Mind Your Neighbours: Leveraging Analogous Instances for Rhetorical Role Labeling for Legal Documents
2404.01344
0
0

Abstract
Rhetorical Role Labeling (RRL) of legal judgments is essential for various tasks, such as case summarization, semantic search and argument mining. However, it presents challenges such as inferring sentence roles from context, interrelated roles, limited annotated data, and label imbalance. This study introduces novel techniques to enhance RRL performance by leveraging knowledge from semantically similar instances (neighbours). We explore inference-based and training-based approaches, achieving remarkable improvements in challenging macro-F1 scores. For inference-based methods, we explore interpolation techniques that bolster label predictions without re-training. While in training-based methods, we integrate prototypical learning with our novel discourse-aware contrastive method that work directly on embedding spaces. Additionally, we assess the cross-domain applicability of our methods, demonstrating their effectiveness in transferring knowledge across diverse legal domains.
Create account to get full access
Overview
- The paper explores a novel approach to labeling the rhetorical roles of sentences in legal documents by leveraging analogous instances from other documents.
- The authors propose a model that can effectively identify the purpose and function of different parts of a legal document, such as the arguments, evidence, and conclusions.
- This could have important applications in automating legal analysis and summarization tasks.
Plain English Explanation
The researchers in this paper are working on a problem that might seem quite specialized, but actually has important real-world applications. They are trying to develop a way for computers to understand the different "roles" that sentences play in legal documents.
Imagine you have a long, complex legal contract or court ruling. Within that document, certain sentences might be making an argument, others might be providing evidence to support that argument, and others might be stating the final conclusion. Being able to automatically identify these different rhetorical roles could be really helpful for tasks like summarizing the key points of the document or quickly finding the most important information.
The researchers' key insight is that they can leverage "analogous" sentences from other similar documents to help identify the roles of sentences in a new document. So even if they haven't seen the exact sentence before, if they've seen very similar sentences in other contexts, they can use that knowledge to figure out what role it's playing.
This is a clever approach because legal documents tend to follow certain standard structures and use common phrasings, even if the specific content varies. By tapping into that broader context, the model can make more accurate predictions about the purpose of each sentence.
Technical Explanation
The paper introduces a novel approach for rhetorical role labeling in legal documents, which involves classifying each sentence into one of several predefined rhetorical roles (e.g. argument, evidence, conclusion).
The core of the model is a transformer-based neural network that takes in the text of a sentence along with contextual information about its "neighbors" - the sentences that come before and after it in the document. This allows the model to not just look at the individual sentence, but understand how it fits into the broader rhetorical structure.
To further boost performance, the researchers propose an "analogous instance retrieval" module. This component searches a database of sentences from other legal documents and finds the most similar ones to the current input sentence. The model can then leverage the known rhetorical roles of those analogous instances to inform its prediction for the current sentence.
Through extensive experiments on two legal document datasets, the authors demonstrate that this combined approach significantly outperforms previous state-of-the-art methods for rhetorical role labeling. The model is able to more accurately identify the purpose and function of each sentence, which could enable a wide range of downstream applications in legal technology and beyond.
Critical Analysis
The research presented in this paper is a thoughtful and well-executed contribution to the field of legal document processing. The key innovation of leveraging analogous instances is a clever way to inject broader contextual knowledge into the model, going beyond just looking at isolated sentences.
That said, there are a few areas that could warrant further investigation. The paper focuses on English-language legal documents, so it's unclear how well the approach would generalize to other languages or domains. There's also the question of how the model would handle novel phrasings or structures that deviate from the training data.
Additionally, while the performance gains are impressive, the paper doesn't provide much insight into the types of errors the model is still making. Understanding the remaining limitations could help guide future research directions.
Overall, this is a promising step forward in automating the analysis of complex legal texts. With further refinement and real-world testing, the techniques developed here could have significant impacts on how legal professionals work with large document collections.
Conclusion
This paper tackles the important challenge of automatically understanding the rhetorical structure of legal documents. By leveraging analogous instances from other documents, the researchers have developed a model that can accurately identify the purpose and function of individual sentences.
The implications of this work are quite broad. Automating tasks like summarization, search, and knowledge extraction for legal texts could dramatically improve the efficiency of legal research and analysis. And the general approach of using broader contextual cues, beyond just the local sentence, represents an advancement in natural language processing that could benefit many other domains as well.
While there is still room for improvement, this research represents a significant step forward. As artificial intelligence continues to shape the future of the legal industry and beyond, innovative techniques like those presented here will likely play an increasingly important role.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Judgement Citation Retrieval using Contextual Similarity
Akshat Mohan Dasula, Hrushitha Tigulla, Preethika Bhukya
0
0
Traditionally in the domain of legal research, the retrieval of pertinent citations from intricate case descriptions has demanded manual effort and keyword-based search applications that mandate expertise in understanding legal jargon. Legal case descriptions hold pivotal information for legal professionals and researchers, necessitating more efficient and automated approaches. We propose a methodology that combines natural language processing (NLP) and machine learning techniques to enhance the organization and utilization of legal case descriptions. This approach revolves around the creation of textual embeddings with the help of state-of-art embedding models. Our methodology addresses two primary objectives: unsupervised clustering and supervised citation retrieval, both designed to automate the citation extraction process. Although the proposed methodology can be used for any dataset, we employed the Supreme Court of The United States (SCOTUS) dataset, yielding remarkable results. Our methodology achieved an impressive accuracy rate of 90.9%. By automating labor-intensive processes, we pave the way for a more efficient, time-saving, and accessible landscape in legal research, benefiting legal professionals, academics, and researchers.
6/5/2024
🔍
ARN: Analogical Reasoning on Narratives
Zhivar Sourati, Filip Ilievski, Pia Sommerauer, Yifan Jiang
0
0
As a core cognitive skill that enables the transferability of information across domains, analogical reasoning has been extensively studied for both humans and computational models. However, while cognitive theories of analogy often focus on narratives and study the distinction between surface, relational, and system similarities, existing work in natural language processing has a narrower focus as far as relational analogies between word pairs. This gap brings a natural question: can state-of-the-art large language models (LLMs) detect system analogies between narratives? To gain insight into this question and extend word-based relational analogies to relational system analogies, we devise a comprehensive computational framework that operationalizes dominant theories of analogy, using narrative elements to create surface and system mappings. Leveraging the interplay between these mappings, we create a binary task and benchmark for Analogical Reasoning on Narratives (ARN), covering four categories of far (cross-domain)/near (within-domain) analogies and disanalogies. We show that while all LLMs can largely recognize near analogies, even the largest ones struggle with far analogies in a zero-shot setting, with GPT4.0 scoring below random. Guiding the models through solved examples and chain-of-thought reasoning enhances their analogical reasoning ability. Yet, since even in the few-shot setting, the best model only performs halfway between random and humans, ARN opens exciting directions for computational analogical reasoners.
4/24/2024
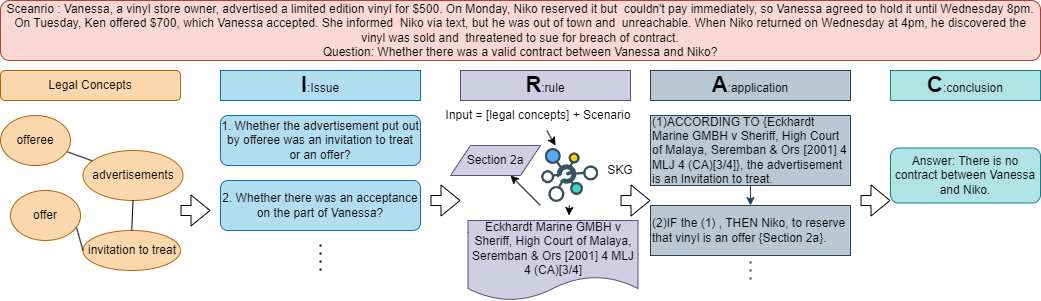
Bridging Law and Data: Augmenting Reasoning via a Semi-Structured Dataset with IRAC methodology
Xiaoxi Kang, Lizhen Qu, Lay-Ki Soon, Zhuang Li, Adnan Trakic
0
0
The effectiveness of Large Language Models (LLMs) in legal reasoning is often limited due to the unique legal terminologies and the necessity for highly specialized knowledge. These limitations highlight the need for high-quality data tailored for complex legal reasoning tasks. This paper introduces LEGALSEMI, a benchmark specifically curated for legal scenario analysis. LEGALSEMI comprises 54 legal scenarios, each rigorously annotated by legal experts, based on the comprehensive IRAC (Issue, Rule, Application, Conclusion) framework. In addition, LEGALSEMI is accompanied by a structured knowledge graph (SKG). A series of experiments were conducted to assess the usefulness of LEGALSEMI for IRAC analysis. The experimental results demonstrate the effectiveness of incorporating the SKG for issue identification, rule retrieval, application and conclusion generation using four different LLMs. LEGALSEMI will be publicly available upon acceptance of this paper.
6/21/2024

New!Learning Interpretable Legal Case Retrieval via Knowledge-Guided Case Reformulation
Chenlong Deng, Kelong Mao, Zhicheng Dou
0
0
Legal case retrieval for sourcing similar cases is critical in upholding judicial fairness. Different from general web search, legal case retrieval involves processing lengthy, complex, and highly specialized legal documents. Existing methods in this domain often overlook the incorporation of legal expert knowledge, which is crucial for accurately understanding and modeling legal cases, leading to unsatisfactory retrieval performance. This paper introduces KELLER, a legal knowledge-guided case reformulation approach based on large language models (LLMs) for effective and interpretable legal case retrieval. By incorporating professional legal knowledge about crimes and law articles, we enable large language models to accurately reformulate the original legal case into concise sub-facts of crimes, which contain the essential information of the case. Extensive experiments on two legal case retrieval benchmarks demonstrate superior retrieval performance and robustness on complex legal case queries of KELLER over existing methods.
7/1/2024