Magnitude-based Neuron Pruning for Backdoor Defens
2405.17750
0
0

Abstract
Deep Neural Networks (DNNs) are known to be vulnerable to backdoor attacks, posing concerning threats to their reliable deployment. Recent research reveals that backdoors can be erased from infected DNNs by pruning a specific group of neurons, while how to effectively identify and remove these backdoor-associated neurons remains an open challenge. In this paper, we investigate the correlation between backdoor behavior and neuron magnitude, and find that backdoor neurons deviate from the magnitude-saliency correlation of the model. The deviation inspires us to propose a Magnitude-based Neuron Pruning (MNP) method to detect and prune backdoor neurons. Specifically, MNP uses three magnitude-guided objective functions to manipulate the magnitude-saliency correlation of backdoor neurons, thus achieving the purpose of exposing backdoor behavior, eliminating backdoor neurons and preserving clean neurons, respectively. Experiments show our pruning strategy achieves state-of-the-art backdoor defense performance against a variety of backdoor attacks with a limited amount of clean data, demonstrating the crucial role of magnitude for guiding backdoor defenses.
Create account to get full access
Overview
- This paper proposes a technique called "Magnitude-based Neuron Pruning" to defend against backdoor attacks on deep neural networks.
- Backdoor attacks are a type of security threat where an attacker can cause a model to misclassify specific "trigger" inputs while maintaining normal performance on regular inputs.
- The key idea is to identify and remove the most important neurons responsible for the backdoor trigger, reducing the model's vulnerability without significantly impacting its overall performance.
Plain English Explanation
The paper introduces a method to help protect deep learning models from a type of security threat called a "backdoor attack". In a backdoor attack, an attacker can sneak in a hidden vulnerability that causes the model to make mistakes on certain types of inputs, while still performing well on normal data.
The researchers' approach is to identify and remove the most important neurons in the model that are responsible for this backdoor trigger. By pruning away these key neurons, they can reduce the model's vulnerability to the backdoor attack, without substantially impacting its overall accuracy on regular inputs.
This is like finding and removing a specific weak point in a lock that an intruder might try to exploit, while keeping the lock itself largely intact and functional. The goal is to make it much harder for an attacker to take advantage of the backdoor, while preserving the model's useful capabilities.
Technical Explanation
The paper proposes a "Magnitude-based Neuron Pruning" technique to defend against backdoor attacks. The key steps are:
- Train the model normally on the target task.
- Identify the neurons most important for the backdoor trigger using a "neuron importance score" based on the magnitude of each neuron's weights.
- Prune away the top-k% of these important neurons, effectively removing the backdoor vulnerability.
- Fine-tune the pruned model to recover any lost performance on the main task.
The experiments show this approach can significantly reduce the model's susceptibility to backdoor attacks, with only a small drop in clean-data accuracy. The authors also demonstrate the technique's effectiveness against different types of backdoor triggers.
Critical Analysis
The paper provides a promising defense against backdoor attacks, but a few potential limitations are worth noting:
- The method assumes the attacker's trigger pattern is known or can be inferred, which may not always be the case in real-world scenarios. [link to related work on universal triggers]
- Pruning a large number of neurons could still impact the model's core functionality, even with fine-tuning. The authors acknowledge this tradeoff.
- The proposed approach may be less effective against more sophisticated backdoor attacks that are robust to neuron pruning. [link to work on gradient-based backdoor unlearning]
Overall, this work represents an important step in the ongoing arms race between attackers and defenders in the field of machine learning security. Continued research is needed to develop comprehensive solutions that can withstand a variety of evolving backdoor threats.
Conclusion
This paper introduces a novel neuron pruning technique to help defend deep learning models against backdoor attacks - a serious security vulnerability where an attacker can cause targeted misclassifications by exploiting weaknesses in the model.
By identifying and removing the most important neurons for the backdoor trigger, the approach can significantly reduce a model's susceptibility to such attacks, while maintaining its core functionality on regular data. While not a perfect solution, this work provides a valuable tool in the growing toolkit for ensuring the robustness and trustworthiness of AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Rethinking Pruning for Backdoor Mitigation: An Optimization Perspective
Nan Li, Haiyang Yu, Ping Yi
0
0
Deep Neural Networks (DNNs) are known to be vulnerable to backdoor attacks, posing concerning threats to their reliable deployment. Recent research reveals that backdoors can be erased from infected DNNs by pruning a specific group of neurons, while how to effectively identify and remove these backdoor-associated neurons remains an open challenge. Most of the existing defense methods rely on defined rules and focus on neuron's local properties, ignoring the exploration and optimization of pruning policies. To address this gap, we propose an Optimized Neuron Pruning (ONP) method combined with Graph Neural Network (GNN) and Reinforcement Learning (RL) to repair backdoor models. Specifically, ONP first models the target DNN as graphs based on neuron connectivity, and then uses GNN-based RL agents to learn graph embeddings and find a suitable pruning policy. To the best of our knowledge, this is the first attempt to employ GNN and RL for optimizing pruning policies in the field of backdoor defense. Experiments show, with a small amount of clean data, ONP can effectively prune the backdoor neurons implanted by a set of backdoor attacks at the cost of negligible performance degradation, achieving a new state-of-the-art performance for backdoor mitigation.
5/29/2024
📈
Unlearning Backdoor Attacks through Gradient-Based Model Pruning
Kealan Dunnett, Reza Arablouei, Dimity Miller, Volkan Dedeoglu, Raja Jurdak
0
0
In the era of increasing concerns over cybersecurity threats, defending against backdoor attacks is paramount in ensuring the integrity and reliability of machine learning models. However, many existing approaches require substantial amounts of data for effective mitigation, posing significant challenges in practical deployment. To address this, we propose a novel approach to counter backdoor attacks by treating their mitigation as an unlearning task. We tackle this challenge through a targeted model pruning strategy, leveraging unlearning loss gradients to identify and eliminate backdoor elements within the model. Built on solid theoretical insights, our approach offers simplicity and effectiveness, rendering it well-suited for scenarios with limited data availability. Our methodology includes formulating a suitable unlearning loss and devising a model-pruning technique tailored for convolutional neural networks. Comprehensive evaluations demonstrate the efficacy of our proposed approach compared to state-of-the-art approaches, particularly in realistic data settings.
5/8/2024
⛏️
Unveiling and Mitigating Backdoor Vulnerabilities based on Unlearning Weight Changes and Backdoor Activeness
Weilin Lin, Li Liu, Shaokui Wei, Jianze Li, Hui Xiong
0
0
The security threat of backdoor attacks is a central concern for deep neural networks (DNNs). Recently, without poisoned data, unlearning models with clean data and then learning a pruning mask have contributed to backdoor defense. Additionally, vanilla fine-tuning with those clean data can help recover the lost clean accuracy. However, the behavior of clean unlearning is still under-explored, and vanilla fine-tuning unintentionally induces back the backdoor effect. In this work, we first investigate model unlearning from the perspective of weight changes and gradient norms, and find two interesting observations in the backdoored model: 1) the weight changes between poison and clean unlearning are positively correlated, making it possible for us to identify the backdoored-related neurons without using poisoned data; 2) the neurons of the backdoored model are more active (i.e., larger changes in gradient norm) than those in the clean model, suggesting the need to suppress the gradient norm during fine-tuning. Then, we propose an effective two-stage defense method. In the first stage, an efficient Neuron Weight Change (NWC)-based Backdoor Reinitialization is proposed based on observation 1). In the second stage, based on observation 2), we design an Activeness-Aware Fine-Tuning to replace the vanilla fine-tuning. Extensive experiments, involving eight backdoor attacks on three benchmark datasets, demonstrate the superior performance of our proposed method compared to recent state-of-the-art backdoor defense approaches.
5/31/2024
Robustness-Inspired Defense Against Backdoor Attacks on Graph Neural Networks
Zhiwei Zhang, Minhua Lin, Junjie Xu, Zongyu Wu, Enyan Dai, Suhang Wang
0
0
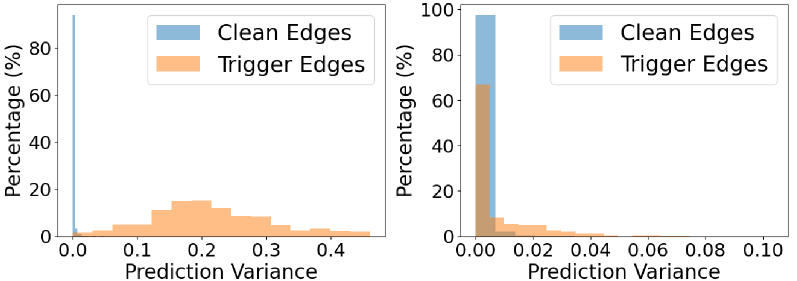
Graph Neural Networks (GNNs) have achieved promising results in tasks such as node classification and graph classification. However, recent studies reveal that GNNs are vulnerable to backdoor attacks, posing a significant threat to their real-world adoption. Despite initial efforts to defend against specific graph backdoor attacks, there is no work on defending against various types of backdoor attacks where generated triggers have different properties. Hence, we first empirically verify that prediction variance under edge dropping is a crucial indicator for identifying poisoned nodes. With this observation, we propose using random edge dropping to detect backdoors and theoretically show that it can efficiently distinguish poisoned nodes from clean ones. Furthermore, we introduce a novel robust training strategy to efficiently counteract the impact of the triggers. Extensive experiments on real-world datasets show that our framework can effectively identify poisoned nodes, significantly degrade the attack success rate, and maintain clean accuracy when defending against various types of graph backdoor attacks with different properties.
6/17/2024