MediFact at MEDIQA-CORR 2024: Why AI Needs a Human Touch
2404.17999
0
0

Abstract
Accurate representation of medical information is crucial for patient safety, yet artificial intelligence (AI) systems, such as Large Language Models (LLMs), encounter challenges in error-free clinical text interpretation. This paper presents a novel approach submitted to the MEDIQA-CORR 2024 shared task (Ben Abacha et al., 2024a), focusing on the automatic correction of single-word errors in clinical notes. Unlike LLMs that rely on extensive generic data, our method emphasizes extracting contextually relevant information from available clinical text data. Leveraging an ensemble of extractive and abstractive question-answering approaches, we construct a supervised learning framework with domain-specific feature engineering. Our methodology incorporates domain expertise to enhance error correction accuracy. By integrating domain expertise and prioritizing meaningful information extraction, our approach underscores the significance of a human-centric strategy in adapting AI for healthcare.
Create account to get full access
Overview
- Examines the need for a human touch in AI systems, using the MediFact system at the MEDIQA-CORR 2024 competition as a case study
- Highlights the importance of incorporating human expertise and oversight into AI-powered medical tools to ensure accuracy and trustworthiness
- Emphasizes the limitations of purely automated approaches and the value of human-AI collaboration in critical domains like healthcare
Plain English Explanation
The paper discusses the importance of having a human touch in AI systems, particularly in the medical field. It uses the MediFact system, which was entered in the MEDIQA-CORR 2024 competition, as an example to illustrate this point.
The key idea is that while AI systems can be powerful and efficient, they may still have limitations when it comes to complex, nuanced tasks like medical diagnosis and treatment recommendations. By incorporating human expertise and oversight into the AI system, the researchers believe it can become more accurate, trustworthy, and ultimately more effective in supporting healthcare professionals.
The paper argues that a purely automated approach, without any human involvement, may not be sufficient to address the challenges and uncertainties inherent in medical decision-making. Instead, a collaborative approach where AI and humans work together can leverage the strengths of both to provide the best possible outcomes for patients.
Technical Explanation
The paper describes the MediFact system, which was developed for the MEDIQA-CORR 2024 competition. MediFact is an AI-powered tool designed to assist healthcare professionals in correcting medical claims and ensuring the accuracy of medical information.
The system utilizes a large language model (LLM) that has been specially trained on a vast corpus of medical literature and data. This allows MediFact to analyze and identify potential inaccuracies or misinformation in medical claims with a high degree of accuracy.
However, the researchers acknowledge that even the most advanced AI systems can have limitations, particularly when dealing with the nuances and complexities of the medical field. To address this, the MediFact system incorporates a human review process, where medical experts are involved in verifying and validating the AI's outputs before they are presented to users.
This human-in-the-loop approach is designed to leverage the strengths of both the AI and the human experts, ensuring that the final outputs are as accurate, reliable, and trustworthy as possible. The researchers believe this collaborative approach is essential for building AI systems that can be safely and effectively deployed in critical domains like healthcare.
Critical Analysis
The paper makes a compelling case for the importance of incorporating human expertise and oversight into AI-powered medical tools. The researchers acknowledge the limitations of purely automated approaches and the need for a more collaborative human-AI model to ensure the accuracy and reliability of medical information.
One potential limitation of the research is that it focuses primarily on the MediFact system and the MEDIQA-CORR 2024 competition, which may limit the broader applicability of the findings. It would be interesting to see how the principles and approaches described in the paper could be applied to other AI-powered medical tools and systems.
Additionally, the paper does not delve deeply into the specific challenges or trade-offs involved in balancing human and AI contributions within the MediFact system. Further research and empirical evidence may be needed to better understand the optimal level of human involvement and the most effective ways to integrate it into the AI workflow.
Conclusion
The paper's central message is that AI systems, even those designed for critical domains like healthcare, require a human touch to be truly effective and trustworthy. By incorporating human expertise and oversight into the AI workflow, the MediFact system demonstrates how a collaborative approach can leverage the strengths of both technology and human knowledge to improve the accuracy and reliability of medical information.
As AI continues to advance and be applied in more sensitive and high-stakes contexts, this research highlights the importance of maintaining a human-in-the-loop approach. The findings suggest that a balanced partnership between AI and human experts is essential for developing medical technologies that can be safely and effectively deployed to support healthcare professionals and improve patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
PromptMind Team at MEDIQA-CORR 2024: Improving Clinical Text Correction with Error Categorization and LLM Ensembles
Satya Kesav Gundabathula, Sriram R Kolar
0
0
This paper describes our approach to the MEDIQA-CORR shared task, which involves error detection and correction in clinical notes curated by medical professionals. This task involves handling three subtasks: detecting the presence of errors, identifying the specific sentence containing the error, and correcting it. Through our work, we aim to assess the capabilities of Large Language Models (LLMs) trained on a vast corpora of internet data that contain both factual and unreliable information. We propose to comprehensively address all subtasks together, and suggest employing a unique prompt-based in-context learning strategy. We will evaluate its efficacy in this specialized task demanding a combination of general reasoning and medical knowledge. In medical systems where prediction errors can have grave consequences, we propose leveraging self-consistency and ensemble methods to enhance error correction and error detection performance.
5/15/2024

Edinburgh Clinical NLP at MEDIQA-CORR 2024: Guiding Large Language Models with Hints
Aryo Pradipta Gema, Chaeeun Lee, Pasquale Minervini, Luke Daines, T. Ian Simpson, Beatrice Alex
0
0
The MEDIQA-CORR 2024 shared task aims to assess the ability of Large Language Models (LLMs) to identify and correct medical errors in clinical notes. In this study, we evaluate the capability of general LLMs, specifically GPT-3.5 and GPT-4, to identify and correct medical errors with multiple prompting strategies. Recognising the limitation of LLMs in generating accurate corrections only via prompting strategies, we propose incorporating error-span predictions from a smaller, fine-tuned model in two ways: 1) by presenting it as a hint in the prompt and 2) by framing it as multiple-choice questions from which the LLM can choose the best correction. We found that our proposed prompting strategies significantly improve the LLM's ability to generate corrections. Our best-performing solution with 8-shot + CoT + hints ranked sixth in the shared task leaderboard. Additionally, our comprehensive analyses show the impact of the location of the error sentence, the prompted role, and the position of the multiple-choice option on the accuracy of the LLM. This prompts further questions about the readiness of LLM to be implemented in real-world clinical settings.
5/29/2024
🔎
WangLab at MEDIQA-CORR 2024: Optimized LLM-based Programs for Medical Error Detection and Correction
Augustin Toma, Ronald Xie, Steven Palayew, Patrick R. Lawler, Bo Wang
0
0
Medical errors in clinical text pose significant risks to patient safety. The MEDIQA-CORR 2024 shared task focuses on detecting and correcting these errors across three subtasks: identifying the presence of an error, extracting the erroneous sentence, and generating a corrected sentence. In this paper, we present our approach that achieved top performance in all three subtasks. For the MS dataset, which contains subtle errors, we developed a retrieval-based system leveraging external medical question-answering datasets. For the UW dataset, reflecting more realistic clinical notes, we created a pipeline of modules to detect, localize, and correct errors. Both approaches utilized the DSPy framework for optimizing prompts and few-shot examples in large language model (LLM) based programs. Our results demonstrate the effectiveness of LLM based programs for medical error correction. However, our approach has limitations in addressing the full diversity of potential errors in medical documentation. We discuss the implications of our work and highlight future research directions to advance the robustness and applicability of medical error detection and correction systems.
4/24/2024
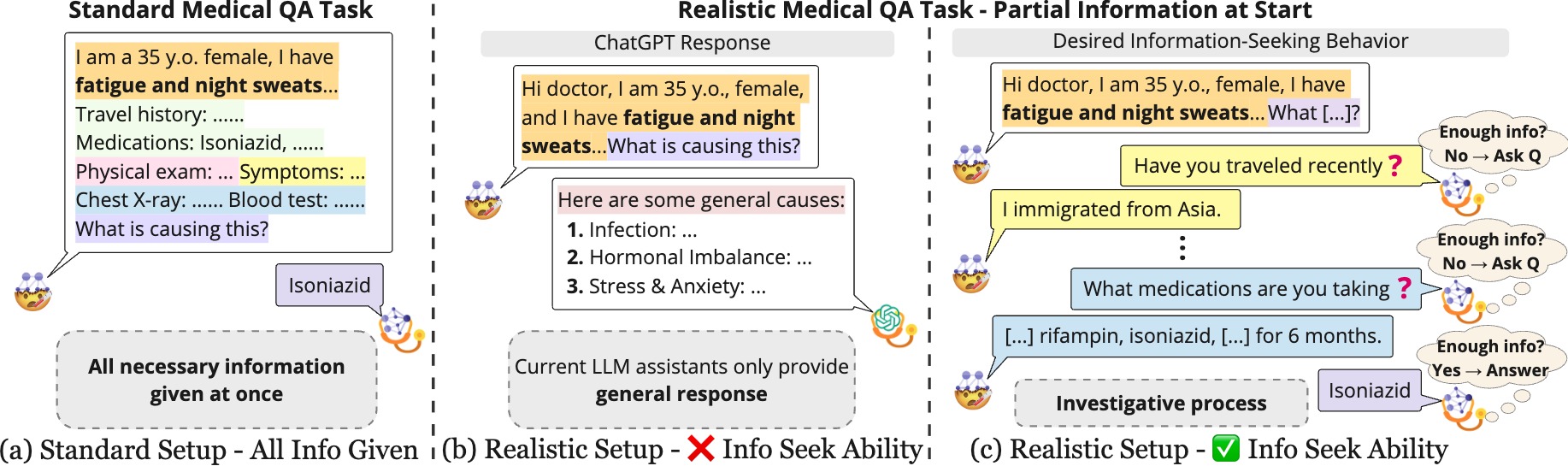
MEDIQ: Question-Asking LLMs for Adaptive and Reliable Medical Reasoning
Shuyue Stella Li, Vidhisha Balachandran, Shangbin Feng, Jonathan Ilgen, Emma Pierson, Pang Wei Koh, Yulia Tsvetkov
0
0
In high-stakes domains like clinical reasoning, AI assistants powered by large language models (LLMs) are yet to be reliable and safe. We identify a key obstacle towards reliability: existing LLMs are trained to answer any question, even with incomplete context in the prompt or insufficient parametric knowledge. We propose to change this paradigm to develop more careful LLMs that ask follow-up questions to gather necessary and sufficient information and respond reliably. We introduce MEDIQ, a framework to simulate realistic clinical interactions, which incorporates a Patient System and an adaptive Expert System. The Patient may provide incomplete information in the beginning; the Expert refrains from making diagnostic decisions when unconfident, and instead elicits missing details from the Patient via follow-up questions. To evaluate MEDIQ, we convert MEDQA and CRAFT-MD -- medical benchmarks for diagnostic question answering -- into an interactive setup. We develop a reliable Patient system and prototype several Expert systems, first showing that directly prompting state-of-the-art LLMs to ask questions degrades the quality of clinical reasoning, indicating that adapting LLMs to interactive information-seeking settings is nontrivial. We then augment the Expert with a novel abstention module to better estimate model confidence and decide whether to ask more questions, thereby improving diagnostic accuracy by 20.3%; however, performance still lags compared to an (unrealistic in practice) upper bound when full information is given upfront. Further analyses reveal that interactive performance can be improved by filtering irrelevant contexts and reformatting conversations. Overall, our paper introduces a novel problem towards LLM reliability, a novel MEDIQ framework, and highlights important future directions to extend the information-seeking abilities of LLM assistants in critical domains.
6/5/2024