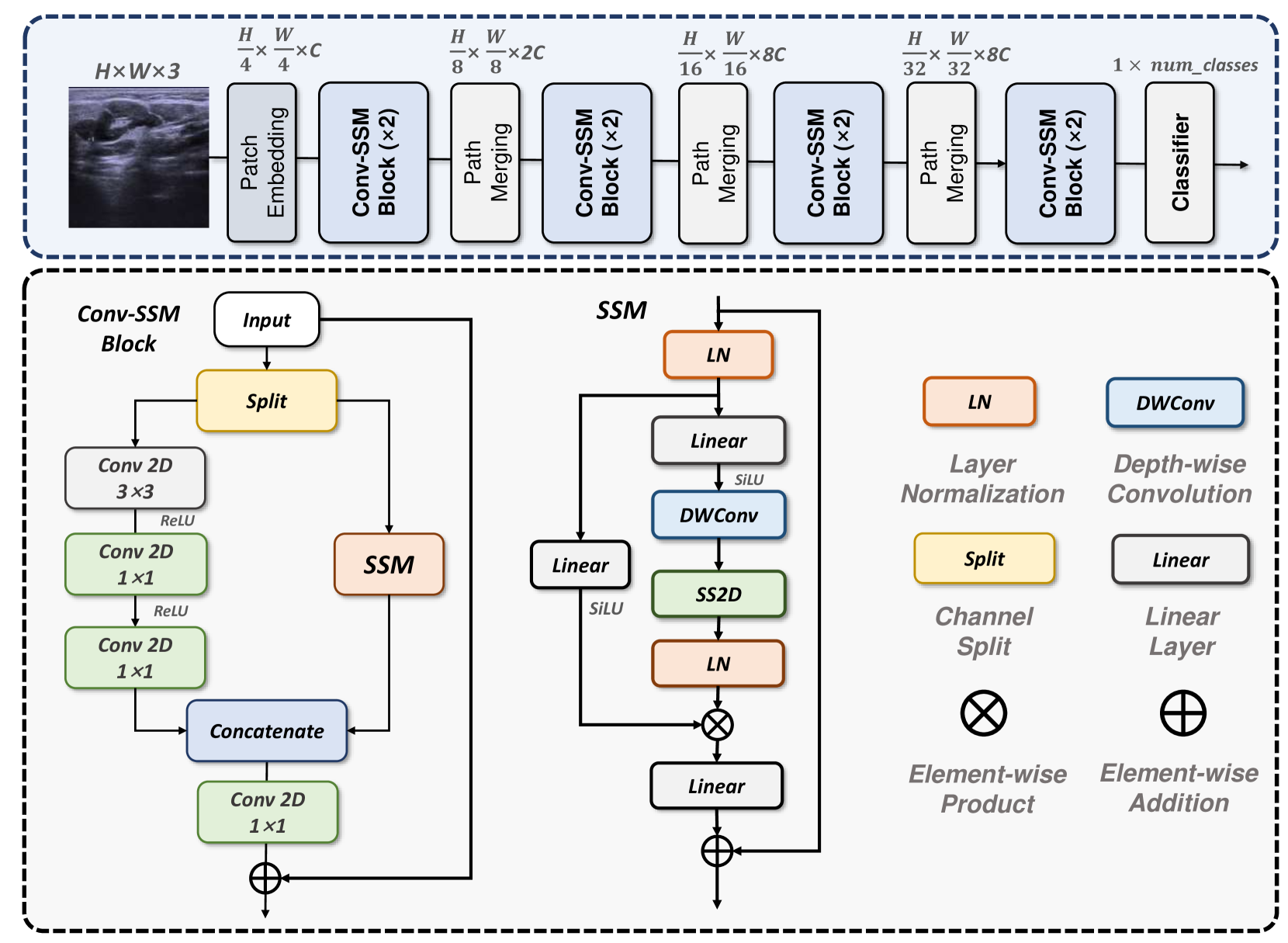
MedMamba: Vision Mamba for Medical Image Classification
2403.03849
0
0
Abstract
Medical image classification is a very fundamental and crucial task in the field of computer vision. These years, CNN-based and Transformer-based models have been widely used to classify various medical images. Unfortunately, The limitation of CNNs in long-range modeling capabilities prevents them from effectively extracting features in medical images, while Transformers are hampered by their quadratic computational complexity. Recent research has shown that the state space model (SSM) represented by Mamba can efficiently model long-range interactions while maintaining linear computational complexity. Inspired by this, we propose Vision Mamba for medical image classification (MedMamba). More specifically, we introduce a novel Conv-SSM module. Conv-SSM combines the local feature extraction ability of convolutional layers with the ability of SSM to capture long-range dependency, thereby modeling medical images with different modalities. To demonstrate the potential of MedMamba, we conducted extensive experiments using 14 publicly available medical datasets with different imaging techniques and two private datasets built by ourselves. Extensive experimental results demonstrate that the proposed MedMamba performs well in detecting lesions in various medical images. To the best of our knowledge, this is the first Vision Mamba tailored for medical image classification. The purpose of this work is to establish a new baseline for medical image classification tasks and provide valuable insights for the future development of more efficient and effective SSM-based artificial intelligence algorithms and application systems in the medical. Source code has been available at https://github.com/YubiaoYue/MedMamba.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Presents a novel deep learning model called MedMamba for medical image classification
- Demonstrates state-of-the-art performance on medical image datasets
- Explores the use of a specialized convolutional neural network architecture for medical imaging tasks
Plain English Explanation
MedMamba is a new deep learning model designed specifically for classifying medical images. Medical image analysis is a critical task in healthcare, as it can help doctors quickly and accurately diagnose conditions based on X-rays, scans, and other medical imagery.
The key innovation in MedMamba is its specialized convolutional neural network architecture. Convolutional neural networks are a type of machine learning model that excels at processing visual data, like images. MedMamba builds upon existing convolutional network designs, but includes modifications and additions that make it particularly well-suited for medical imaging problems.
For example, MedMamba incorporates new structural elements that allow it to better capture the unique characteristics of medical images, such as the presence of anatomical features and complex spatial relationships. This enables MedMamba to learn more effective representations of the medical data, leading to improved classification accuracy compared to general-purpose computer vision models.
Additionally, the researchers trained and evaluated MedMamba on several standard medical imaging datasets. The results show that MedMamba outperforms other state-of-the-art models, demonstrating its potential to enhance computer-aided diagnosis and decision support in healthcare settings.
Technical Explanation
The core of MedMamba is a convolutional neural network architecture that builds upon the well-known Vision Transformer (ViT) model. ViT has shown strong performance on a variety of visual recognition tasks, but the authors hypothesized that further modifications would be needed to optimize it for medical image classification.
Key architectural changes in MedMamba include:
- Spatial Attention Modules: These modules allow the model to dynamically focus on relevant spatial regions of the input image, which is important for capturing the diagnostic significance of specific anatomical structures.
- Multi-Scale Fusion: MedMamba combines features extracted at different resolutions to capture both global and local image information, which is crucial for medical image analysis.
- Squeeze-and-Excitation Blocks: These blocks enhance the model's ability to selectively emphasize informative features and suppress less relevant ones, improving the network's discriminative power.
The authors thoroughly evaluated MedMamba on several public medical imaging datasets, including chest X-ray, mammography, and retinal fundus image classification tasks. Across these benchmarks, MedMamba demonstrated state-of-the-art performance, outperforming previous convolutional and transformer-based models.
Critical Analysis
The paper provides a compelling technical case for the effectiveness of the MedMamba architecture on medical image classification tasks. The authors have clearly put significant effort into designing a specialized model that can capture the unique characteristics of medical imagery.
However, the paper does not delve deeply into some potential limitations or areas for further research. For example, it would be valuable to understand how MedMamba's performance scales with dataset size and diversity, as well as how it might handle more challenging medical image analysis problems, such as segmentation or disease progression tracking.
Additionally, while the results are promising, the paper does not address potential concerns around the interpretability and explainability of the MedMamba model. As medical AI systems become more widely deployed, there will likely be an increasing emphasis on understanding the reasoning behind model predictions, which could be an area for future work.
Conclusion
Overall, the MedMamba paper presents a novel deep learning model that shows strong potential for improving medical image classification tasks. By leveraging a specialized convolutional neural network architecture, the authors have demonstrated state-of-the-art performance on several medical imaging benchmarks.
The implications of this research are significant, as accurate and efficient medical image analysis can have a substantial impact on disease diagnosis, treatment planning, and patient outcomes. As the use of AI in healthcare continues to grow, models like MedMamba could play an important role in enhancing computer-aided decision support and accelerating the adoption of these transformative technologies in clinical practice.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Survey on Visual Mamba
Hanwei Zhang, Ying Zhu, Dan Wang, Lijun Zhang, Tianxiang Chen, Zi Ye
0
0
State space models (SSMs) with selection mechanisms and hardware-aware architectures, namely Mamba, have recently demonstrated significant promise in long-sequence modeling. Since the self-attention mechanism in transformers has quadratic complexity with image size and increasing computational demands, the researchers are now exploring how to adapt Mamba for computer vision tasks. This paper is the first comprehensive survey aiming to provide an in-depth analysis of Mamba models in the field of computer vision. It begins by exploring the foundational concepts contributing to Mamba's success, including the state space model framework, selection mechanisms, and hardware-aware design. Next, we review these vision mamba models by categorizing them into foundational ones and enhancing them with techniques such as convolution, recurrence, and attention to improve their sophistication. We further delve into the widespread applications of Mamba in vision tasks, which include their use as a backbone in various levels of vision processing. This encompasses general visual tasks, Medical visual tasks (e.g., 2D / 3D segmentation, classification, and image registration, etc.), and Remote Sensing visual tasks. We specially introduce general visual tasks from two levels: High/Mid-level vision (e.g., Object detection, Segmentation, Video classification, etc.) and Low-level vision (e.g., Image super-resolution, Image restoration, Visual generation, etc.). We hope this endeavor will spark additional interest within the community to address current challenges and further apply Mamba models in computer vision.
4/29/2024
A Survey on Vision Mamba: Models, Applications and Challenges
Rui Xu, Shu Yang, Yihui Wang, Bo Du, Hao Chen
0
0
Mamba, a recent selective structured state space model, performs excellently on long sequence modeling tasks. Mamba mitigates the modeling constraints of convolutional neural networks and offers advanced modeling capabilities similar to those of Transformers, through global receptive fields and dynamic weighting. Crucially, it achieves this without incurring the quadratic computational complexity typically associated with Transformers. Due to its advantages over the former two mainstream foundation models, Mamba exhibits great potential to be a visual foundation model. Researchers are actively applying Mamba to various computer vision tasks, leading to numerous emerging works. To help keep pace with the rapid advancements in computer vision, this paper aims to provide a comprehensive review of visual Mamba approaches. This paper begins by delineating the formulation of the original Mamba model. Subsequently, our review of visual Mamba delves into several representative backbone networks to elucidate the core insights of the visual Mamba. We then categorize related works using different modalities, including image, video, point cloud, multi-modal, and others. Specifically, for image applications, we further organize them into distinct tasks to facilitate a more structured discussion. Finally, we discuss the challenges and future research directions for visual Mamba, providing insights for future research in this quickly evolving area. A comprehensive list of visual Mamba models reviewed in this work is available at https://github.com/Ruixxxx/Awesome-Vision-Mamba-Models.
4/30/2024
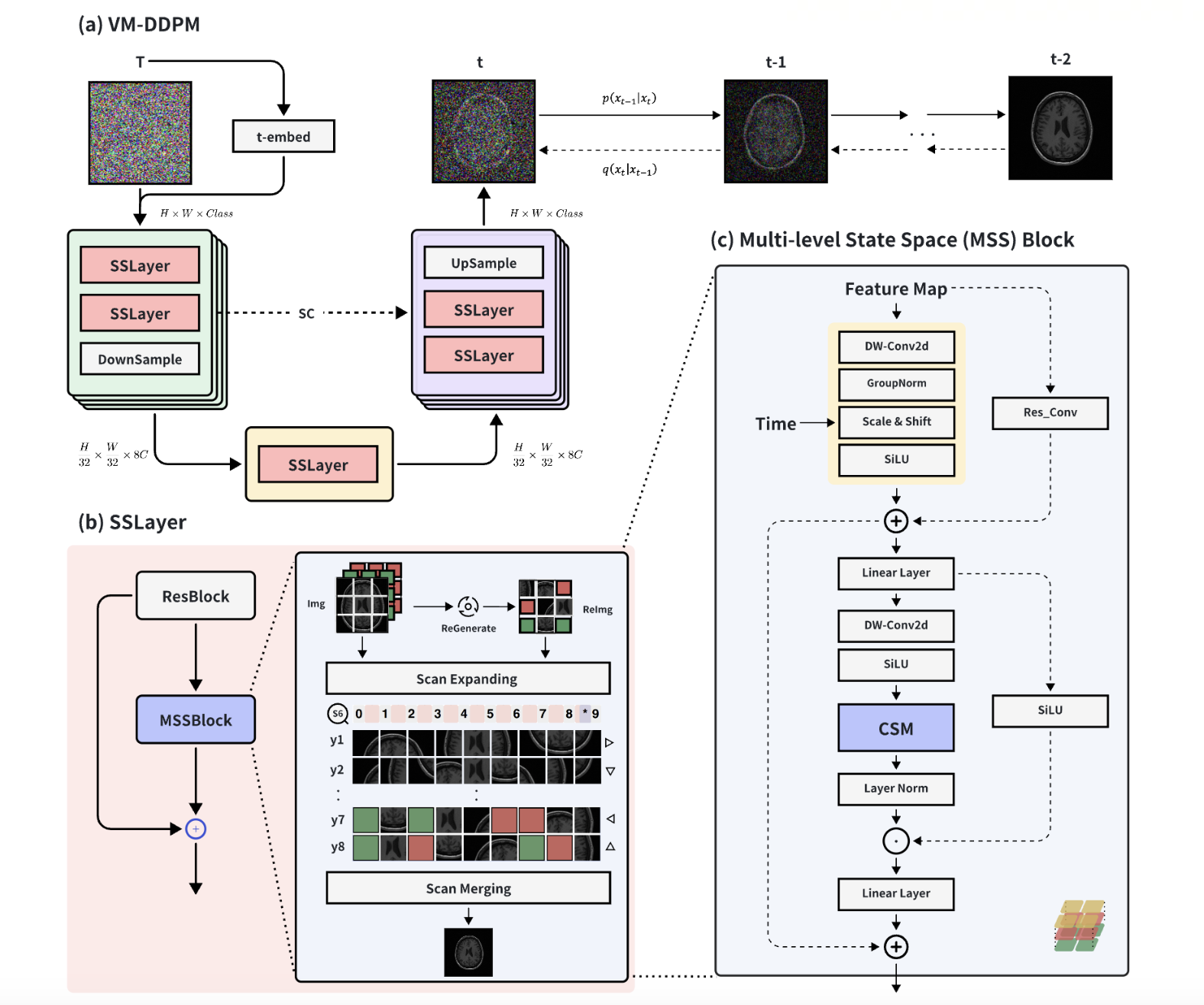
VM-DDPM: Vision Mamba Diffusion for Medical Image Synthesis
Zhihan Ju, Wanting Zhou
0
0
In the realm of smart healthcare, researchers enhance the scale and diversity of medical datasets through medical image synthesis. However, existing methods are limited by CNN local perception and Transformer quadratic complexity, making it difficult to balance structural texture consistency. To this end, we propose the Vision Mamba DDPM (VM-DDPM) based on State Space Model (SSM), fully combining CNN local perception and SSM global modeling capabilities, while maintaining linear computational complexity. Specifically, we designed a multi-level feature extraction module called Multi-level State Space Block (MSSBlock), and a basic unit of encoder-decoder structure called State Space Layer (SSLayer) for medical pathological images. Besides, we designed a simple, Plug-and-Play, zero-parameter Sequence Regeneration strategy for the Cross-Scan Module (CSM), which enabled the S6 module to fully perceive the spatial features of the 2D image and stimulate the generalization potential of the model. To our best knowledge, this is the first medical image synthesis model based on the SSM-CNN hybrid architecture. Our experimental evaluation on three datasets of different scales, i.e., ACDC, BraTS2018, and ChestXRay, as well as qualitative evaluation by radiologists, demonstrate that VM-DDPM achieves state-of-the-art performance.
5/10/2024
HC-Mamba: Vision MAMBA with Hybrid Convolutional Techniques for Medical Image Segmentation
Jiashu Xu
0
0
Automatic medical image segmentation technology has the potential to expedite pathological diagnoses, thereby enhancing the efficiency of patient care. However, medical images often have complex textures and structures, and the models often face the problem of reduced image resolution and information loss due to downsampling. To address this issue, we propose HC-Mamba, a new medical image segmentation model based on the modern state space model Mamba. Specifically, we introduce the technique of dilated convolution in the HC-Mamba model to capture a more extensive range of contextual information without increasing the computational cost by extending the perceptual field of the convolution kernel. In addition, the HC-Mamba model employs depthwise separable convolutions, significantly reducing the number of parameters and the computational power of the model. By combining dilated convolution and depthwise separable convolutions, HC-Mamba is able to process large-scale medical image data at a much lower computational cost while maintaining a high level of performance. We conduct comprehensive experiments on segmentation tasks including organ segmentation and skin lesion, and conduct extensive experiments on Synapse, ISIC17 and ISIC18 to demonstrate the potential of the HC-Mamba model in medical image segmentation. The experimental results show that HC-Mamba exhibits competitive performance on all these datasets, thereby proving its effectiveness and usefulness in medical image segmentation.
5/14/2024