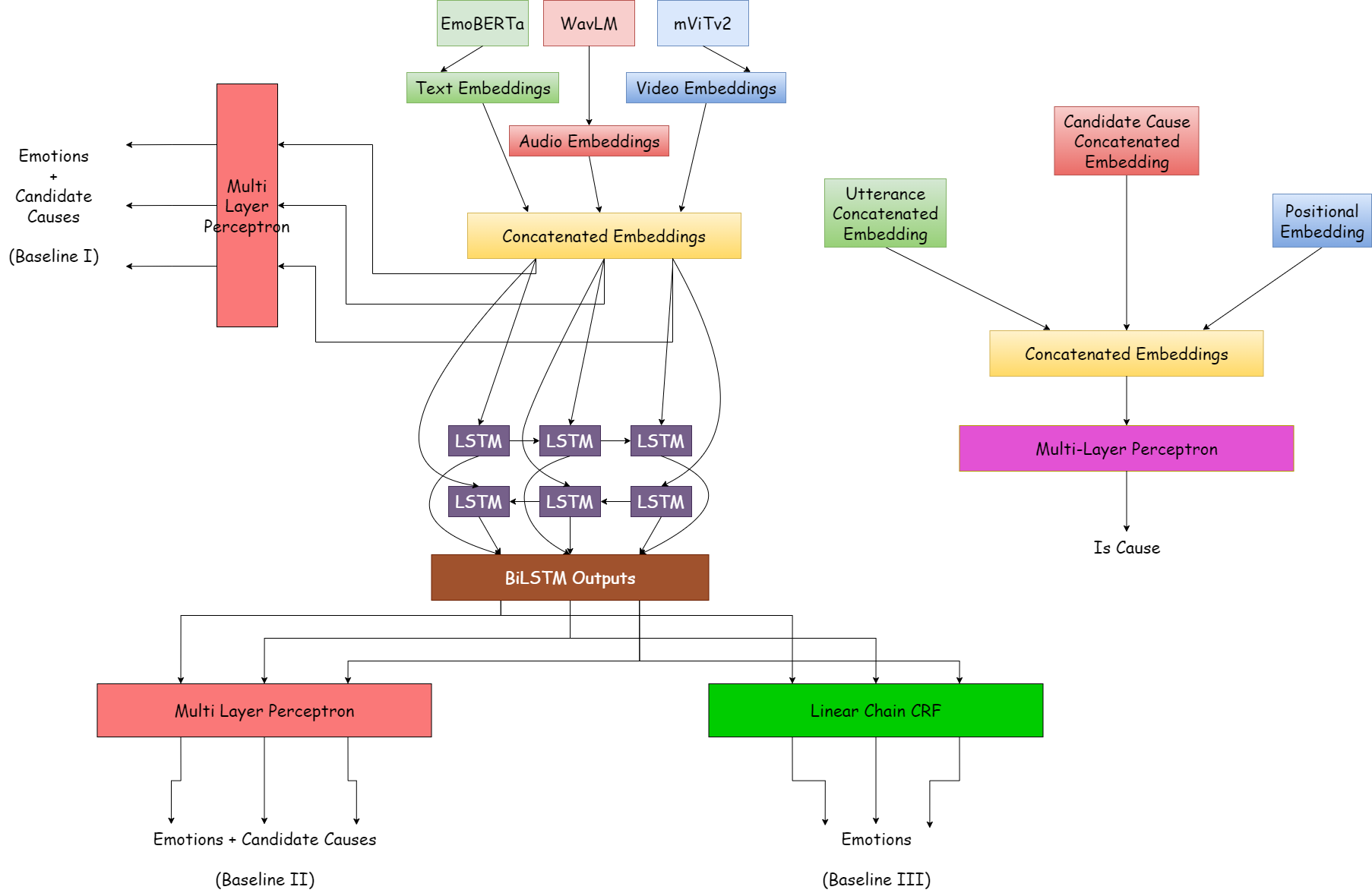
This paper describes our participation in SemEval 2024 Task 3, which focused on Multimodal Emotion Cause Analysis in Conversations. We developed an early prototype for an end-to-end system that uses graph-based methods from dependency parsing to identify causal emotion relations in multi-party conversations. Our model comprises a neural transformer-based encoder for contextualizing multimodal conversation data and a graph-based decoder for generating the adjacency matrix scores of the causal graph. We ranked 7th out of 15 valid and official submissions for Subtask 1, using textual inputs only. We also discuss our participation in Subtask 2 during post-evaluation using multi-modal inputs.
Create account to get full access
Overview
- The paper describes the authors' participation in SemEval 2024 Task 3, which focused on Multimodal Emotion Cause Analysis in Conversations.
- The authors developed an early prototype for an end-to-end system that uses graph-based methods from dependency parsing to identify causal emotion relations in multi-party conversations.
- The model comprises a neural transformer-based encoder for contextualizing multimodal conversation data and a graph-based decoder for generating the adjacency matrix scores of the causal graph.
- The authors ranked 7th out of 15 valid and official submissions for Subtask 1, using textual inputs only, and also discuss their participation in Subtask 2 during post-evaluation using multi-modal inputs.
Plain English Explanation
The paper discusses the authors' work on a system that aims to analyze the causes of emotions in multi-party conversations. The system uses a combination of natural language processing techniques, such as dependency parsing, and machine learning models to identify the relationships between emotions and their underlying causes in conversational data.
The authors developed a prototype of this system and tested it as part of the SemEval 2024 Task 3 competition, which focused on this specific challenge. Their model was able to achieve a 7th place ranking out of 15 valid submissions when using only textual information. The authors also explored the use of multimodal data, such as audio and visual cues, during the post-evaluation phase of the competition.
The key idea behind the authors' approach is to use a graph-based method to represent the causal relationships between emotions and their triggers in a conversation. This allows the system to capture the complex, interconnected nature of emotional responses and their underlying causes in a more nuanced way than traditional text-only analysis.
Technical Explanation
The authors' system uses a neural transformer-based encoder to contextualize the multimodal conversation data, which includes textual, audio, and visual information. This encoder generates a rich representation of the conversation that captures the relevant features for identifying causal emotion relations.
The encoder's output is then fed into a graph-based decoder, which generates the adjacency matrix scores of the causal graph. This graph-based approach allows the system to model the complex, interconnected nature of emotions and their causes in a conversation, rather than treating them as isolated events.
The authors' model was evaluated on the SemEval 2024 Task 3 dataset, which includes multi-party conversations annotated with causal emotion relations. For Subtask 1, the authors' system ranked 7th out of 15 valid and official submissions using only textual inputs. The authors also explored the use of multimodal data, including audio and visual cues, during the post-evaluation phase of the competition.
Critical Analysis
The authors acknowledge that their system is an early prototype and that further research and development is needed to fully address the challenges of Multimodal Emotion Cause Analysis in Conversations. One potential limitation of the current approach is the reliance on graph-based methods, which may not be able to capture all the nuances of emotional causality in complex, multi-party dialogues.
Additionally, the authors' focus on textual inputs in the main evaluation, with only a brief exploration of multimodal data during post-evaluation, suggests that there may be room for improvement in incorporating and leveraging the full range of available information sources.
Future research could explore alternative modeling approaches, such as semantic-aware emotion cause analysis or knowledge-guided multimodal fusion, to further enhance the system's ability to understand and reason about the complex emotional dynamics in multi-party conversations.
Conclusion
The authors' work on an early prototype for Multimodal Emotion Cause Analysis in Conversations represents an important step forward in the field of natural language processing and affective computing. By leveraging graph-based methods and multimodal data, the authors have demonstrated the potential for developing more sophisticated systems that can better understand the underlying causes of emotions in complex, real-world dialogues.
While further research and development is needed to fully address the challenges of this task, the authors' work provides a solid foundation for continued exploration and advancement in this important area of affective computing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
SemEval-2024 Task 3: Multimodal Emotion Cause Analysis in Conversations
Fanfan Wang, Heqing Ma, Jianfei Yu, Rui Xia, Erik Cambria
0
0
The ability to understand emotions is an essential component of human-like artificial intelligence, as emotions greatly influence human cognition, decision making, and social interactions. In addition to emotion recognition in conversations, the task of identifying the potential causes behind an individual's emotional state in conversations, is of great importance in many application scenarios. We organize SemEval-2024 Task 3, named Multimodal Emotion Cause Analysis in Conversations, which aims at extracting all pairs of emotions and their corresponding causes from conversations. Under different modality settings, it consists of two subtasks: Textual Emotion-Cause Pair Extraction in Conversations (TECPE) and Multimodal Emotion-Cause Pair Extraction in Conversations (MECPE). The shared task has attracted 143 registrations and 216 successful submissions. In this paper, we introduce the task, dataset and evaluation settings, summarize the systems of the top teams, and discuss the findings of the participants.
6/12/2024

PetKaz at SemEval-2024 Task 3: Advancing Emotion Classification with an LLM for Emotion-Cause Pair Extraction in Conversations
Roman Kazakov, Kseniia Petukhova, Ekaterina Kochmar
0
0
In this paper, we present our submission to the SemEval-2023 Task~3 The Competition of Multimodal Emotion Cause Analysis in Conversations, focusing on extracting emotion-cause pairs from dialogs. Specifically, our approach relies on combining fine-tuned GPT-3.5 for emotion classification and a BiLSTM-based neural network to detect causes. We score 2nd in the ranking for Subtask 1, demonstrating the effectiveness of our approach through one of the highest weighted-average proportional F1 scores recorded at 0.264.
4/9/2024
LastResort at SemEval-2024 Task 3: Exploring Multimodal Emotion Cause Pair Extraction as Sequence Labelling Task
Suyash Vardhan Mathur, Akshett Rai Jindal, Hardik Mittal, Manish Shrivastava
0
0
Conversation is the most natural form of human communication, where each utterance can range over a variety of possible emotions. While significant work has been done towards the detection of emotions in text, relatively little work has been done towards finding the cause of the said emotions, especially in multimodal settings. SemEval 2024 introduces the task of Multimodal Emotion Cause Analysis in Conversations, which aims to extract emotions reflected in individual utterances in a conversation involving multiple modalities (textual, audio, and visual modalities) along with the corresponding utterances that were the cause for the emotion. In this paper, we propose models that tackle this task as an utterance labeling and a sequence labeling problem and perform a comparative study of these models, involving baselines using different encoders, using BiLSTM for adding contextual information of the conversation, and finally adding a CRF layer to try to model the inter-dependencies between adjacent utterances more effectively. In the official leaderboard for the task, our architecture was ranked 8th, achieving an F1-score of 0.1759 on the leaderboard.
4/3/2024

Samsung Research China-Beijing at SemEval-2024 Task 3: A multi-stage framework for Emotion-Cause Pair Extraction in Conversations
Shen Zhang, Haojie Zhang, Jing Zhang, Xudong Zhang, Yimeng Zhuang, Jinting Wu
0
0
In human-computer interaction, it is crucial for agents to respond to human by understanding their emotions. Unraveling the causes of emotions is more challenging. A new task named Multimodal Emotion-Cause Pair Extraction in Conversations is responsible for recognizing emotion and identifying causal expressions. In this study, we propose a multi-stage framework to generate emotion and extract the emotion causal pairs given the target emotion. In the first stage, Llama-2-based InstructERC is utilized to extract the emotion category of each utterance in a conversation. After emotion recognition, a two-stream attention model is employed to extract the emotion causal pairs given the target emotion for subtask 2 while MuTEC is employed to extract causal span for subtask 1. Our approach achieved first place for both of the two subtasks in the competition.
4/29/2024