Mitigating Catastrophic Forgetting in Large Language Models with Self-Synthesized Rehearsal
2403.01244
0
0

Abstract
Large language models (LLMs) suffer from catastrophic forgetting during continual learning. Conventional rehearsal-based methods rely on previous training data to retain the model's ability, which may not be feasible in real-world applications. When conducting continual learning based on a publicly-released LLM checkpoint, the availability of the original training data may be non-existent. To address this challenge, we propose a framework called Self-Synthesized Rehearsal (SSR) that uses the LLM to generate synthetic instances for rehearsal. Concretely, we first employ the base LLM for in-context learning to generate synthetic instances. Subsequently, we utilize the latest LLM to refine the instance outputs based on the synthetic inputs, preserving its acquired ability. Finally, we select diverse high-quality synthetic instances for rehearsal in future stages. Experimental results demonstrate that SSR achieves superior or comparable performance compared to conventional rehearsal-based approaches while being more data-efficient. Besides, SSR effectively preserves the generalization capabilities of LLMs in general domains.
Create account to get full access
Overview
- This paper proposes a method to mitigate catastrophic forgetting in large language models using self-synthesized rehearsal.
- Catastrophic forgetting is a key challenge in continual learning, where a model forgets previously learned information when trained on new tasks.
- The authors introduce a technique to synthesize diverse samples from the model's past experiences, which are then used to rehearse and consolidate the model's knowledge during training on new tasks.
Plain English Explanation
Large language models, like those used for tasks such as text generation and language understanding, can often forget information they have learned previously when exposed to new data. This phenomenon, known as catastrophic forgetting, can be a significant problem, as it prevents the models from retaining and building upon their accumulated knowledge.
The authors of this paper have developed a method to address this issue. Their approach involves
The key innovation in this work is the use of an
Technical Explanation
The authors propose a Synthesizrr framework to mitigate catastrophic forgetting in large language models. The core idea is to leverage an internal generative model within the language model to produce diverse samples from its past experiences, which are then used for rehearsal during training on new tasks.
The Synthesizrr framework consists of three key components:
- Generator Model: A generative model that is trained to synthesize diverse samples from the model's past experiences, capturing the full distribution of the model's knowledge.
- Rehearsal Module: A module that selects a subset of the synthesized samples and incorporates them into the training pipeline, allowing the model to practice and consolidate its previous knowledge.
- Continual Learning Model: The language model being trained, which is augmented with the Synthesizrr framework to enable continual learning and overcome catastrophic forgetting.
The authors demonstrate the effectiveness of their approach through extensive experiments on various language understanding and generation tasks. They show that the Synthesizrr framework outperforms brain-inspired continual learning and adaptive memory replay techniques, two prominent approaches for mitigating catastrophic forgetting in large language models.
Critical Analysis
The authors provide a compelling solution to the problem of catastrophic forgetting in large language models. The use of self-synthesized rehearsal is a novel and promising approach, as it allows the model to generate its own diverse samples that closely match its internal representations and knowledge.
However, the authors acknowledge several limitations and areas for further research. For example, the efficiency and scalability of the Synthesizrr framework, particularly the computational and memory requirements of the internal generative model, could be a concern for deploying these techniques in real-world applications.
Additionally, the authors note that the quality and diversity of the synthesized samples are crucial for the effectiveness of the rehearsal process. Investigating methods to further improve the sample generation or explore alternative rehearsal strategies could be valuable directions for future research.
Conclusion
This paper presents a significant advancement in addressing the challenge of catastrophic forgetting in large language models. By introducing the Synthesizrr framework and leveraging self-synthesized rehearsal, the authors demonstrate a effective way to enable continual learning and preserve the accumulated knowledge of these powerful models.
The proposed approach has the potential to unlock new avenues for developing more robust and adaptable language models, which could have far-reaching implications for a wide range of natural language processing applications. As the field of continual learning continues to evolve, this work serves as an important contribution, paving the way for further advancements in the mitigation of catastrophic forgetting in large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, Yue Zhang
0
0
Catastrophic forgetting (CF) is a phenomenon that occurs in machine learning when a model forgets previously learned information while acquiring new knowledge. As large language models (LLMs) have demonstrated remarkable performance, it is intriguing to investigate whether CF exists during the continual instruction tuning of LLMs. This study empirically evaluates the forgetting phenomenon in LLMs' knowledge during continual instruction tuning from the perspectives of domain knowledge, reasoning, and reading comprehension. The experiments reveal that catastrophic forgetting is generally observed in LLMs ranging from 1b to 7b parameters. Moreover, as the model scale increases, the severity of forgetting intensifies. Comparing the decoder-only model BLOOMZ with the encoder-decoder model mT0, BLOOMZ exhibits less forgetting and retains more knowledge. Interestingly, we also observe that LLMs can mitigate language biases, such as gender bias, during continual fine-tuning. Furthermore, our findings indicate that ALPACA maintains more knowledge and capacity compared to LLAMA during continual fine-tuning, suggesting that general instruction tuning can help alleviate the forgetting phenomenon in LLMs during subsequent fine-tuning processes.
4/3/2024
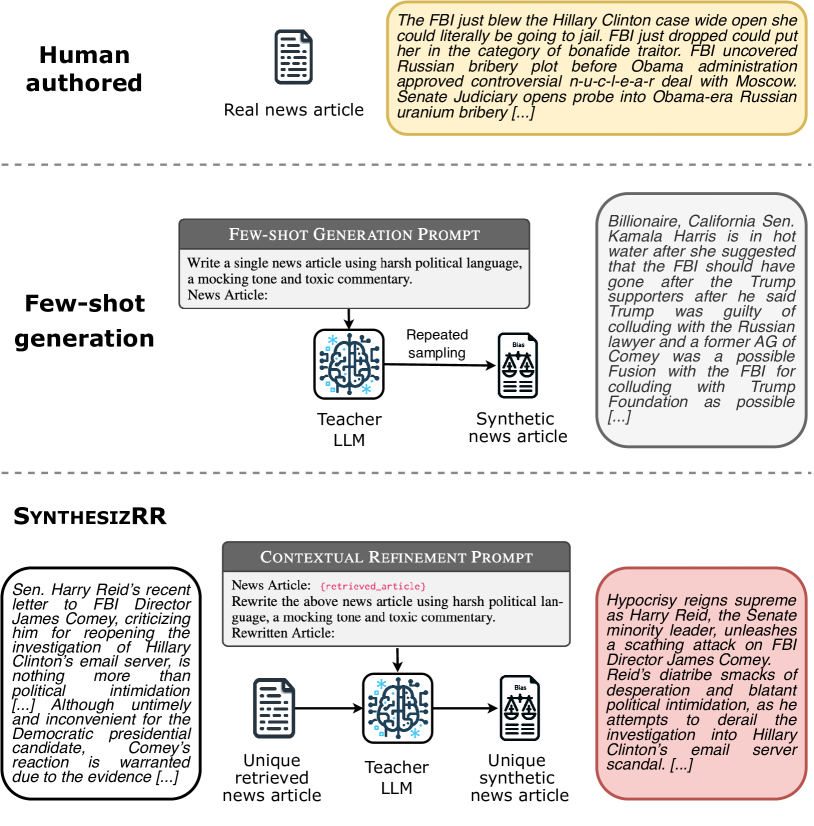
SynthesizRR: Generating Diverse Datasets with Retrieval Augmentation
Abhishek Divekar, Greg Durrett
0
0
Large language models (LLMs) are versatile and can address many tasks, but for computational efficiency, it is often desirable to distill their capabilities into smaller student models. One way to do this for classification tasks is via dataset synthesis, which can be accomplished by generating examples of each label from the LLM. Prior approaches to synthesis use few-shot prompting, which relies on the LLM's parametric knowledge to generate usable examples. However, this leads to issues of repetition, bias towards popular entities, and stylistic differences from human text. In this work, we propose Synthesize by Retrieval and Refinement (SynthesizRR), which uses retrieval augmentation to introduce variety into the dataset synthesis process: as retrieved passages vary, the LLM is seeded with different content to generate its examples. We empirically study the synthesis of six datasets, covering topic classification, sentiment analysis, tone detection, and humor, requiring complex synthesis strategies. We find SynthesizRR greatly improves lexical and semantic diversity, similarity to human-written text, and distillation performance, when compared to standard 32-shot prompting and six baseline approaches.
5/17/2024

CORE: Mitigating Catastrophic Forgetting in Continual Learning through Cognitive Replay
Jianshu Zhang, Yankai Fu, Ziheng Peng, Dongyu Yao, Kun He
0
0
This paper introduces a novel perspective to significantly mitigate catastrophic forgetting in continuous learning (CL), which emphasizes models' capacity to preserve existing knowledge and assimilate new information. Current replay-based methods treat every task and data sample equally and thus can not fully exploit the potential of the replay buffer. In response, we propose COgnitive REplay (CORE), which draws inspiration from human cognitive review processes. CORE includes two key strategies: Adaptive Quantity Allocation and Quality-Focused Data Selection. The former adaptively modulates the replay buffer allocation for each task based on its forgetting rate, while the latter guarantees the inclusion of representative data that best encapsulates the characteristics of each task within the buffer. Our approach achieves an average accuracy of 37.95% on split-CIFAR10, surpassing the best baseline method by 6.52%. Additionally, it significantly enhances the accuracy of the poorest-performing task by 6.30% compared to the top baseline. Code is available at https://github.com/sterzhang/CORE.
4/10/2024

Adaptive Memory Replay for Continual Learning
James Seale Smith, Lazar Valkov, Shaunak Halbe, Vyshnavi Gutta, Rogerio Feris, Zsolt Kira, Leonid Karlinsky
0
0
Foundation Models (FMs) have become the hallmark of modern AI, however, these models are trained on massive data, leading to financially expensive training. Updating FMs as new data becomes available is important, however, can lead to `catastrophic forgetting', where models underperform on tasks related to data sub-populations observed too long ago. This continual learning (CL) phenomenon has been extensively studied, but primarily in a setting where only a small amount of past data can be stored. We advocate for the paradigm where memory is abundant, allowing us to keep all previous data, but computational resources are limited. In this setting, traditional replay-based CL approaches are outperformed by a simple baseline which replays past data selected uniformly at random, indicating that this setting necessitates a new approach. We address this by introducing a framework of adaptive memory replay for continual learning, where sampling of past data is phrased as a multi-armed bandit problem. We utilize Bolzmann sampling to derive a method which dynamically selects past data for training conditioned on the current task, assuming full data access and emphasizing training efficiency. Through extensive evaluations on both vision and language pre-training tasks, we demonstrate the effectiveness of our approach, which maintains high performance while reducing forgetting by up to 10% at no training efficiency cost.
4/22/2024