Mitigating the Stability-Plasticity Dilemma in Adaptive Train Scheduling with Curriculum-Driven Continual DQN Expansion

0
Sign in to get full access
Overview
- Explores a method to balance stability and plasticity in a deep reinforcement learning agent for adaptive train scheduling
- Proposes a curriculum-driven continual DQN expansion approach to mitigate the stability-plasticity dilemma
- Evaluates the approach on a train scheduling simulation environment
Plain English Explanation
The paper explores a challenge in training reinforcement learning agents to adaptively schedule trains. The challenge is the "stability-plasticity dilemma" - the agent needs to be stable (keep what it has learned) but also plastic (able to learn new things).
The researchers propose a novel approach called "curriculum-driven continual DQN expansion" to address this. The key idea is to gradually expand the agent's neural network as it learns, rather than keeping the network fixed. This allows the agent to learn new tasks while retaining knowledge from previous tasks.
The approach is evaluated in a train scheduling simulation environment. The results show the curriculum-driven continual DQN expansion method outperforms traditional reinforcement learning approaches, demonstrating its effectiveness at balancing stability and plasticity.
Technical Explanation
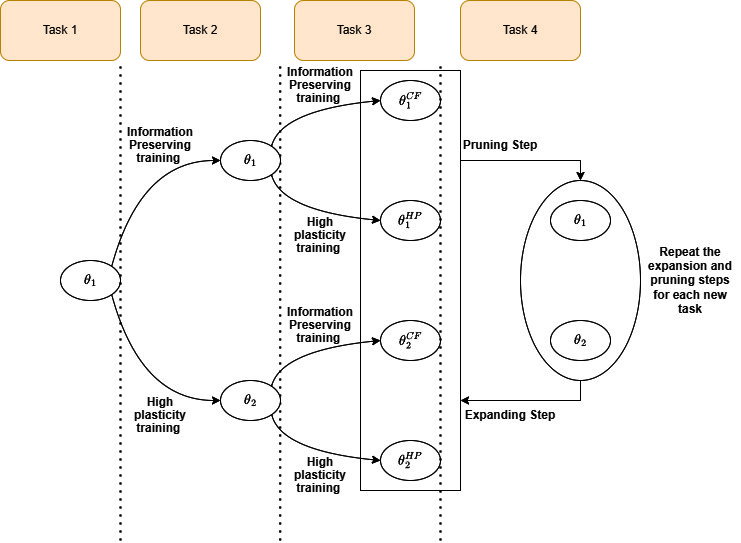
The paper proposes a curriculum-driven continual DQN expansion approach to mitigate the stability-plasticity dilemma in adaptive train scheduling. The core idea is to gradually expand the agent's Deep Q-Network (DQN) architecture as it learns, rather than keeping the network fixed.
This is achieved through a curriculum learning process. The agent first learns on simpler train scheduling tasks, then the network is expanded to handle more complex scenarios as training progresses. The expanded network retains the knowledge gained from previous tasks, allowing the agent to be both stable (retaining past knowledge) and plastic (able to learn new things).
The approach is evaluated in a train scheduling simulation environment, where the agent must learn to dynamically route and schedule trains. Results show the curriculum-driven continual DQN expansion method outperforms baseline DQN and other continual learning approaches, demonstrating its effectiveness at navigating the stability-plasticity trade-off.
Critical Analysis
The paper presents a novel and promising approach to addressing the stability-plasticity dilemma in reinforcement learning. The curriculum-driven continual DQN expansion method is well-motivated and the experimental results are compelling.
However, the paper does not deeply explore the limitations or potential issues with the approach. For example, the curriculum design process and its impact on performance are not thoroughly investigated. Additionally, the training and inference time complexity of the expanded network architecture is not analyzed.
Further research could examine how the curriculum design choices affect learning, as well as the computational and memory costs of the continual expansion approach. Comparisons to other continual learning techniques, such as elastic weight consolidation or joint-training, could also provide additional insights.
Conclusion
This paper presents a curriculum-driven continual DQN expansion method to mitigate the stability-plasticity dilemma in adaptive train scheduling. The approach allows the reinforcement learning agent to gradually expand its neural network architecture as it learns, retaining knowledge from previous tasks while acquiring new capabilities.
The results demonstrate the effectiveness of this technique in a train scheduling simulation environment, outperforming baseline approaches. While the paper does not fully explore the limitations of the method, it offers a promising direction for addressing the fundamental challenge of balancing stability and plasticity in continual learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!