Masked Autoencoders for Microscopy are Scalable Learners of Cellular Biology
2404.10242
0
0
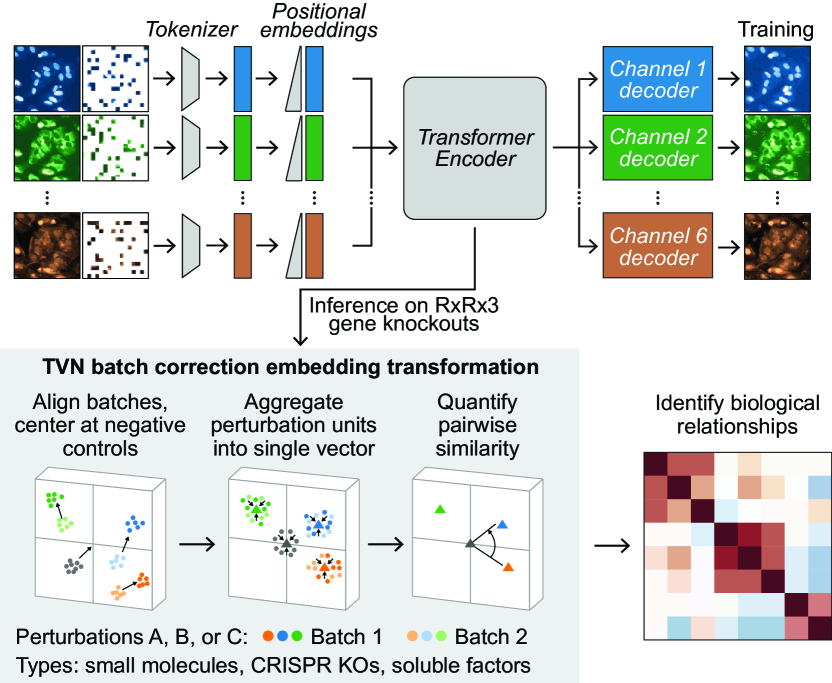
Abstract
Featurizing microscopy images for use in biological research remains a significant challenge, especially for large-scale experiments spanning millions of images. This work explores the scaling properties of weakly supervised classifiers and self-supervised masked autoencoders (MAEs) when training with increasingly larger model backbones and microscopy datasets. Our results show that ViT-based MAEs outperform weakly supervised classifiers on a variety of tasks, achieving as much as a 11.5% relative improvement when recalling known biological relationships curated from public databases. Additionally, we develop a new channel-agnostic MAE architecture (CA-MAE) that allows for inputting images of different numbers and orders of channels at inference time. We demonstrate that CA-MAEs effectively generalize by inferring and evaluating on a microscopy image dataset (JUMP-CP) generated under different experimental conditions with a different channel structure than our pretraining data (RPI-93M). Our findings motivate continued research into scaling self-supervised learning on microscopy data in order to create powerful foundation models of cellular biology that have the potential to catalyze advancements in drug discovery and beyond.
Create account to get full access
Overview
- This paper presents a novel approach to using masked autoencoders for microscopy imaging, which can be used to learn cellular biology at scale.
- The authors show that these models are effective at extracting meaningful features from high-content screening (HCS) datasets, outperforming traditional methods.
- The research has the potential to enable new discoveries in cell biology by leveraging the power of deep learning to analyze large-scale microscopy datasets.
Plain English Explanation
The paper describes a new way of using a type of artificial intelligence called a masked autoencoder to analyze microscope images of cells. Masked autoencoders work by trying to "fill in the blanks" in an image, learning to recognize important patterns and features in the process.
The researchers show that these models can be very effective at extracting useful information from large datasets of microscopy images, sometimes called "high-content screening" (HCS) data. This is valuable because HCS datasets can contain millions of images, far too many for humans to analyze manually. By using masked autoencoders, the researchers were able to automatically identify important cellular structures and behaviors, which could lead to new discoveries in cell biology.
Compared to traditional methods, the masked autoencoder approach was found to be more scalable and effective at learning meaningful representations from the HCS data. This suggests that these types of AI models could be powerful tools for accelerating progress in fields like cell biology, where there is a wealth of microscopy data waiting to be unlocked.
Technical Explanation
The paper proposes using masked autoencoders as a scalable approach to learning representations from high-content screening (HCS) microscopy datasets. Masked autoencoders work by randomly masking out (i.e., hiding) portions of the input image and then training the model to predict the missing pixels.
The authors show that this self-supervised approach allows the model to learn robust and meaningful features from the HCS data, outperforming traditional methods like PCA and hand-crafted feature engineering. They evaluate the learned representations on a range of downstream tasks, including cell type classification, subcellular structure segmentation, and anomaly detection.
Importantly, the masked autoencoder approach is shown to be highly scalable, able to handle datasets with millions of images. This is a key advantage over previous methods, which often struggled with the sheer scale of modern HCS datasets.
The paper also presents several architectural innovations, such as the use of a multi-scale encoder and a novel masking strategy, which further improve the model's performance and sample efficiency.
Critical Analysis
The research presented in this paper is a promising step forward in the application of deep learning to microscopy and cell biology. The authors demonstrate the effectiveness of masked autoencoders in extracting meaningful representations from large-scale HCS datasets, which could enable new discoveries and insights.
However, the paper does not address some potential limitations and areas for future work. For example, the authors do not explore the interpretability of the learned representations - it would be valuable to understand what specific cellular features and patterns the model is capturing. Additionally, the paper focuses on a limited set of downstream tasks, and it would be interesting to see how the approach generalizes to a wider range of cell biology applications.
Furthermore, the paper does not discuss potential biases or limitations in the HCS datasets used, which could impact the generalizability of the findings. It would be important to assess the model's performance on more diverse and representative datasets to ensure its robustness.
Overall, this research represents an exciting advancement in the use of AI for microscopy and cell biology, but there are still opportunities to further refine and expand the approach to unlock its full potential. Readers are encouraged to think critically about the findings and consider how the techniques could be improved or applied in novel ways.
Conclusion
This paper presents a novel approach to leveraging masked autoencoders for learning representations from high-content screening (HCS) microscopy datasets. The researchers show that this self-supervised technique is highly scalable and can outperform traditional methods, opening up new possibilities for discovering insights into cellular biology.
The ability to automatically extract meaningful features from large-scale microscopy data could accelerate progress in fields like cell biology, drug discovery, and tissue engineering. By making these powerful AI tools accessible to biologists, the research has the potential to transform how we investigate the fundamental mechanisms of life.
While the findings are promising, there are still opportunities to further refine and expand the approach. Nonetheless, this work represents an important step forward in the convergence of deep learning and microscopy, with exciting implications for the future of biological research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Exploring Masked Autoencoders for Sensor-Agnostic Image Retrieval in Remote Sensing
Jakob Hackstein, Gencer Sumbul, Kai Norman Clasen, Begum Demir
0
0
Self-supervised learning through masked autoencoders (MAEs) has recently attracted great attention for remote sensing (RS) image representation learning, and thus embodies a significant potential for content-based image retrieval (CBIR) from ever-growing RS image archives. However, the existing studies on MAEs in RS assume that the considered RS images are acquired by a single image sensor, and thus are only suitable for uni-modal CBIR problems. The effectiveness of MAEs for cross-sensor CBIR, which aims to search semantically similar images across different image modalities, has not been explored yet. In this paper, we take the first step to explore the effectiveness of MAEs for sensor-agnostic CBIR in RS. To this end, we present a systematic overview on the possible adaptations of the vanilla MAE to exploit masked image modeling on multi-sensor RS image archives (denoted as cross-sensor masked autoencoders [CSMAEs]). Based on different adjustments applied to the vanilla MAE, we introduce different CSMAE models. We also provide an extensive experimental analysis of these CSMAE models. We finally derive a guideline to exploit masked image modeling for uni-modal and cross-modal CBIR problems in RS. The code of this work is publicly available at https://github.com/jakhac/CSMAE.
4/12/2024
🏷️
Spatio-Temporal Encoding of Brain Dynamics with Surface Masked Autoencoders
Simon Dahan, Logan Z. J. Williams, Yourong Guo, Daniel Rueckert, Emma C. Robinson
0
0
The development of robust and generalisable models for encoding the spatio-temporal dynamics of human brain activity is crucial for advancing neuroscientific discoveries. However, significant individual variation in the organisation of the human cerebral cortex makes it difficult to identify population-level trends in these signals. Recently, Surface Vision Transformers (SiTs) have emerged as a promising approach for modelling cortical signals, yet they face some limitations in low-data scenarios due to the lack of inductive biases in their architecture. To address these challenges, this paper proposes the surface Masked AutoEncoder (sMAE) and video surface Masked AutoEncoder (vsMAE) - for multivariate and spatio-temporal pre-training of cortical signals over regular icosahedral grids. These models are trained to reconstruct cortical feature maps from masked versions of the input by learning strong latent representations of cortical structure and function. Such representations translate into better modelling of individual phenotypes and enhanced performance in downstream tasks. The proposed approach was evaluated on cortical phenotype regression using data from the young adult Human Connectome Project (HCP) and developing HCP (dHCP). Results show that (v)sMAE pre-trained models improve phenotyping prediction performance on multiple tasks by $ge 26%$, and offer faster convergence relative to models trained from scratch. Finally, we show that pre-training vision transformers on large datasets, such as the UK Biobank (UKB), supports transfer learning to low-data regimes. Our code and pre-trained models are publicly available at https://github.com/metrics-lab/surface-masked-autoencoders .
6/12/2024

SCE-MAE: Selective Correspondence Enhancement with Masked Autoencoder for Self-Supervised Landmark Estimation
Kejia Yin, Varshanth R. Rao, Ruowei Jiang, Xudong Liu, Parham Aarabi, David B. Lindell
0
0
Self-supervised landmark estimation is a challenging task that demands the formation of locally distinct feature representations to identify sparse facial landmarks in the absence of annotated data. To tackle this task, existing state-of-the-art (SOTA) methods (1) extract coarse features from backbones that are trained with instance-level self-supervised learning (SSL) paradigms, which neglect the dense prediction nature of the task, (2) aggregate them into memory-intensive hypercolumn formations, and (3) supervise lightweight projector networks to naively establish full local correspondences among all pairs of spatial features. In this paper, we introduce SCE-MAE, a framework that (1) leverages the MAE, a region-level SSL method that naturally better suits the landmark prediction task, (2) operates on the vanilla feature map instead of on expensive hypercolumns, and (3) employs a Correspondence Approximation and Refinement Block (CARB) that utilizes a simple density peak clustering algorithm and our proposed Locality-Constrained Repellence Loss to directly hone only select local correspondences. We demonstrate through extensive experiments that SCE-MAE is highly effective and robust, outperforming existing SOTA methods by large margins of approximately 20%-44% on the landmark matching and approximately 9%-15% on the landmark detection tasks.
5/29/2024
🖼️
Masked Image Modelling for retinal OCT understanding
Theodoros Pissas, Pablo M'arquez-Neila, Sebastian Wolf, Martin Zinkernagel, Raphael Sznitman
0
0
This work explores the effectiveness of masked image modelling for learning representations of retinal OCT images. To this end, we leverage Masked Autoencoders (MAE), a simple and scalable method for self-supervised learning, to obtain a powerful and general representation for OCT images by training on 700K OCT images from 41K patients collected under real world clinical settings. We also provide the first extensive evaluation for a model of OCT on a challenging battery of 6 downstream tasks. Our model achieves strong performance when fully finetuned but can also serve as a versatile frozen feature extractor for many tasks using lightweight adapters. Furthermore, we propose an extension of the MAE pretraining to fuse OCT with an auxiliary modality, namely, IR fundus images and learn a joint model for both. We demonstrate our approach improves performance on a multimodal downstream application. Our experiments utilize most publicly available OCT datasets, thus enabling future comparisons. Our code and model weights are publicly available https://github.com/TheoPis/MIM_OCT.
5/24/2024